《流畅的Python》 读书笔记 第三章字典和集合 20231017
1|0第3章 字典和集合
dict 类型是 Python 语言的基石
模块的命名空间、实例的属性和函数的关键字参数中都可以看到字典的身影
跟它有关的内置函数都在
__builtins__.__dict__模块中
模块的命名空间: 我的理解是sys.modules
实例的属性: 我的理解是实例.__dict__
函数的关键字参数: 这样理解?
最后的__builtins__.__dict__没法看,不如dir(__builtins__)来的直观
Python 对字典的实现,还要集合也是,做了高度优化,而散列表则是字典类型性能出众的根本原因
散列表:hashtable
2|03.1 泛映射类型
这个章节在第二版中挪到了第四节
collections.abc 模块中有 Mapping 和 MutableMapping 这两个抽象基类,它们的作用是为dict 和其他类似的类型定义形式接口
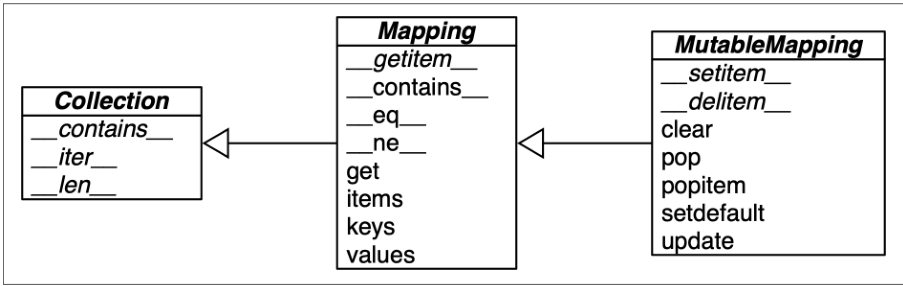
标准库里的所有映射类型都是利用 dict 来实现的,因此它们有个共同的限制,即只有可散列
的数据类型才能用作这些映射里的键(只有键有这个要求,值并不需要是可散列的数据类型)
关于可散列,在Python官网的翻译是可哈希
https://docs.python.org/zh-cn/3/glossary.html#term-hashable
hashable -- 可哈希
一个对象的哈希值如果在其生命周期内绝不改变,就被称为 可哈希 (它需要具有
__hash__()方法),并可以同其他对象进行比较(它需要具有__eq__()方法)。可哈希对象必须具有相同的哈希值比较结果才会相同。可哈希性使得对象能够作为字典键或集合成员使用,因为这些数据结构要在内部使用哈希值。
大多数 Python 中的不可变内置对象都是可哈希的;可变容器(例如列表或字典)都不可哈希;不可变容器(例如元组和 frozenset)仅当它们的元素均为可哈希时才是可哈希的。 用户定义类的实例对象默认是可哈希的。 它们在比较时一定不相同(除非是与自己比较),它们的哈希值的生成是基于它们的
id()。
注意"大多数 Python 中的不可变内置对象都是可哈希的"这句话,以前是没有"大多数"的修饰的,以前是所有。
那就不够准确了
比如虽然元组本身是不可变序列,它里面的元素可能是其他可变类型的引用
以前在给人介绍的时候,我也总说 可哈希=不可变,可变=不可哈希,看来也不严谨
另外__hash__和__eq__有了也不能说明啥,list一样有,但是不可哈希的
一般来讲用户自定义的类型的对象都是可散列的,散列值就是它们的 id() 函数的返回值
这句话在现在的Python中应该不对了,Python官方文档这么描述的
测试代码
2个返回值并不一致,也就是所说的基于id()而非就是id()
要去检测一个对象是否是可哈希的,好像只能这样,并无现成的可以用
https://docs.python.org/3/library/stdtypes.html#mapping-types-dict
说明了字典创建的多种方式(e、f这2种方式感觉没意思),不包括3.2的字典推导
3|03.2 现代字典语法
3.2.1 字典推导 dict Comprehensions
简写为dict comp,可以从任何以键值对作为元素的可迭代对象中构建出字典
➊ 一个承载成对数据的列表,它可以直接用在字典的构造方法中。
➋ 这里把配好对的数据左右换了下,国家名是键,区域码是值。
➌ 跟上面相反,用区域码作为键,国家名称转换为大写,并且过滤掉区域码大于或等于66 的地区
3.2.2 Unpacking Mappings
详见:https://peps.python.org/pep-0448/
用在函数调用
用在字典的字面量上
3.2.3 字典合并
3.9开始支持|和|=来合并字典
3.2.4 Pattern Matching with Mappings
这部分是第二版才有的
match/case在Python3.10中开始支持,case部分可以用mapping来做pattern
详细可以参考: https://peps.python.org/pep-0636/
官网 https://docs.python.org/zh-cn/3.10/whatsnew/3.10.html#pep-634-structural-pattern-matching 借鉴了PEP
书中的示例如下:
- Match any mapping with 'type': 'book', 'api' :2, and an 'authors' key mapped to a sequence. Return the items in the sequence, as a new list.
