Guava集合--新集合类型
Guava引入了很多JDK没有的、但我们发现明显有用的新集合类型。这些新类型是为了和JDK集合框架共存,而没有往JDK集合抽象中硬塞其他概念。作为一般规则,Guava集合非常精准地遵循了JDK接口契约。
一.Multiset
1.统计一个词在文档中出现了多少次,传统的做法是这样的:

Map<String, Integer> counts = new HashMap<String, Integer>(); for (String word : words) { Integer count = counts.get(word); if (count == null) { counts.put(word, 1); } else { counts.put(word, count + 1); } }
这种写法很笨拙,也容易出错,并且不支持同时收集多种统计信息,如总词数。我们可以做的更好。
2.Guava提供了多种Multiset的实现,大致对应JDK中Map的各种实现:
| Map | 对应的Multiset | 是否支持null元素 |
| HashMap | HashMultiset | 是 |
| TreeMap | TreeMultiset | 是(如果comparator支持的话) |
| LinkedHashMap | LinkedHashMultiset | 是 |
| ConcurrentHashMap | ConcurrentHashMultiset | 否 |
| ImmutableMap | ImmutableMultiset | 否 |
3.Multiset的方法如下
| 方法 | 描述 |
| count(E) | 给定元素在Multiset中的计数 |
| elementSet() | Multiset中不重复元素的集合,类型为Set<E> |
| entrySet() | 和Map的entrySet类似,返回Set<Multiset.Entry<E>>,其中包含的Entry支持getElement()和getCount()方法 |
| add(E, int) | 增加给定元素在Multiset中的计数 |
| remove(E, int) | 减少给定元素在Multiset中的计数 |
| setCount(E, int) | 设置给定元素在Multiset中的计数,不可以为负数 |
| size() | 返回集合元素的总个数(包括重复的元素) |
package collections; import com.google.common.collect.HashMultiset; import com.google.common.collect.Lists; import com.google.common.collect.Multiset; import java.util.Set; public class GuavaMultiset { public static void main(String[] args) { Multiset<String> multiset = HashMultiset.create(); multiset.addAll( Lists.newArrayList("I","love","China","China","is","my","love")); int love = multiset.count("love"); System.out.println("love num:" + love); Set<String> elementSet = multiset.elementSet(); System.out.println("Multiset中不重复元素的集合,类型为Set<E>:" + elementSet); Set<Multiset.Entry<String>> entries = multiset.entrySet();//统计元素频次 System.out.println("entrySet:" + entries);//[love x 2, China x 2, I, is, my] multiset.add("add",2); System.out.println("增加add后的数据:" + multiset); multiset.remove("add",2); System.out.println("移除add后的数据:" + multiset); multiset.setCount("love", 1); System.out.println("设置love计数为1后的数据:" + multiset); System.out.println("返回集合中的总个数:" + multiset.size()); } }
运行结果:
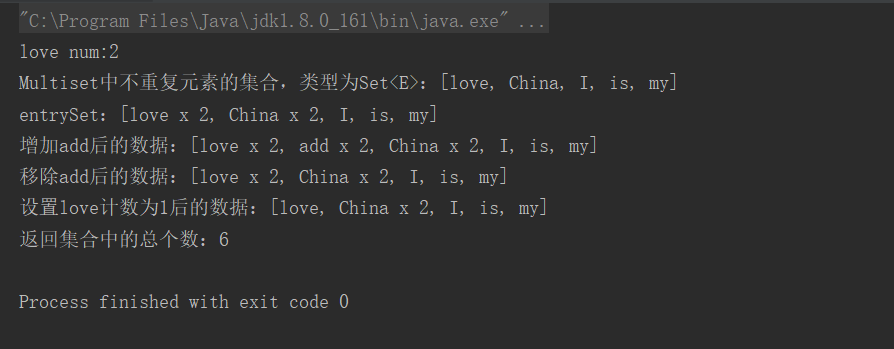
可以用两种方式看待Multiset:
- 没有元素顺序限制的ArrayList<E>
- Map<E, Integer>,键为元素,值为计数
Guava的Multiset API也结合考虑了这两种方式:
当把Multiset看成普通的Collection时,它表现得就像无序的ArrayList:
- add(E)添加单个给定元素
- iterator()返回一个迭代器,包含Multiset的所有元素(包括重复的元素)
- size()返回所有元素的总个数(包括重复的元素)
当把Multiset看作Map<E, Integer>时,它也提供了符合性能期望的查询操作:
- count(Object)返回给定元素的计数。HashMultiset.count的复杂度为O(1),TreeMultiset.count的复杂度为O(log n)。
- entrySet()返回Set<Multiset.Entry<E>>,和Map的entrySet类似。
- elementSet()返回所有不重复元素的Set<E>,和Map的keySet()类似。
- 所有Multiset实现的内存消耗随着不重复元素的个数线性增长。
