《流畅的Python》 读书笔记 第8章_对象引用、可变性和垃圾回收
1|0第8章_对象引用、可变性和垃圾回收
本章的主题是对象与对象名称之间的区别。名称不是对象,而是单独的东西
variables are labels, not boxes 变量是标注,而不是盒子
引用式变量的名称解释
本章还会讨论
- 标识、值和别名
- 元组的一个神奇特性:元组是不可变的,但是其中的值可以改变,之后就引申到浅复制和深复制
- 引用和函数参数:可变的参数默认值导致的问题,以及如何安全地处理函数的调用者传入的可变参数
- 垃圾回收、 del 命令,以及如何使用弱引用“记住”对象,而无需对象本身存在
2|08.1 变量不是盒子
Python 变量类似于 Java 中的引用式变量,因此最好把它们理解为附加在对象上的标注
示例 8-1 变量 a 和 b 引用同一个列表,而不是那个列表的副本
可以看到a加了个元素4,b也跟着加了

那朵云上可以贴无数个便利贴
当我们做下面的赋值的时候
我们应该说把变量 s 分配给 seesaw,而不是把 seesaw 分配给变量 s
好像seesaw这个对象杵在那里,s只是指向了它,你完全可以制造其他的变量t也指向它
对引用式变量来说,说把变量分配给对象更合理,反过来说就有问题。毕竟,对象在赋值之前就创建了
示例 8-2 创建对象之后才会把变量分配给对象
上述的例子比较直接的说明了创建对象这点,但像字符串seesaw也是个对象,不是一切皆对象吗
➊ 输出的 Gizmo id: ... 是创建 Gizmo 实例的副作用。
➋ 在乘法运算中使用 Gizmo 实例会抛出异常。
➌ 这里表明,在尝试求积之前其实会创建一个新的 Gizmo 实例。
➍ 但是,肯定不会创建变量 y,因为在对赋值语句的右边进行求值时抛出了异常
为了理解 Python 中的赋值语句,应该始终先读右边。
对象在右边创建或获取,在此之后左边的变量才会绑定到对象上,这就像为对象贴上标注。
忘掉盒子吧!
3|08.2 标识、相等性和别名
因为变量只不过是标注,所以无法阻止为对象贴上多个标注。贴的多个标注,就是别名。
不要跟import pandas as pd这样的别名混淆,只是作者的一个说法而已。
示例 8-3 charles 和 lewis 指代同一个对象
➊ lewis 是 charles 的别名。
➋ is 运算符和 id 函数确认了这一点。
➌ 向 lewis 中添加一个元素相当于向 charles 中添加一个元素。
作者的别名其实是指同一个对象的不同名字,id是一样的,但有多个名字,类似于你的昵称可能有多个,但真实的你就一个。
示例 8-4 alex 与 charles 比较的结果是相等,但 alex 不是 charles
➊ alex 指代的对象与赋值给 charles 的对象内容一样。
➋ 比较两个对象,结果相等,这是因为 dict 类的__eq__方法就是这样实现的。
➌ 但它们是不同的对象。这是 Python 说明标识不同的方式: a is not b
alex 不是 charles 的别名,因为二者绑定的是不同的对象。 alex 和 charles 绑定的对象具有相同的值(== 比较的就是值),但是它们的标识不同。
在官网
https://docs.python.org/zh-cn/3.9/reference/datamodel.html#objects-values-and-types 或
https://docs.python.org/3.9/reference/datamodel.html#objects-values-and-types 有如下描述
对象 ID 的真正意义在不同的实现中有所不同。在 CPython 中, id() 返回对象的内存地址,但是在其他 Python 解释器中可能是别的值。关键是, ID 一定是唯一的数值标注,而且在对象的生命周期中绝不会变
Python解释器版本其实非常多,但经查,像Pypy、Jython等id()的返回值跟CPython是类似的
编程中很少使用 id() 函数。标识最常使用 is 运算符检查,而不是直接比较 ID
3|18.2.1 在==和is之间选择
== 运算符比较两个对象的值(对象中保存的数据),而 is 比较对象的标识。
我们关注的是值,而不是标识,因此 Python 代码中 == 出现的频率比 is 高。
在变量和单例值之间比较时,应该使用 is。
比如跟None来比较的时候,应该用is。
没错,None是个单例值
is 运算符比 == 速度快,因为它不能重载,所以 Python 不用寻找并调用特殊方法,而是直接比较两个整数 ID。
而 a == b 是语法糖,等同于 a.