- Match any mapping with 'type': 'book', 'api' :1, and an 'author' key mapped to any object. Return the object inside a list.
- Any other mapping with 'type': 'book' is invalid, raise ValueError.
- Match any mapping with 'type': 'movie' and a 'director' key mapped to a single object. Return the object inside a list.
- Any other subject is invalid, raise ValueError
尤其要注意上面示例中name/names的用法,跟一般的定义的差别
4|03.3 常见的映射方法
| 方法 | dict | defaultdict | orderdict | 说明 |
|---|---|---|---|---|
| d.clear() | Y | Y | Y | 移除所有元素 |
d.__contains__(k) |
Y | Y | Y | 检查 k 是否在 d 中 |
| d.copy() | Y | Y | Y | 浅复制 |
d.__copy__() |
Y | N | N | 用于支持 copy.copy |
| d.default_factory | Y | N | N | 在 missing 函数中被调用的函数,用以给未找到的元素设置值 * |
d.__delitem__(k) |
Y | Y | Y | del d[k],移除键为 k 的元素 |
| d.fromkeys(it, [initial]) | Y | Y | Y | 将迭代器 it 里的元素设置为映射里的键,如果有 initial 参数,就把它作为这些键对应的值(默认是 None) |
| d.get(k, [default]) | Y | Y | Y | 返回键 k 对应的值,如果字典里没有键k,则返回 None 或者 default |
d.__getitem__(k) |
Y | Y | Y | 让字典 d 能用 d[k] 的形式返回键 k 对应的值 |
| d.items() | Y | Y | Y | 返回 d 里所有的键值对 |
d.__iter__() |
Y | Y | Y | 获取键的迭代器 |
| d.keys() | Y | Y | Y | 获取所有的键 |
d.__len__() |
Y | Y | Y | 可以用 len(d) 的形式得到字典里键值对的数量 |
d.__missing__(k) |
Y | N | N | 当 getitem 找不到对应键的时候,这个方法会被调用 |
| d.move_to_end(k, [last]) | Y | N | N | 把键为 k 的元素移动到最靠前或者最靠后的位置(last 的默认值是 True) |
| d.pop(k, [defaul] | Y | Y | Y | 返回键 k 所对应的值,然后移除这个键值对。如果没有这个键,返回 None 或者defaul |
| d.popitem() | Y | Y | Y | 随机返回一个键值对并从字典里移除它 # |
d.__reversed__() |
Y | N | N | 返回倒序的键的迭代器 |
| d.setdefault(k, [default]) | Y | Y | Y | 若字典里有键 k,则直接返回 k 所对应的值;若无,则让 d[k] = default,然后返回 |
d.__setitem__(k, v) |
Y | Y | Y | 实现 d[k] = v 操作,把 k 对应的值设为 v |
| d.update(m, [**kargs]) | Y | Y | Y | m 可以是映射或者键值对迭代器,用来更新 d 里对应的条目 |
| d.values() | Y | Y | Y | 返回字典里的所有值 |
default_factory 并不是一个方法,而是一个可调用对象(callable),它的值在 defaultdict 初始化的时候由用户设定
OrderedDict.popitem() 会移除字典里最先插入的元素(先进先出);同时这个方法还有一个可选的 last参数,若为真,则会移除最后插入的元素(后进先出)
update 方法处理参数 m 的方式,是典型的“鸭子类型”。函数首先检查 m是否有 keys 方法,如果有,那么 update 函数就把它当作映射对象来处理。否则,函数会退一步,转而把 m 当作包含了键值对 (key, value) 元素的迭代器。
setdefault 一旦它发挥作用,就可以节省不少次键查询,从而让程序更高效
3.3.1 用setdefault处理找不到的键
下文的zen.txt来自import this的输出,手工保存下即可测试
➊ 提取 word 出现的情况,如果还没有它的记录,返回 []。
➋ 把单词新出现的位置添加到列表的后面。
➌ 把新的列表放回字典中,这又牵扯到一次查询操作。
➍ sorted 函数的 key= 参数没有调用 str.upper,而是把这个方法的引用传递给 sorted 函数,这样在排序的时候,单词会被规范成统一格式
除了官方的解释,我也说几句
