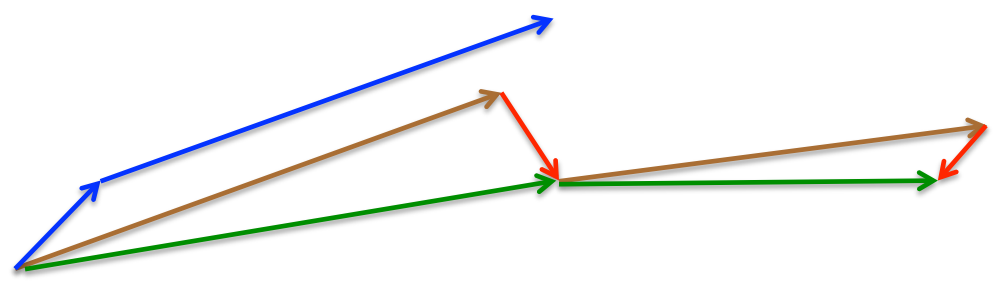
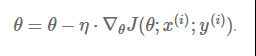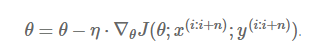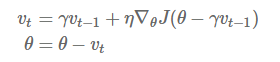An overview of gradient descent optimization algorithms (更新到Adam)
Momentum:解快了收敛速度,同时也减弱了SGD的波动
NAG: 减速了Momentum更新参数太快
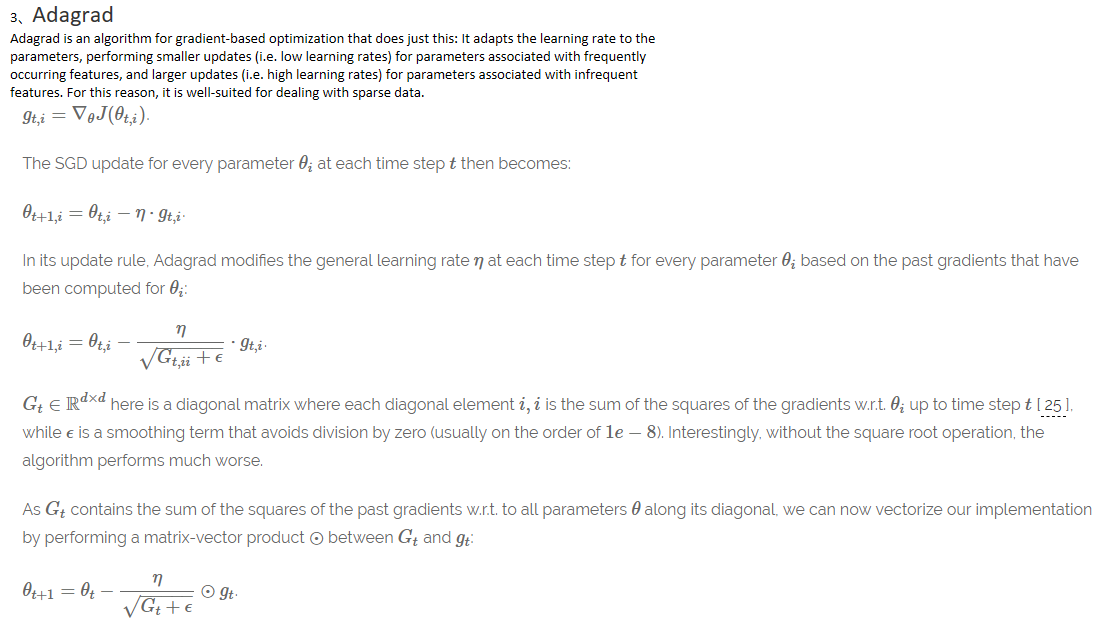