__eq__(b)。继承自 object 的
__eq__方法比较两个对象的 ID,结果与 is 一样。但是多数内置类型使用更有意义的方式覆盖了
__eq__方法,会考虑对象属性的值。相等性测试可能涉及大量处理工作,例如,比较大型集合或嵌套层级深的结构时。
3|28.2.2 元组的相对不可变性
元组与多数 Python 集合(列表、字典、集,等等)一样,保存的是对象的引用。
如果引用的元素是可变的,即便元组本身不可变,元素依然可变。
也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即保存的引用)不可变,与引用的对象无关
说的大白话一点,元组一旦确定,里面元素的id都不会变,但里面的内容可能会改变。有的同学看了下面的情况会觉得tuple是可变的,关键是它这里的不可变是指id不可变跟我们常规理解的值不可变是两回事。
示例 8-5 一开始, t1 和 t2 相等,但是修改 t1 中的一个可变元素后,二者不相等了
➊ t1 不可变,但是 t1[-1] 可变。
➋ 构建元组 t2,它的元素与 t1 一样。
➌ 虽然 t1 和 t2 是不同的对象,但是二者相等——与预期相符。
➍ 查看 t1[-1] 列表的标识。 与t2[-1]的标识并不相同
➎ 就地修改 t1[-1] 列表。
➏ t1[-1] 的标识没变,只是值变了。
➐ 现在, t1 和 t2 不相等。
从上面的例子可以看出,元组是不可变的,这点没错,但元组不一定是可哈希的,那就意味着元组不一定可以用作dict的key或者set的value。
4|08.3 默认做浅复制
复制列表(或多数内置的可变集合)最简单的方式是使用内置的类型构造方法。比如list() dict() set()
对列表和其他可变序列来说,还能使用简洁的 l2 = l1[:] 语句创建副本 ,也就是上面的第二行替换成l1[:]结果都一样的
构造方法或 [:] 做的是浅复制(即复制了最外层容器,副本中的元素是源容器中元素的引用)。
示例 8-6 为一个包含另一个列表的列表做浅复制;把这段代码复制粘贴到 Python Tutor网站中,看看动画效果
上面的例子又一次提到了不可变对象元组的+=操作是会新建一个元组的这个事实
4|1为任意对象做深复制和浅复制
浅复制没什么问题,但有时我们需要的是深复制(即副本不共享内部对象的引用)。 copy模块提供的 deepcopy 和 copy 函数能为任意对象做深复制和浅复制。
拿上面的例子来说
总结下,看下图
-
类的构造方法list()、切片[:]、copy.copy都是shallow copy(浅拷贝),copy.deepcopy是深拷贝。
-
2种拷贝都是一个新的对象,但对象中的元素如果是列表、元组等,引用的都是同一个