- enumerate(fp, 1) 对一个iterable做枚举,start=1,默认是0,但由于要统计行号,所以就从1开始了
- WORD_RE.finditermatch是一个Match对象构成的iterable,遍历后得到的是每一行line符合正则pattern的各个部分,通过.group获取信息
- match.start()是匹配到的单词的索引位置,默认是从0开始,所以也要+1
输出类似如下
修改后的代码
注意这一行和三行的转换
事实上
等价于
再次看下setdefault(k,default)的作用:若字典里有键 k,则直接返回 k 所对应的值;若无,则让 d[k] = default,然后返回,他这里利用到了技巧my_dict.setdefault(key, [])返回的要么是key的value,要么就是[],空的[]是用来首次使用。
哪怕我看的懂,以后我同样的场景我也很难想得到来用这个方法。
但效率的确是大幅提升了
后者至少要进行两次键查询——如果键不存在的话,就是三次,用 setdefault 只需要一次就可以完成整个操作
有人说从描述看setdefault 和get似乎没有啥区别
但是get如果没有得到key,那默认值[]虽然被你用到了,但dict本身可没有变化
但setdefault 就完全不同了,他会设置key的值的,你必须清楚这点。
5|03.4 映射的弹性键查询
有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的,一个是通过 defaultdict 这个类型而不是普通的 dict,另一个是给自己定义一个 dict 的子类,然后在子类中实现
__missing__方法
注意不是get和setdefault的用途,这是有区别的
5|13.4.1 defaultdict:处理找不到的键的一个选择
在实例化一个 defaultdict 的时候,需要给构造方法提供一个可调用对象,这个可调用对象会在 getitem 碰到找不到的键的时候被调用,让 getitem 返回某种默认值
dd = defaultdict(list),如果键 'new-key' 在 dd 中还不存在的话,表达式 dd['new-key'] 会按照以下的步骤来行事。
(1) 调用 list() 来建立一个新列表。
(2) 把这个新列表作为值,'new-key' 作为它的键,放到 dd 中。
(3) 返回这个列表的引用
但要注意,只能用[],用get可不行
这是因为
defaultdict 里的 default_factory 只会在 getitem 里被调用,在其他的方法里完全不会发挥作用
有了它,那前面的代码就有了新的写法
➊ 把 list 构造方法作为 default_factory 来创建一个 defaultdict。
➋ 如果 index 并没有 word 的记录,那么 default_factory 会被调用,为查询不到的键创造一个值。这个值在这里是一个空的列表,然后这个空列表被赋值给 index[word],继而被当作返回值返回,因此 .append(location) 操作总能成功
如 果 在 创 建 defaultdict 的 时 候 没 有 指 定 default_factory, 查 询 不 存 在 的 键 会 触 发KeyError
5|23.4.2 特殊方法__missing__
所有(承上)这一切背后的功臣其实是特殊方法
__missing__。它会在 defaultdict 遇到找不到的键的时候调用 default_factory,而实际上这个特性是所有映射类型都可以选择去支持的
基类 dict 并没有定义这个方法,但是 dict 是知道有这么个东西存在的。也就是说,如果有一个类继承了 dict,然后这个继承类提供了
__missing__方法,那么在__getitem__碰到找不到的键的时候,Python 就会自动调用它,而不是抛出一个KeyError 异常。
__missing__方法只会被__getitem__调用(比如在表达式 d[k] 中)
有时候,你会希望在查询的时候,映射类型里的键统统转换成 str
书中给出的示例代码 3-7
➊ StrKeyDict0 继承了 dict。
➋ 如果找不到的键本身就是字符串,那就抛出 KeyError 异常。
➌ 如果找不到的键不是字符串,那么把它转换成字符串再进行查找。
➍ get 方法把查找工作用 self[key] 的形式委托给 __getitem__, 这样在宣布查找失败之前,还能通过 __missing__ 再给某个键一个机会。
➎ 如果抛出 KeyError,那么说明__missing__也失败了,于是返回 default。
➏ 先按照传入键的原本的值来查找(我们的映射类型中可能含有非字符串的键),如果没找到,再用 str() 方法把键转换成字符串再查找一次
另外注意几点
- line22会打印2次missing
- dict的get正常是不会处理missing的,此处重写了,调用的[],所以才会
- in的背后有
__contains__
如 果 要 自 定 义 一 个 映 射 类 型, 更 合 适 的 策 略 其 实 是 继 承 collections.UserDict 类
isinstance(key, str) 测试在上面的
__missing__中是必需的
如果没有?你可以思考下,会是怎样?