值得注意的是,除了极少数情况,Multiset和JDK中原有的Collection接口契约完全一致——具体来说,TreeMultiset在判断元素是否相等时,与TreeSet一样用compare,而不是Object.equals。另外特别注意,Multiset.addAll(Collection)可以添加Collection中的所有元素并进行计数,这比用for循环往Map添加元素和计数方便多了。
二.Multimap
1.传统实现
每个有经验的Java程序员都在某处实现过Map<K, List<V>>或Map<K, Set<V>>,并且要忍受这个结构的笨拙,以便做相应的业务逻辑处理。例如:
Map<String, List<Student>> studentMap = new HashMap<>(); for (int i = 0; i < 5; i++) { Student student = new Student(); student.setName("multimap"+i); student.setAge(i); List<Student> list = studentMap.get(student.getName()); if (list != null) { list.add(student); } else { list = new ArrayList<>(); list.add(student); studentMap.put(student.getName(), list); } }
像 Map<String, List<StudentScore>> StudentScoreMap = new HashMap<String, List<StudentScore>>()这样的数据结构,自己实现起来太麻烦,你需要检查key是否存在,不存在时则创建一个,存在时在List后面添加上一个。这个过程是比较痛苦的,如果你希望检查List中的对象是否存在,删除一个对象,或者遍历整个数据结构,那么则需要更多的代码来实现。
2.关于Multimap
Guava的Multimap就提供了一个方便地把一个键对应到多个值的数据结构。让我们可以简单优雅的实现上面复杂的数据结构,让我们的精力和时间放在实现业务逻辑上,而不是在数据结构上,下面我们具体来看看Multimap的相关知识点。
可以用两种方式思考Multimap的概念:”键-单个值映射”的集合:
a -> 1 a -> 2 a ->4 b -> 3 c -> 5
或者”键-值集合映射”的映射:
a -> [1, 2, 4] b -> 3 c -> 5
一般来说,Multimap接口应该用第一种方式看待,但asMap()视图返回Map<K, Collection<V>>,让你可以按另一种方式看待Multimap。重要的是,不会有任何键映射到空集合:一个键要么至少到一个值,要么根本就不在Multimap中。
很少会直接使用Multimap接口,更多时候你会用ListMultimap或SetMultimap接口,它们分别把键映射到List或Set。
3.Multimap的方法有:
| 方法签名 | 描述 | 等价于 |
| put(K, V) | 添加键到单个值的映射 | multimap.get(key).add(value) |
| putAll(K, Iterable<V>) | 依次添加键到多个值的映射 | Iterables.addAll(multimap.get(key), values) |
| remove(K, V) | 移除键到值的映射;如果有这样的键值并成功移除,返回true。 | multimap.get(key).remove(value) |
| removeAll(K) | 清除键对应的所有值,返回的集合包含所有之前映射到K的值,但修改这个集合就不会影响Multimap了。 | multimap.get(key).clear() |
| replaceValues(K, Iterable<V>) | 清除键对应的所有值,并重新把key关联到Iterable中的每个元素。返回的集合包含所有之前映射到K的值。 | multimap.get(key).clear(); Iterables.addAll(multimap.get(key), values) |
例子:
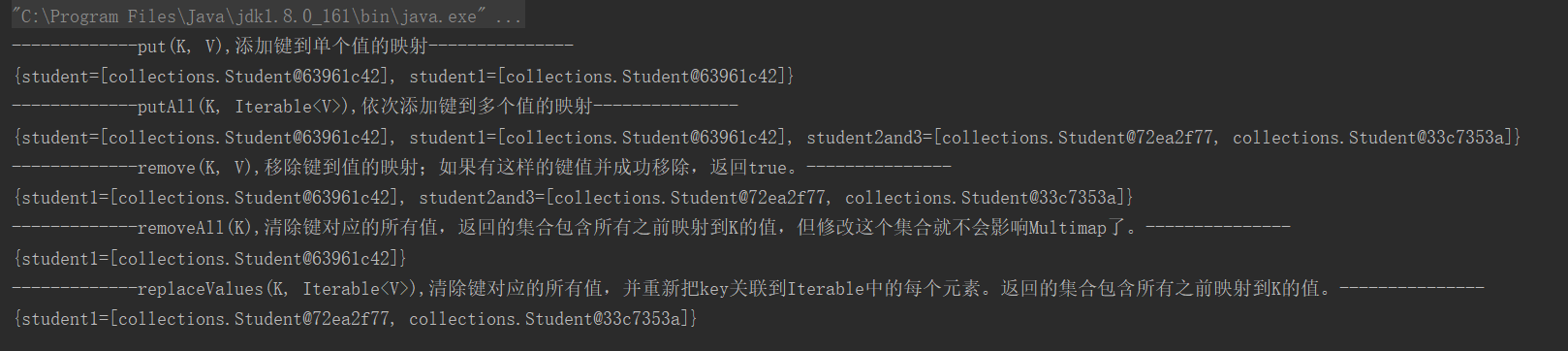
package collections; import com.google.common.collect.ArrayListMultimap; import com.google.common.collect.Multimap; import java.util.ArrayList; import java.util.List; public class GuavaMultimap { public static void main(String[] args) { Multimap<String,Student> stuMultimap = ArrayListMultimap.create(); Student student1 = new Student(); student1.setName("student1"); student1.setAge(1); stuMultimap.put("student",student1); stuMultimap.put("student1",student1); System.out.println("-------------put(K, V),添加键到单个值的映射---------------"); System.out.println(stuMultimap); Student student2 = new Student(); student2.setName("student2"); student2.setAge(2); Student student3 = new Student(); student3.setName("student3"); student3.setAge(3); List<Student> stuList = new ArrayList<>(); stuList.add(student2); stuList.add(student3); stuMultimap.putAll("student2and3",stuList); System.out.println("-------------putAll(K, Iterable<V>),依次添加键到多个值的映射---------------"); System.out.println(stuMultimap); stuMultimap.remove("student",student1); System.out.println("-------------remove(K, V),移除键到值的映射;如果有这样的键值并成功移除,返回true。