-
深拷贝不同,对象中的元素哪怕是可变的,一样会新建一个对象,不可变的也是引用的同一个
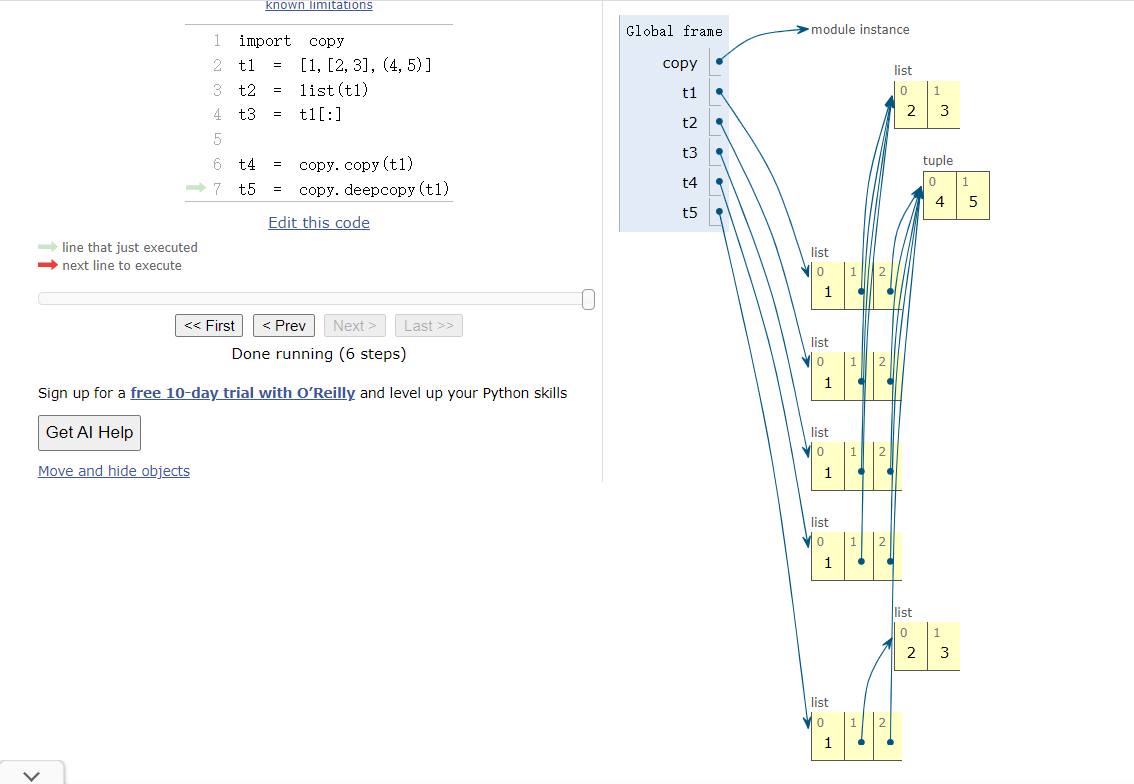
来看另外一个例子,示例 8-8 校车乘客在途中上车和下车
17行的打印可以看到3个bus的id都不一样
19-21行可以看到bus1和bus2是一样的,都是1个人,bus3不受影响仍然2个人
➊ 使用 copy 和 deepcopy,创建 3 个不同的 Bus 实例。
➋ bus1 中的 'Bill' 下车后, bus2 中也没有他了。
➌ 审查 passengers 属性后发现, bus1 和 bus2 共享同一个列表对象,因为 bus2 是 bus1 的浅复制副本。
➍ bus3 是 bus1 的深复制副本,因此它的 passengers 属性指代另一个列表。
一般来说,深复制不是件简单的事。如果对象有循环引用,那么这个朴素的算法会进入无限循环。 deepcopy 函数会记住已经复制的对象,因此能优雅地处理循环引用
示例 8-10 循环引用: b 引用 a,然后追加到 a 中; deepcopy 会想办法复制 a
深复制有时可能太深了。例如,对象可能会引用不该复制的外部资源或单例值。我们可以实现特殊方法
__copy__()和__deepcopy__(),控制 copy 和 deepcopy 的行为
参考: https://docs.python.org/zh-cn/3.9/library/copy.html
5|08.4 函数的参数作为引用时
Python 唯一支持的参数传递模式是共享传参(call by sharing)。多数面向对象语言都采用这一模式,包括 Ruby、 Smalltalk 和 Java(Java 的引用类型是这样,基本类型按值传参)。
共享传参指函数的各个形式参数获得实参中各个引用的副本。也就是说,函数内部的形参是实参的别名
这种方案的结果是,函数可能会修改作为参数传入的可变对象,但是无法修改那些对象的标识(即不能把一个对象替换成另一个对象)
示例 8-11 函数可能会修改接收到的任何可变对象
从结果看,数字、元组不变,但列表变了(好像是另外一种可变性的解释)
5|18.4.1 不要使用可变类型作为参数的默认值
可选参数可以有默认值,这是 Python 函数定义的一个很棒的特性,这样我们的 API 在进化的同时能保证向后兼容
举个例子
示例 8-12 一个简单的类,说明可变默认值的危险
➊ 如果没传入 passengers 参数,使用默认绑定的列表对象,一开始是空列表。
➋ 这个赋值语句把 self.passengers 变成 passengers 的别名,而没有传入 passengers 参数时,后者又是默认列表的别名。