答案是:如果key或str(key)不存在,无论你是get还是[],代码就死循环了。
其实逻辑很简单,因为__missing__中调用了self[str(key)],如果不存在又走到__missing__,你必须要给一个退出条件,也就是此处的if + raise
为了保持一致性,
__contains__方法在这里也是必需的,因为k in d 这个操作会调用它
这里所谓的一致性就是key和str(key)要么有要么没有,in这个操作要和[]保持一致
如果拿掉__contains__,结果就不一致了
但是__contains__的实现要注意
这里没有用更具 Python 风格的方式——k in my_dict——来检查键是否存在,因为那也会导致 contains 被递归调用。为了避免这一情况,这里采取了更显式的方法,直接在这个 self.keys() 里查询
这样就递归调用了,死循环咯
这样才行,对比下
注意key in dict.keys()是很快的
像 k in my_dict.keys() 这种操作在 Python 3 中是很快的,而且即便映射类型对象很庞大也没关系。这是因为 dict.keys() 的返回值是一个“视图”。视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。在“Dictionary view objects”(https://docs.python.org/3/library/stdtypes.html#dictionary-view-objects)里可以找到关于这个细节的文档
可以看到keys()的说明,关键词 set-like,view
6|03.5 字典的变种
https://zhuanlan.zhihu.com/p/343747724 对这几个
collections.OrderedDict
这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。OrderedDict的 popitem 方法默认删除并返回的是字典里的最后一个元素,但是如果像 my_odict.popitem(last=False) 这样调用它,那么它删除并返回第一个被添加进去的元素
示例代码
- 常规的 dict 被设计为非常擅长映射操作。 跟踪插入顺序是次要的。
- OrderedDict 旨在擅长重新排序操作。 空间效率、迭代速度和更新操作的性能是次要的。
- 算法上, OrderedDict 可以比 dict 更好地处理频繁的重新排序操作。 这使其适用于跟踪最近的访问(例如在 LRU cache 中)。
- 对于 OrderedDict ,相等操作检查匹配顺序。
- OrderedDict 类的 popitem() 方法有不同的签名。它接受一个可选参数来指定弹出哪个元素。
- OrderedDict 类有一个 move_to_end() 方法,可以有效地将元素移动到任一端。
- Python 3.8之前, dict 缺少
__reversed__()方法
collections.ChainMap
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文
https://docs.python.org/3/library/collections.html#collections.ChainMap 讲了很多
关键是Chain 链条这个字的体现
官网的例子,模拟Python内部lookup链的例子
ChainMap搜索查询底层映射,直到一个键被找到。不同的是,写,更新和删除只操作第一个映射。
所以,如果一个底层映射更新了,这些更改会反映到 ChainMap
collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候(注:key再次出现)都会增加这个计数器
这个类在力扣的题解中相对常见,可以了解下
官方的例子
一些典型的方法
| 方法 | 简介 |
|---|---|
| elements() | 返回一个迭代器,其中每个元素将重复出现计数值所指定次。 元素会按首次出现的顺序返回。 如果一个元素的计数值小于一,elements()将会忽略它 |
| most_common([n]) | 返回一个列表,其中包含 n 个最常见的元素及出现次数,按常见程度由高到低排序。 如果 n 被省略或为 None,most_common()将返回计数器中的 所有 元素。 计数值相等的元素按首次出现的顺序排序 |
| subtract([iterable-or-mapping]) | 减去一个 可迭代对象 或 映射对象 (或 counter) 中的元素。类似于 dict.update()但是是减去而非替换。输入和输出都可以是 0 或负数 |
| total() | 计算总计数值。 |
7|03.6 子类化UserDict
就创造自定义映射类型来说,以 UserDict 为基类,总比以普通的 dict 为基类要来得方便
