
采样方法-数据不均衡
References :
https://www.cnblogs.com/massquantity/p/9382710.html
https://www.jianshu.com/p/be343414dd24
a. Undersampling.
Say, you have 40,000 positive sample and 2,000 negative samples in your dataset. We will use this as our running example henceforth. What you can do is just randomly pick up 2,000 positive samples out of the 40,000, all 2,000 negative samples, and train and validate your model only on these 4,000 samples. This will allow you to use all the classification algorithms in just the usual way. This method is easy to implement and runs very fast as well. However, one downside is that you are potentially discarding the 38,000 positive sample you have and that data is going down the drain.
To overcome this, you can create an ensemble of models wherein each model uses a different set of 2,000 positive sample and all 2,000 negative samples and is trained and validated separately. Then on your test set, you take a majority vote of all these models. This allows you to take into account all of your data without causing an imbalance. Furthermore, you can even use different algorithms for different sets and then your ensemble would be even more robust. However, this would be a bit computationally expensive.
b. Oversampling
In this method, you generate more samples of your minority class. You can do this either by first creating a generative model and then creating new samples or by just picking existing samples with replacement. There exist a number of oversampling techniques such as SMOTE, ADASYN, etc. You will have to see which works best for your use case. Also, oversampling itself is a computationally expensive procedure. The major advantage is that this allows one model of yours to take all of your data into consideration at once and also helps you generate new data.
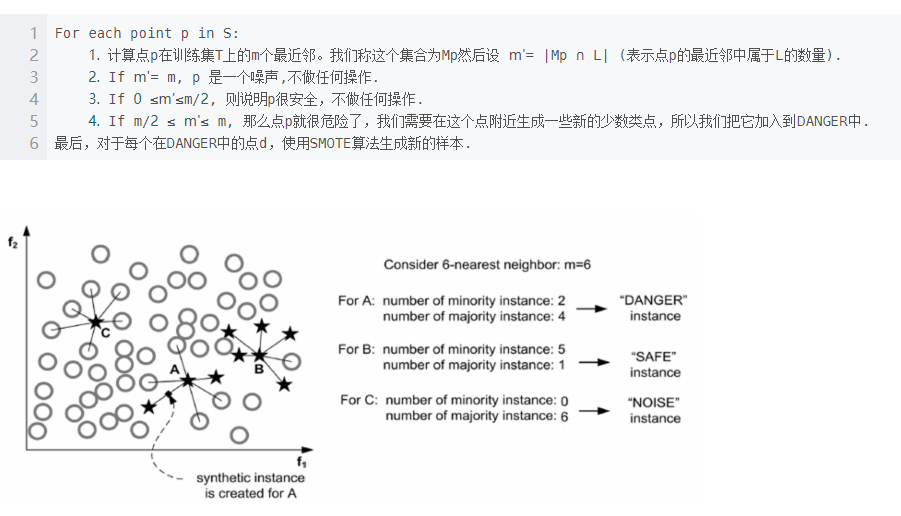
SMOTE 算法(Synthetic Minority Oversampling Technique)

Borderline SMOTE
只考虑 k近邻中有超过一半是多数样本的少数样本(dangerous 点)
ADASYN 算(Adaptive synthetic)



weight balancing
weight balancing to make all classes contribute equally to our loss.
对于多数样本,可以乘以一个小的系数,使得loss变小,对于少数样本,可以乘以一个大的系数,使得loss变大

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步