➌ 在 self.passengers 上调用 .remove() 和 .append() 方法时,修改的其实是默认列表,它是函数对象的一个属性
在Pycharm中写这个,passengers=[]会这样给你点警告,点击替换可变默认实参

就能变成这样
这跟示例8-8几乎没啥差别了
回到正题,示例 8-12中,来看看会发生什么诡异的事情
从12行开始,bus3应该是没有乘客,结果也有一个Allison,好像是被bus2影响了
第13行,bus3加了个Dave导致bus2也有了这个乘客
第16行发现,bus2和bus3的乘客是同一个对象
实例化 HauntedBus 时,如果传入乘客,会按预期运作。
但不为 HauntedBus 指定乘客的话,奇怪的事发生了,这是因为 self.passengers 变成了 passengers 参数默认值的别名。
出现这个问题的根源是,默认值在定义函数时计算(通常在加载模块时),因此默认值变成了函数对象的属性。
因此,如果默认值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。
这个默认值藏在HauntedBus.__init__ 对 象 __defaults__ 属性中
还可以验证 bus2.passengers 是一个别名,它绑定到 HauntedBus.__init__.__defaults__ 属性的第一个元素上:
可变默认值导致的这个问题说明了为什么通常使用 None 作为接收可变值的参数的默认值
5|28.4.2 防御可变参数
如果定义的函数接收可变参数,应该谨慎考虑调用方是否期望修改传入的参数。
例如,如果函数接收一个字典,而且在处理的过程中要修改它,那么这个副作用要不要体现到函数外部?具体情况具体分析。这其实需要函数的编写者和调用方达成共识。
举个很简单的例子
示例 8-15 一个简单的类,说明接受可变参数的风险
➊ 这里谨慎处理,当 passengers 为 None 时,创建一个新的空列表。
➋ 然而,这个赋值语句把 self.passengers 变成 passengers 的别名,而后者是传给__init__方法的实参(即示例 8-14 中的 basketball_team)的别名。
➌ 在 self.passengers 上调用 .remove() 和 .append() 方法其实会修改传给构造方法的那个列表。
来看看执行的效果
你会发现,篮球队的人被公交车给drop了,这就离谱
TwilightBus 违反了设计接口的最佳实践,即“最少惊讶原则” Principle of least astonishment
所以问题 出在哪里呢?