而更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题
UserDict 并不是 dict 的子类,但是 UserDict 有一个叫作data 的属性,是 dict 的实例,这个属性实际上是 UserDict 最终存储数据的地
通过UserDict实现的代码如下、
示例3-8
甚至你不需要锦上添花的最后两行就可以实现前面的代码的功能
➊ StrKeyDict 是对 UserDict 的扩展。
➋ __missing__ 跟示例 3-7 里的一模一样。
➌ __contains__ 则更简洁些。这里可以放心假设所有已经存储的键都是字符串。因此,只要在 self.data 上查询就好了,并不需要像 StrKeyDict0 那样去麻烦 self.keys()。
➍ __setitem__ 会把所有的键都转换成字符串。由于把具体的实现委托给了 self.data 属性,这个方法写起来也不难
UserDict 继承的是 MutableMapping
StrKeyDict 里剩下的那些映射类型的方法(注:
__setitem__等)都是从 UserDict、MutableMapping 和 Mapping 这些超类继承而来的
从源码就看到UserDict 是继承自MutableMapping ,但MutableMapping 的继承要从_collections_abc.py中看,这个文件在Python主目录的Lib下,其继承关系如下
Mapping.get方法跟前面定义的是完全一样的,所以你在最新的代码中无需再次去实现get,下面是它的源码
书中还提到了MutableMapping.update
这个方法不但可以为我们所直接利用,它还用在
__init__里,让构造方法可以利用传入的各种参数(其他映射类型、元素是 (key, value) 对的可迭代对象和键值参数)来新建实例。因为这个方法在背后是用 self[key] = value 来添加新值的,所以它其实是在使用我们的__setitem__方法
这update的源码
书中还提供了一个新的类型TransformDict
源自
Antonie Pitrou 写的“PEP 455 —Adding a key-transforming dictionary to collections”(https://www.python.org/dev/peps/pep-0455/
作为 issue 18986(http://bugs.python.org/issue18986 被吸引进Python3.5
https://github.com/fluentpython/example-code/blob/master/03-dict-set/transformdict.py
8|03.7 不可变映射类型
标准库里所有的映射类型都是可变的
从 Python 3.3 开始,types 模块中引入了一个封装类名叫 MappingProxyType
如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味
着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
示例 3-9
➊ d 中的内容可以通过 d_proxy 看到。
➋ 但是通过 d_proxy 并不能做任何修改。
➌ d_proxy 是动态的,也就是说对 d 所做的任何改动都会反馈到它上面。
9|03.8 集合论
set 和它的不可变的姊妹类型 frozenset 在 Python 2.6 中升级成为内置类型
集合的本质是许多唯一对象的聚集
集合中的元素必须是可散列的,set 类型本身是不可散列的,但是 frozenset 可以(注:是可散列的,不可变的,冻结了~)
集合还实现了很多基础的中缀运算符
| 示例 | 运算符 | 方法 |
|---|---|---|
| s1与s2的合集(并集) | s1 | s2 | s1.union(s2) |
| s1与s2的交集 | s1 & s2 | s1.intersection(s2) |
| s1与s2的差集 | s1-s2 | s1.difference(s2) |
| s1与s2中不重复的元素集合(合集-交集) | s1.symmetric_difference(s2) | |
| s1是否是s2的超集 | s1>s2 | s1.issuperset(s2) |
| s1是否是s2的子集 | s1<s2 | s1.issubset(s2) |
书中给了一个案例
有一个电子邮件地址的集合(haystack),还要维护一个较小的电子邮件地址集合(needles),然后求出 needles 中有多少地址同时也出现在了 heystack 里
集合做法
非集合做法
如果needles和haystack不是集合
9|13.8.1 集合字面量
如果是空集,那么必须写成 set() 的形式
