高性能MySQL之架构篇
MySQL服务器逻辑架构图:
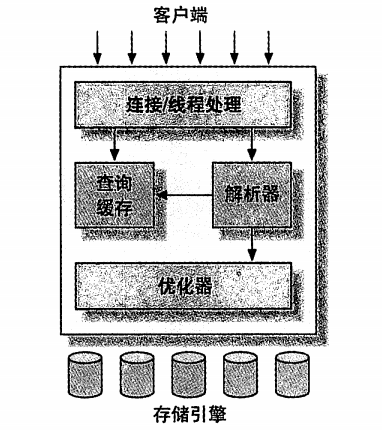
一.事务
1.四个特性:原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability)。
2.隔离级别
(1)READ UNCOMMITTED(未提交读)
事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,这也被称为脏读。这个级别会导致很多问题,从性能上来说,这个级别不会比其他的级别好太多,但却缺乏其他级别的很多好处,除非真的有非常必要的理由,在实际应用中一般很少使用。
(2)READ COMMITTED(提交读)
一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。
(3)REPEATABLE READ(可重复读)
该级别解决了脏读的问题。该级别保证了在同一个事务中多次读取同样记录的结果是一致的。但理论上,可重复读隔离级别还是无法解决另外一个幻读的问题。所谓幻读,指的是当某个事务在读取某个范围的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行。可重复读是MySQL的默认事务隔离级别。
(4)SERIALIZABLE(可串行化)
最高的隔离级别。它通过强制事务串行执行,避免了前面说的幻读的问题。简单来说,会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。实际应用中也很少用到这个隔离级别,只有在非常需要确保数据的一致性而且可以接受没有并发的情况下,才考虑采用该级别。

二.MySQL的存储引擎
1.InnoDB存储引擎
InnoDB是MySQL的默认事务性引擎,也是最重要、使用最广泛的存储引擎。它被设计用来处理大量的短期事务,很少会被回滚。InnoDB的性能和自动崩溃恢复特性,使得它在非事务型存储的需求中也很流行。
2.MyISAM存储引擎
MyISAM提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁,而且有一个毫无疑问的缺陷是崩溃后无法安全恢复。MyISAM对整张表加锁,而不是针对行。
3.MySQL内建的其他存储引擎
Archive引擎:该存储引擎只支持INSERT和SELECT操作。
Blackhole引擎:该引擎没有实现任何的存储机制,它会丢弃所有插入的数据,不做任何保存。
CSV引擎:该引擎可以将普通的CSV文件作为MySQL的表来处理,但这种表不支持索引。
Federated引擎:该引擎是访问其他MySQL服务器的一个代理,它会创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,然后提取或者发送需要的数据。
Memory引擎:如果需要快速的访问数据,并且这些数据不会被修改,重启后丢失也没有关系,那么使用Memory表是非常有用的。
Merge引擎:Merge表是由多个MyISAM表合并而来的虚拟表。
NDB集群引擎:作为SQL和NDB原生协议之间的接口。
4.选择合适的引擎
可以简单地归纳为一句话:“除非需要用到某些InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择InnoDb引擎。”
5.转换表的引擎(三种方法)
(1)ALTER TABLE:ALTER TABLE mytable ENGINE = InnoDB; 这个语法可以使用任何的存储引擎。但有一个问题:需要执行很长时间。MySQL会按行将数据从原表复制到一张新的表中,在复制期间可能会消耗系统所有的I/O能力,同时原表上会加上读锁。可以采用导入导出的方法替代。如果转换表的存储引擎,将会失去和原引擎相关的所有特性。
(2)导出与导入:可以使用mysqldump工具将数据导出到文件,然后修改文件中的CREATE TABLE语句的存储引擎选项,注意同时修改表名,因为同一个数据库中不能存在相同的表名,即使它们使用的是不同的存储引擎。
(3)创建与查询(CREATE和SELECT):这种转换综合了第一种方法的高效和第二种方法的安全。不需要导出整个表的数据,而是先创建一个新的存储引擎的表,然后利用INSERT...SELECT语法来导数据

数据量不大的话,这样做工作得很好。如果数据量很大,则可以考虑做分批处理,针对每一段数据执行事务提交操作,以避免大事务产生过多的undo。假设有主键字段id,重复运行以下语句,将数据导入到新表:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2019-11-03 redis集群之Cluster