校车为传给构造方法的列表创建了别名 (前面已经说了)
那么正确的做法是,校车自己维护乘客列表
很多人能理解变量的浅拷贝,深拷贝,到放到类这里感觉就是另外回事了,其实道理是相通的
在内部像这样处理乘客列表,就不会影响初始化校车时传入的参数了。
此外,这种处理方式还更灵活:现在,传给 passengers 参数的值可以是元组或任何其他可迭代对象,例如set 对象,甚至数据库查询结果,因为 list 构造方法接受任何可迭代对象
作者的建议是
除非这个方法确实想修改通过参数传入的对象,否则在类中直接把参数赋值给实例变量之前一定要三思,因为这样会为参数对象创建别名。
如果不确定,那就创建副本。这样客户会少些麻烦。
6|08.5 del和垃圾回收
对象绝不会自行销毁;然而,无法得到对象时,可能会被当作垃圾回收
--- Python 语言参考手册中“Data Model”
del 语句删除名称,而不是对象。
del 命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。 重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
示例 8-16 没有指向对象的引用时,监视对象生命结束时的情形
➊ s1 和 s2 是别名,指向同一个集合, {1, 2, 3}。
➋ 这个函数一定不能是要销毁的对象的绑定方法,否则会有一个指向对象的引用。
➌ 在 s1 引用的对象上注册 bye 回调。
➍ 调用 finalize 对象之前, .alive 属性的值为 True。
➎ 如前所述, del 不删除对象,而是删除对象的引用。
➏ 重新绑定最后一个引用 s2,让 {1, 2, 3} 无法获取。对象被销毁了,调用了 bye 回调,ender.alive 的值变成了 False
示例输出
有个
__del__特殊方法,但是它不会销毁实例,不应该在代码中调用。即将销毁实例时, Python 解释器会调用__del__方法,给实例最后的机会,释放外部资源。
所以,记住一点del跟__del__没有关系
https://www.bilibili.com/video/BV1b84y1e7hG
码农高天对魔术方法做了系列的视频,不懂的可以前往
他认为__del__粗略的认为是析构函数,__del__发生在对象释放时,但对象的释放可能发生在引用为0,可能是gc,这个函数就不太可控,不建议使用
在 CPython 中,垃圾回收使用的主要算法是引用计数。
实际上,每个对象都会统计有多少引用指向自己。当引用计数归零时,对象立即就被销毁: CPython 会在对象上调用
__del__方法(如果定义了),然后释放分配给对象的内存。CPython 2.0 增加了分代垃圾回收算法,用于检测引用循环中涉及的对象组——如果一组对象之间全是相互引用,即使再出色的引用方式也会导致组中的对象不可获取。
Python 的其他实现有更复杂的垃圾回收程序,而且不依赖引用计数,这意味着,对象的引用数量为零时可能不会立即调用
__del__方法。A.Jesse Jiryu Davis 写的“PyPy, Garbage Collection, and a Deadlock”一文(https://emptysqua.re/blog/pypy-garbage-collection-and-a-deadlock/)对
__del__方法的恰当用法和不当用法做了讨论。
7|08.6 弱引用
正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。
但是,有时需要引用对象,而不让对象存在的时间超过所需时间。这经常用在缓存中。
弱引用不会增加对象的引用数量。引用的目标对象称为所指对象(referent)。因此我们说,弱引用不会妨碍所指对象被当作垃圾回收。
弱引用在缓存应用中很有用,因为我们不想仅因为被缓存引用着而始终保存缓存对象
示例 8-17 弱引用是可调用的对象,返回的是被引用的对象;如果所指对象不存在了,返回 None
➊ 创建弱引用对象 wref,下一行审查它。
➋ 调用 wref() 返回的是被引用的对象, {0, 1}。因为这是控制台会话,所以 {0, 1} 会绑定给 _ 变量。
➌ a_set 不再指代 {0, 1} 集合,因此集合的引用数量减少了。但是 _ 变量仍然指代它。
➍ 调用 wref() 依旧返回 {0, 1}。
➎ 计算这个表达式时, {0, 1} 存在,因此 wref() 不是 None。但是,随后 _ 绑定到结果值False。现在 {0, 1} 没有强引用了。
➏ 因为 {0, 1} 对象不存在了,所以 wref() 返回 None。
这里有个非常重要的前置
在IDLE控制台会话中, Python 控制台会自动把 _ 变量绑定到结果不为None 的表达式结果上
weakref 模块的文档(http://docs.python.org/3/library/weakref.html)指出, weakref.ref 类其实是低层接口,供高级用途使用,多数程序最好使用 weakref 集合和 finalize。
也就是说,应该使用 WeakKeyDictionary、 WeakValueDictionary、 WeakSet 和 finalize(在内部使用弱引用),不要自己动手创建并处理 weakref.ref 实例
7|18.6.1 WeakValueDictionary简介
WeakValueDictionary 类实现的是一种可变映射,里面的值是对象的弱引用。被引用的对象在程序中的其他地方被当作垃圾回收后,对应的键会自动从 WeakValueDictionary 中删除。因此, WeakValueDictionary 经常用于缓存
示例 8-19 顾客:“你们店里到底有没有奶酪?