如果只是写成 {} 的形式,你创建的其实是个空字典
set([1, 2, 3])的过程: 先从 set 这个名字来查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里
这句话怎么来的呢?dis模块
除了空集你应该用构造方法,其他的都建议用字面量,比如{1,2,3}
BUILD_SET几乎完成了所有的工作。
frozenset则没有字面量的做法,只能用它的构造方法
9|23.8.2 集合推导
这个跟集合推导极其相似
9|33.8.3 集合的操作
collections.abc 中,MutableSet 和它的超类的 UML 类图
表 3-2 中的中缀运算符需要两侧的被操作对象都是集合类型,但是其他的所有方法则只要求所传入的参数是可迭代对象

集合的数学运算:这些方法或者会生成新集合,或者会在条件允许的情况下就地修改集合
鉴于不太常用,我就不这里表格了

集合的比较运算符,返回值是布尔类型
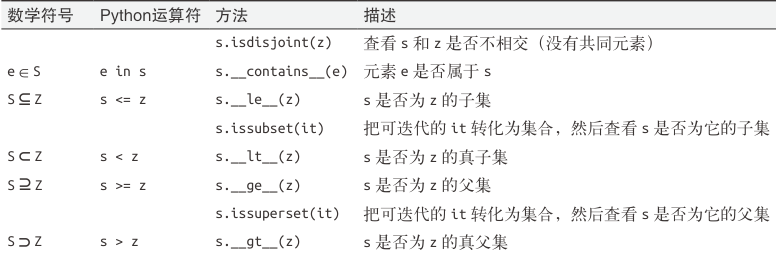
集合类型的其他方法

10|03.9 dict和set的背后
- Python 里的 dict 和 set 的效率有多高?[3.9.1]
- 为什么它们是无序的?
- 为什么并不是所有的 Python 对象都可以当作 dict 的键或 set 里的元素?
- 为什么 dict 的键和 set 元素的顺序是跟据它们被添加的次序而定的,以及为什么在映射对象的生命周期中,这个顺序并不是一成不变的?
- 为什么不应该在迭代循环 dict 或是 set 的同时往里添加元素?
10|13.9.1 一个关于效率的实验
在5个不同大小的haystack里搜索1000个元素所需的时间,haystack分别以字典、集合和列表的形式出现。测试环境是一个有Core i7处理器的笔记本,Python版本是3.4.0
元素是双精度浮点数;needles中500个在haystack存在,另外500个不在; timeit测试得到的时间
基准测试重复了 5 次,每次都把 haystack 的大小变成了上一次的 10 倍,直到里面有 1000 万个元素
运行代码如下
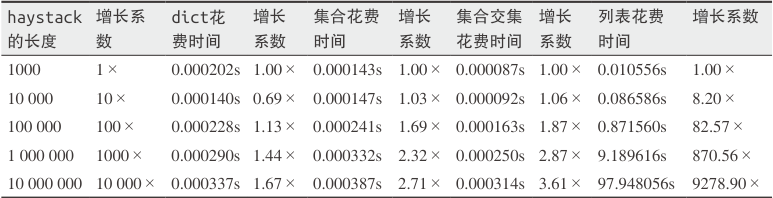
最糟糕的表现来自“列表花费时间”这一列。由于列表的背后没有散列表来支持 in 运算符,每次搜索都需要扫
描一次完整的列表,导致所需的时间跟据 haystack 的大小呈线性增长
10|23.9.2 字典中的散列表
Python 如何用散列表来实现 dict 类型:http://hg.python.org/cpython/file/tip/Objects/dictobject.c 源码中有丰富的注释
显然都是英文,看的费劲
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。散列表里的单元通常叫作表(bucket)。在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元
Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中可以用hash() 方法
1. 散列值和相等性
内置的 hash() 方法可以用于所有的内置类型对象
比如list、tuple等
如果是自定义对象调用 hash() 的话,实际上运行的是自定义的
__hash__
意味着你要用就必须实现
如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了
其实这两个数字(1整型和1.0浮点)的内部结构是完全不一样的
为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间中尽量分散开来。
这意味着在最理想的状况下,越是相似但不相等的对象,它们散列值的差别应该越大
从 Python 3.3 开始,str、bytes 和 datetime 对象的散列值计算过程中多了随机的“加盐”这一步。所加盐值是 Python 进程内的一个常量,但是每次启动Python 解释器都会生成一个不同的盐值。随机盐值的加入是为了防止 DOS 攻击而采取的一种安全措施。
https://docs.python.org/zh-cn/3/reference/datamodel.html#object.hash
这是为了防止通过精心选择输入来利用字典插入操作在最坏情况下的执行效率即 O(n2) 复杂度制造的拒绝服务攻击
http://ocert.org/advisories/ocert-2011-003.html 对此做了详细解释,但反正看不懂
2. 散列表算法
my_dict[search_key]的背后
- Python 首先会调用 hash(search_key) 来计算search_key 的散列值
- 把这个值最低的几位数字当作偏移量(具体取几位,得看当前散列表的大小),在散列表里查找表元
