
bert中的分词
直接把自己的工作文档导入的,由于是在外企工作,所以都是英文写的
chinese and english tokens result
input: "我爱中国",tokens:["我","爱","中","国"]
input: "I love china habih", tokens:["I","love","china","ha","##bi","##h"] (here "##bi","##h" are all in vocabulary)
Implementation
chinese and english text would call two tokens,one is basic_tokenizer and other one is wordpiece_tokenizer as you can see from the the code below.

basic_tokenizer
if the input is chinese, the _tokenize_chinese_chars would add whitespace between chinese charater, and then call whitespace_tokenizer which separate text with whitespace,so
if the input is the query "我爱中国",would return ["我","爱","中","国"],if the input is the english query "I love china", would return ["I","love","china"]

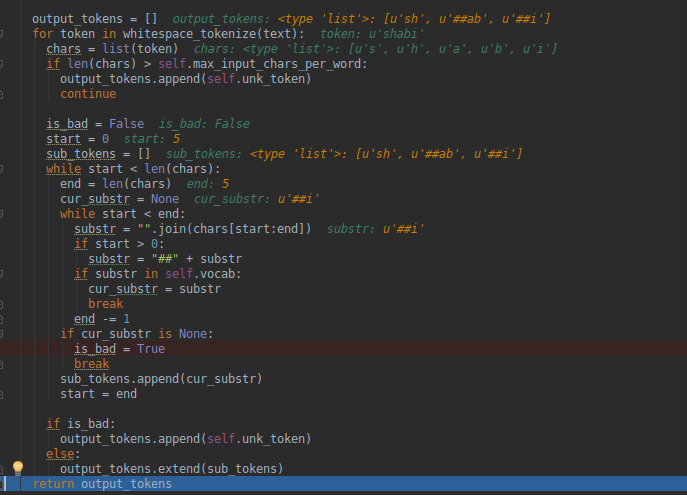
wordpiece_tokenizer
if the input is chinese ,if would iterate tokens from basic_tokenizer result, if the character is in vocabulary, just keep the same character ,otherwise append unk_token.
if the input is english, we would iterate over one word ,for example: the word is "shabi", while it is not in vocabulary,so the end index would rollback until it found "sh" in vocabulary,
in the following process, once it found a substr in vocabulary ,it would append "##" then append it to output tokens, so we can get ["sh","##ab","##i"] finally.
#65 How are out of vocabulary words handled for Chinese?
The top 8000 characters are character-tokenized, other characters are mapped to [UNK]. I should've commented this section better but it's here
Basically that's saying if it tries to apply WordPiece tokenization (the character tokenization happens previously), and it gets to a single character that it can't find, it maps it to unk_token.
#62 Why Chinese vocab contains ##word?
This is the character used to denote WordPieces, it's just an artifact of the WordPiece vocabulary generator that we use, but most of those words were never actually used during training (for Chinese). So you can just ignore those tokens. Note that for the English characters that appear in Chinese text they are actually used.


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux glibc自带哈希表的用例及性能测试
· 深入理解 Mybatis 分库分表执行原理
· 如何打造一个高并发系统?
· .NET Core GC压缩(compact_phase)底层原理浅谈
· 现代计算机视觉入门之:什么是图片特征编码
· 手把手教你在本地部署DeepSeek R1,搭建web-ui ,建议收藏!
· Spring AI + Ollama 实现 deepseek-r1 的API服务和调用
· 数据库服务器 SQL Server 版本升级公告
· C#/.NET/.NET Core技术前沿周刊 | 第 23 期(2025年1.20-1.26)
· 程序员常用高效实用工具推荐,办公效率提升利器!