➊ stock 是 WeakValueDictionary 实例。
➋ stock 把奶酪的名称映射到 catalog 中 Cheese 实例的弱引用上。
➌ stock 是完整的。
➍ 删除 catalog 之后, stock 中的大多数奶酪都不见了,这是 WeakValueDictionary 的预期行为。为什么不是全部呢?
临时变量引用了对象,这可能会导致该变量的存在时间比预期长。通常,这对局部变量来说不是问题,因为它们在函数返回时会被销毁。但是在示例 8-19中, for 循环中的变量 cheese 是全局变量,除非显式删除,否则不会消失
当然你应该知道for之后cheese是catalog中的最后一个值
与 WeakValueDictionary 对 应 的 是 WeakKeyDictionary, 后 者 的 键 是 弱 引 用
可能的用途:WeakKeyDictionary 实例)可以为应用中其他部分拥有的对象附加数据,这样就无需为对象添加属性。这对覆盖属性访问权限的对象尤其有用
weakref 模块还提供了 WeakSet 类,按照文档的说明,这个类的作用很简单:“保存元素弱引用的集合类。元素没有强引用时,集合会把它删除。”如果一个类需要知道所有实例,一种好的方案是创建一个 WeakSet 类型的类属性,保存实例的引用。如果使用常规的 set,实例永远不会被垃圾回收,因为类中有实例的强引用,而类存在的时间与 Python 进程一样长,除非显式删除类
示例代码
7|28.6.2 弱引用的局限
并非所有对象都可以被弱引用。支持弱引用的对象包括类实例、用 Python(而非用 C)编写的函数、实例方法、集合、冻结集合、某些 文件对象、生成器、类型对象、套接字、数组、双端队列、正则表达式模式对象以及代码对象。
一些内置类型,如 list 和 dict,不直接支持弱引用,但可以通过子类化添加支持:(自测了下str也支持子类化添加)
CPython 实现细节: 其他内置类型,如 tuple 和 int,不支持弱引用,即使通过子类化也不支持。
8|08.7 Python对不可变类型施加的把戏
对元组 t 来说, t[:] 不创建副本,而是返回同一个对象的引用。此外,tuple(t) 获得的也是同一个元组的引用。
示例 8-20 使用另一个元组构建元组,得到的其实是同一个元组
str、 bytes 和 frozenset 实例也有这种行为。注意, frozenset 实例不是序列,因此不能使用 fs[:](fs 是一个 frozenset 实例)。但是, fs.copy() 具有相同的效果:它会欺骗你,返回同一个对象的引用,而不是创建一个副本,
对元组也是这样的
示例 8-21 字符串字面量可能会创建共享的对象
共享字符串字面量是一种优化措施,称为驻留(interning)。 CPython 还会在小的整数上使用这个优化措施,防止重复创建“热门”数字,如 0、 —1 和 42。注意, CPython 不会驻留所有字符串和整数,驻留的条件是实现细节,而且没有文档说明
为避免因创建相同的值而频繁申请和回收内存空间带来的效率问题,Python 解释器会在启动时创建一个范围为 *[-5, 256]* 的 小整数池,该范围内预定义的“小”整数对象将在全局解释器范围内被重复使用,而不会被垃圾回收机制回收
千万不要依赖字符串或整数的驻留!比较字符串或整数是否相等时,应该使用 ==,而不是 is。驻留是 Python 解释器内部使用的一个特性。
frozenset.copy() 的行为,是“善意的谎言”,能节省内存,提升解释器的速度。别担心,它们不会为你带来任何麻烦,因为只有不可变类型会受到影响
9|08.8 本章小结
每个 Python 对象都有标识、类型和值。只有对象的值会不时变化。
如果两个变量指代的不可变对象具有相同的值(a == b 为 True),实际上它们指代的是副本还是同一个对象的别名基本没什么关系,因为不可变对象的值不会变,但有一个例外。