- 若找到的表元是空的,则抛出 KeyError 异常
- 若不是空的,则表元里会有一对 found_key:found_value
- 这时候 Python 会检验 search_key ==found_key 是否为真,如果它们相等的话,就会返回 found_value
- 如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突,
- 为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元
参考下图
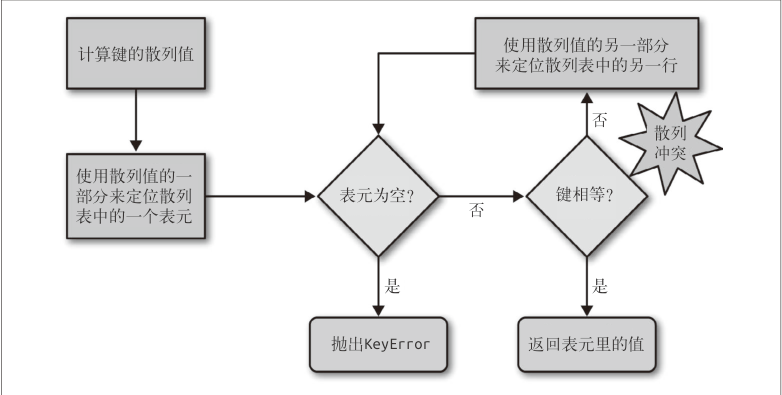
发生这种情况(注:散列冲突)是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。
在插入新值时,Python 可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做的目的是为了减少发生散列冲突的概率
在散列冲突的情况下,用 C 语言写的用来打乱散列值位的算法的名字很有意思,叫 perturb。详见
CPython 源码里的 dictobject.c(https://hg.python.org/cpython/file/tip/Objects/dictobject.c)
10|33.9.3 dict的实现及其导致的结果
1. 键必须是可散列的
一个可散列的对象必须满足以下要求。
(1) 支持 hash() 函数,并且通过__hash__()方法所得到的散列值是不变的。
(2) 支持通过__eq__()方法来检测相等性。
(3) 若 a == b 为真,则 hash(a) == hash(b) 也为真
所有由用户自定义的对象
默认都是可散列的,因为它们的散列值由 id() 来获取,而且它们都是不相等的
2. 字典在内存上的开销巨大
字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下
如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录
用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍
__slots__属性可以改变实例属性的存储方式,由 dict 变成tuple
__slots__ = 'name','age'这一行就规定了这个类就只能有2个属性,如果拿掉一个age,你下面的初始化就会报错,提示可能是AttributeError: 'PersonSlots' object has no attribute 'age'
从下面的案例中可以看出来节省memory,还有一个访问属性更快,事实上,在CPython的实现里,__slots__是一个静态数据结构(static),里面存的是value references,比__dict__更快
优化往往是可维护性的对立面
时间和空间二选一?实际工作中,可能要找到那个最佳的,有时候是找时间最佳的,有时候是空间最佳的,有时候是2者的平衡点
3. 键查询很快
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问:只要字典能被装在内存里
4. 键的次序取决于添加顺序
当往 dict 里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置
在进行比较的时候,它们是相等的
但是如果在 key1 和 key2 被添加到字典里的过程中有冲突发生的话,这两个键出现在字典里的顺序是不一样的
这3个dict
但最后的assert是pass的
5. 往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的
结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。这个过程中可
能会发生新的散列冲突,导致新散列表中键的次序变化。要注意的是,上面提到的这些变化是否会发生以及如何发生,都依赖于字典背后的具体实现,因此你不能很自信地说自己知道背后发生了什么。
如果你在迭代一个字典的所有键的过程中同时对字典进行修改,那么这个循环很有可能会跳过一些键——甚至是跳过那些字典中已经有的键
最后这句话特别重要:迭代一个字典的所有键的过程中同时对字典进行修改可能会有一些意料之外的情况发生
由此可知,不要对字典同时进行迭代和修改。如果想扫描并修改一个字典,最好分成两步来进行:首先对字典迭代,以得出需要添加的内容,把这些内容放在一个新字典里;迭代结束之后再对原有字典进行更新
在 Python 3 中,.keys()、.items() 和 .values() 方法返回的都是字典视图。也就是说,这些方法返回的值更像集合
视图还有动态的特性,它们可以实时反馈字典的变化
10|43.9.4 set的实现以及导致的结果