Adagrad: 出现频率较低参数采用较大的更新,对于出现频率较高的参数采用较小的,不共用一个学习率
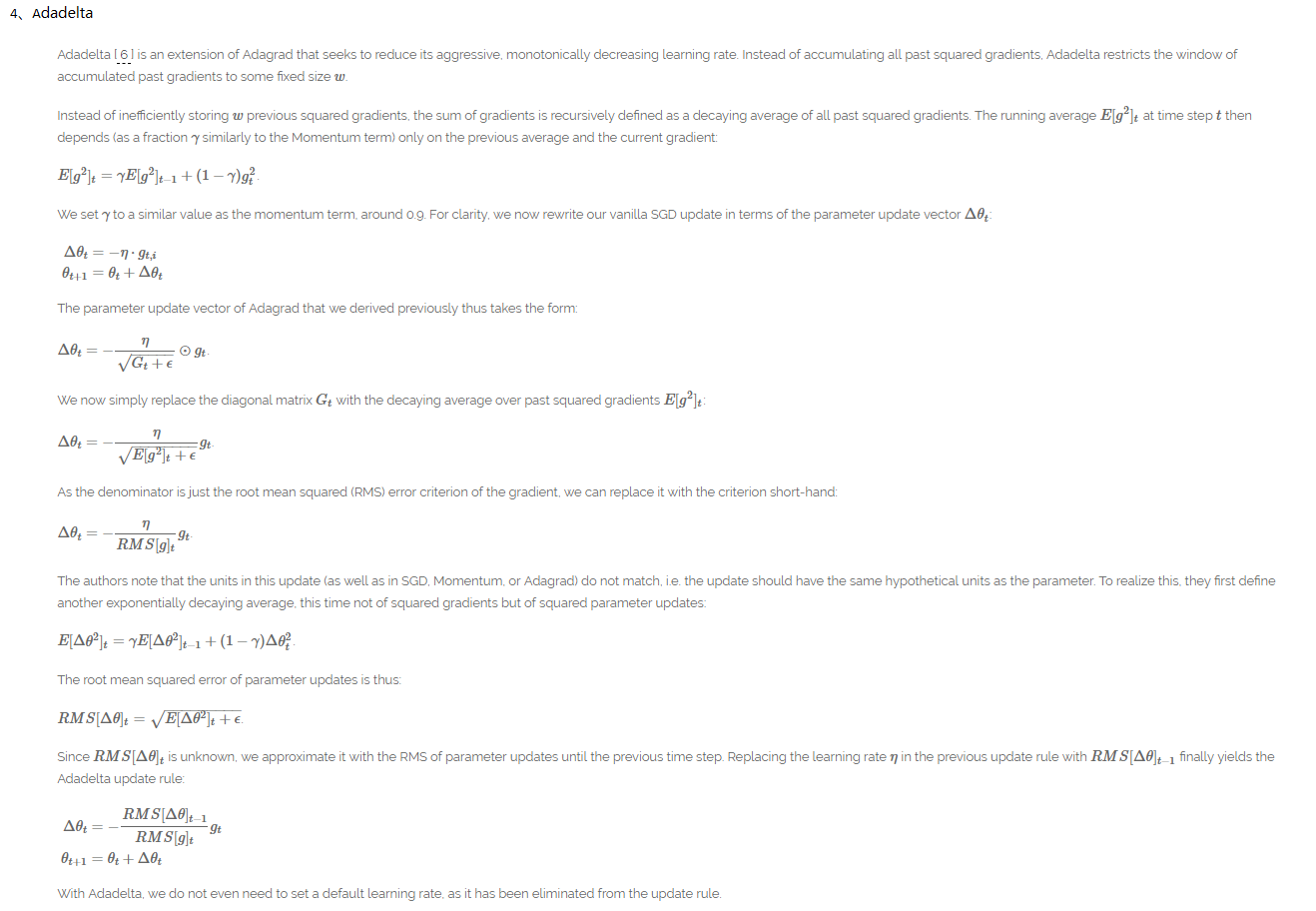
Adadelta:解决了Adagrad后续学习率为0的缺点,同时不要defalut 学习率
RMSprop:解决了Adagrad后续学习率为0的缺点
Adam: 结合了RMSprop和Momentum的优点,Adam might be the best overall choice
参考博客:http://ruder.io/optimizing-gradient-descent/index.html#batchgradientdescent(真大神)