这里说的例外是不可变的集合,如元组和 frozenset:如果不可变集合保存的是可变元素的引用,那么可变元素的值发生变化后,不可变集合也会随之改变。实际上,这种情况不是很常见。不可变集合不变的是所含对象的标识。
变量保存的是引用,这一点对 Python 编程有很多实际的影响。
- 简单的赋值不创建副本。
- 对 += 或 *= 所做的增量赋值来说,如果左边的变量绑定的是不可变对象,会创建新对象;如果是可变对象,会就地修改。
- 为现有的变量赋予新值,不会修改之前绑定的变量。这叫重新绑定:现在变量绑定了其他对象。如果变量是之前那个对象的最后一个引用,对象会被当作垃圾回收。
- 函数的参数以别名的形式传递,这意味着,函数可能会修改通过参数传入的可变对象。这一行为无法避免,除非在本地创建副本,或者使用不可变对象(例如,传入元组,而不传入列表)。
- 使用可变类型作为函数参数的默认值有危险,因为如果就地修改了参数,默认值也就变了,这会影响以后使用默认值的调用。
在 CPython 中,对象的引用数量归零后,对象会被立即销毁。如果除了循环引用之外没有其他引用,两个对象都会被销毁。某些情况下,可能需要保存对象的引用,但不留存对象本身。例如,有一个类想要记录所有实例。这个需求可以使用弱引用实现,这是一种低层机制,是 weakref 模块中 WeakValueDictionary、 WeakKeyDictionary 和 WeakSet 等有用的集合类,以及 finalize 函数的底层支持。
10|08.9 延伸阅读
| 素材 | URL | 相关信息 |
|---|---|---|
| Python 语言参考手册中“Data Model”一章 | https://docs.python.org/3/reference/datamodel.html | 清楚解释对象标识和值 |
| Python 103: Memory Model & Best Practices | http://conferences.oreilly.com/oscon/oscon2013/public/schedule/detail/29374 | |
| EuroPython 2011 | https://www.youtube.com/watch?v=HHFCFJSPWrI) | 涵盖了本章的主题,还讨论了特殊方法的使用 |
| Python Module of the Week | http://pymotw.com | |
| http://pymotw.com/3/copy/ | copy – Duplicate Objects | |
| http://pymotw.com/3/weakref | weakref – Garbage-Collectable References to Objects | |
| 关于 CPython 分代垃圾回收程序的更多信息 | https://docs.python.org/3/library/gc.html | gc 模块的文档 |
| How Does Python Manage Memory | http://effbot.org/pyfaq/how-does-python-manage-memory.htm | 谈论了 Python 的垃圾回收程序 |
| PEP 442—Safe object finalization | https://www.python.org/dev/peps/pep-0442/ | |
| 字符串驻留 | https://en.wikipedia.org/wiki/String_interning | |
| Python Garbage Collector Implementations: CPython, PyPy and GaS | https://thp.io/2012/python-gc/python_gc_final_2012-01-22.pdf | CPython 中 open().write() 是安全的 |