set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典里只存放键而没有相应的值)。
集合的特点
• 集合里的元素必须是可散列的。
• 集合很消耗内存。
• 可以很高效地判断元素是否存在于某个集合。
• 元素的次序取决于被添加到集合里的次序。
• 往集合里添加元素,可能会改变集合里已有元素的次序
11|03.10 本章小结
小结部分就直接搬过来了,划下重点+温故
字典算得上是 Python 的基石。除了基本的 dict 之外,标准库还提供现成且好用的特殊映射类型,比如 defaultdict、OrderedDict、ChainMap 和 Counter。这些映射类型都属于collections 模块,这个模块还提供了便于扩展的 UserDict 类。
大多数映射类型都提供了两个很强大的方法:setdefault 和 update。
- setdefault 方法可以用来更新字典里存放的可变值(比如列表),从而避免了重复的键搜索。
- update 方法则让批量更新成为可能,它可以用来插入新值或者更新已有键值对,它的参数可以是包含(key, value) 这种键值对的可迭代对象,或者关键字参数。
- 映射类型的构造方法也会利用update 方法来让用户可以使用别的映射对象、可迭代对象或者关键字参数来创建新对象。
在映射类型的 API 中,有个很好用的方法是 __missing__,当对象找不到某个键的时候,可以通过这个方法自定义会发生什么。
collections.abc 模块提供了 Mapping 和 MutableMapping 这两个抽象基类,利用它们,我们可以进行类型查询或者引用。不太为人所知的 MappingProxyType 可以用来创建不可变映射对象,它被封装在 types 模块中。另外还有 Set 和 MutableSet 这两个抽象基类。
dict 和 set 背后的散列表效率很高,对它的了解越深入,就越能理解为什么被保存的元素会呈现出不同的顺序,以及已有的元素顺序会发生变化的原因。同时,速度是以牺牲空间为代价而换来的
12|03.11 延伸阅读
| 素材 | URL | 相关信息 |
|---|---|---|
| 8.3. collections—Container datatypes | https://docs.python.org/3/library/collections.html | 关于一些映射类型的例子和使用技巧 |
Lib/collections/__init__.py |
现有的映射类型的实现方式 | |
| Python Cookbook(第 3 版)中文版》 | 第 1 章中有20 个关于数据结构的使用技巧大多数都在讲 dict 的巧妙用法 | |
| 代码之美》第 18 章:Python 的字典类:如何打造全能战士 | 集中解释了 Python 字典背后的工作原理 | |
| https://hg.python.org/cpython/file/tip/Objects/dictobject.c | CPython 模块里的 dictobject.c 源 文 件提 供 了 大 量 的 注 释 | |
| The Mighty Dictionary | http://pyvideo.org/video/276/the-mighty-dictionary-55 | 对散列表做了很精彩的讲解 |
| PEP 218 — Adding a Built-In Set Object Type | https://www.python.org/dev/peps/pep-0218/ | 为什么要在语言里加入集合这种数据类型 |
| PEP 274 — Dict Comprehensions | https://www.python.org/dev/peps/pep-0274/ | 字典推导的出生证 |
Python 的特点是“简单而正确” dict 类型正是这一特点的完美体现
如果对排序有要求,那么还可以选择 OrderedDict
JSON 被当作“瘦身版 XML”(http://www.json.org/fatfree.html)
历史
PHP 和 Ruby 的散列语法借鉴了 Perl,它们都用 => 作为键和值的连接。
JavaScript 则从 Python 那儿偷师,使用了 :。
而 JSON 又从 JavaScript 发展而来,它的语法正好是Python 句法的子集。
因此,除了在 true、false 和 null 这几个值的拼写上有出入之外,JSON 和 Python 是完全兼容的。于是,现在大家用来交换数据的格式全是 Python的 dict 和 list
__EOF__

本文链接:https://www.cnblogs.com/wuxianfeng023/p/17769050.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)