| 程序设计语言——实践之路(第 3版) 8.3.1 节“参数模式” |
-
Jython 用的是 Java 垃圾回收程序
-
GC模块为可选的垃圾回收程序提供接口
垃圾回收可以延缓实现,或者完全不实现——如何实现垃圾回收是实现的质量问题,
只要不把还能获得的对象给回收了就行
10|1杂谈
平等对待所有对象
JAVA中== 运算符 比较的是对象(不是基本类型)的引用,而不是对象的值 。
Python = 运算符比较对象的值,而 is 比较引 用。
此外, Python支持重载运算符, == 能正确处理标准库中的所有对象,包括 None——这是一个正常的对象,与 Java 的 null 不同
当然,你可以在自己的类中定义 __eq__ 方法,决定 == 如何比较实例
可变性
处理不可变的对象时,变量保存的是真正的对象还是共享对象的引用无关紧要
如果 a == b 成立,而且两个对象都不会变,那么它们就可能是相同的对象。这就是为什么字符串可以安全使用驻留。仅当对象可变时,对象标识才重要
在 Python 中,用户定义的类,其实例默认可变(多数面向对象语言都是如此)。自己创建对象时,如果需
要不可变的对象,一定要格外小心。此时,对象的每个属性都必须是不可变的,否则会出现类似元组那种行为:元组本身不可变,但是如果里面保存着可变对象,那么元组的值可能会变
可变对象还是导致多线程编程难以处理的主要原因,因为某个线程改动对象后,如果不正确地同步,那就会损坏数据。但是过度同步又会导致死锁
对象析构和垃圾回收
Python 没有直接销毁对象的机制
CPython 中的垃圾回收主要依靠引用计数 ,但是遇到引用循环容易泄露内存,因此 CPython 2.0(2000 年 10 月发布)实现了分代垃圾回收程序,它能把引用循环中不可获取的对象销毁
但是引用计数仍然作为一种基准存在,一旦引用数量归零,就立即销毁对象
open('test.txt', 'wt', encoding='utf-8').write('1, 2, 3') 是安全的,因为文件对象的引用数量会在 write 方法返回后归零, Python在销毁内存中表示文件的对象之前,会立即关闭文件 。然而,这行代码在 Jython 或IronPython 中却不安全,因为它们使用的是宿主运行时(Java VM 和 .NET CLR)中的垃圾回收程序,那些回收程序更复杂,但是不依靠引用计数,而且销毁对象和关闭文件的时间可能更长。
参数传递: 共享传参
在 Python中,函数得到参数的副本,但是参数始终是引用。因此,如果参数引用的是可变对象,那么对象可能会被修改,但是对象的标识不变 。
因为函数得到的是参数引用的副本,所以重新绑定对函数外部没有影响
10|2引用计数-sys.getrefcount
注意调用getrefcount()函数会临时增加一次引用计数,得到的结果比预期的多一次
由于list对象被作为参数传给 getrefcount 函数,它在函数执行过程中作为函数的局部变量存在,因此又多了一个引用
10|3字符串的驻留
驻留机制
- 优点:创建新字符串对象时,会先在于内存 (缓存池) 中查找是否已存在具有相同值的对象 (Python 标识符 - 只含数字、字母、下划线的字符)。若存在,则直接引用之,以避免频繁创建和回收内存,从而提升效率
- 缺点:在拼接等需要改动字符串时会极大地影响性能,因为 Python 字符串作为不可变对象,对字符串的改动 (主要是拼接) 不是原地操作 (in-place),而是会开辟新的内存空间来创建新的对象。这也是使用 + 拼接字符串的效率十分低下而不建议使用的原因。 (还不如 join() - 先计算出全部字符串的长度,再一 一拷贝,仅创建一次对象)
__EOF__

本文链接:https://www.cnblogs.com/wuxianfeng023/p/17836582.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2022-11-16 (转载)敏捷团队的质量保障赋能