---------------"); System.out.println(stuMultimap); stuMultimap.removeAll("student2and3"); System.out.println("-------------removeAll(K),清除键对应的所有值,返回的集合包含所有之前映射到K的值,但修改这个集合就不会影响Multimap了。---------------"); System.out.println(stuMultimap); stuMultimap.replaceValues("student1",stuList); System.out.println("-------------replaceValues(K, Iterable<V>),清除键对应的所有值,并重新把key关联到Iterable中的每个元素。返回的集合包含所有之前映射到K的值。---------------"); System.out.println(stuMultimap); } }
运行结果:
4.Multimap的各种实现
Multimap提供了多种形式的实现。在大多数要使用Map<K, Collection<V>>的地方,你都可以使用它们:
| 实现 | 键行为类似 | 值行为类似 |
| ArrayListMultimap | HashMap | ArrayList |
| HashMultimap | HashMap | HashSet |
| LinkedListMultimap* | LinkedHashMap* | LinkedList* |
| LinkedHashMultimap** | LinkedHashMap | LinkedHashMap |
| TreeMultimap | TreeMap | TreeSet |
| ImmutableListMultimap | ImmutableMap | ImmutableList |
| ImmutableSetMultimap | ImmutableMap | ImmutableSet |
以上这些实现,除了immutable的实现都支持null的键和值。
*LinkedListMultimap.entries()保留了所有键和值的迭代顺序。
**LinkedHashMultimap保留了映射项的插入顺序,包括键插入的顺序,以及键映射的所有值的插入顺序。
请注意,并非所有的Multimap都和上面列出的一样,使用Map<K, Collection<V>>来实现(特别是,一些Multimap实现用了自定义的hashTable,以最小化开销)
如果你想要更大的定制化,请用Multimaps.newMultimap(Map, Supplier<Collection>)或list和 set版本,使用自定义的Collection、List或Set实现Multimap。
5.Multimap也支持一系列强大的视图功能:
1.asMap把自身Multimap<K, V>映射成Map<K, Collection<V>>视图。这个Map视图支持remove和修改操作,但是不支持put和putAll。严格地来讲,当你希望传入参数是不存在的key,而且你希望返回的是null而不是一个空的可修改的集合的时候就可以调用 asMap().get(key)。(你可以强制转型asMap().get(key)的结果类型-对SetMultimap的结果转成Set,对ListMultimap的结果转成List型-但是直接把ListMultimap转成Map<K, List<V>>是不行的。)
2.entries视图是把Multimap里所有的键值对以Collection<Map.Entry<K, V>>的形式展现。
3.keySet视图是把Multimap的键集合作为视图
4.keys视图返回的是个Multiset,这个Multiset是以不重复的键对应的个数作为视图。这个Multiset可以通过支持移除操作而不是添加操作来修改Multimap。
5.values()视图能把Multimap里的所有值“平展”成一个Collection<V>。这个操作和Iterables.concat(multimap.asMap().values())很相似,只是它返回的是一个完整的Collection。
尽管Multimap的实现用到了Map,但Multimap<K, V>不是Map<K, Collection<V>>。因为两者有明显区别:
1.Multimap.get(key)一定返回一个非null的集合。但这不表示Multimap使用了内存来关联这些键,相反,返回的集合只是个允许添加元素的视图。
2.如果你喜欢像Map那样当不存在键的时候要返回null,而不是Multimap那样返回空集合的话,可以用asMap()返回的视图来得到Map<K, Collection<V>>。(这种情况下,你得把返回的Collection<V>强转型为List或Set)。
3.Multimap.containsKey(key)只有在这个键存在的时候才返回true。
4.Multimap.entries()返回的是Multimap所有的键值对。但是如果需要key-collection的键值对,那就得用asMap().entries()。
5.Multimap.size()返回的是entries的数量,而不是不重复键的数量。如果要得到不重复键的数目就得用Multimap.keySet().size()。
例子:
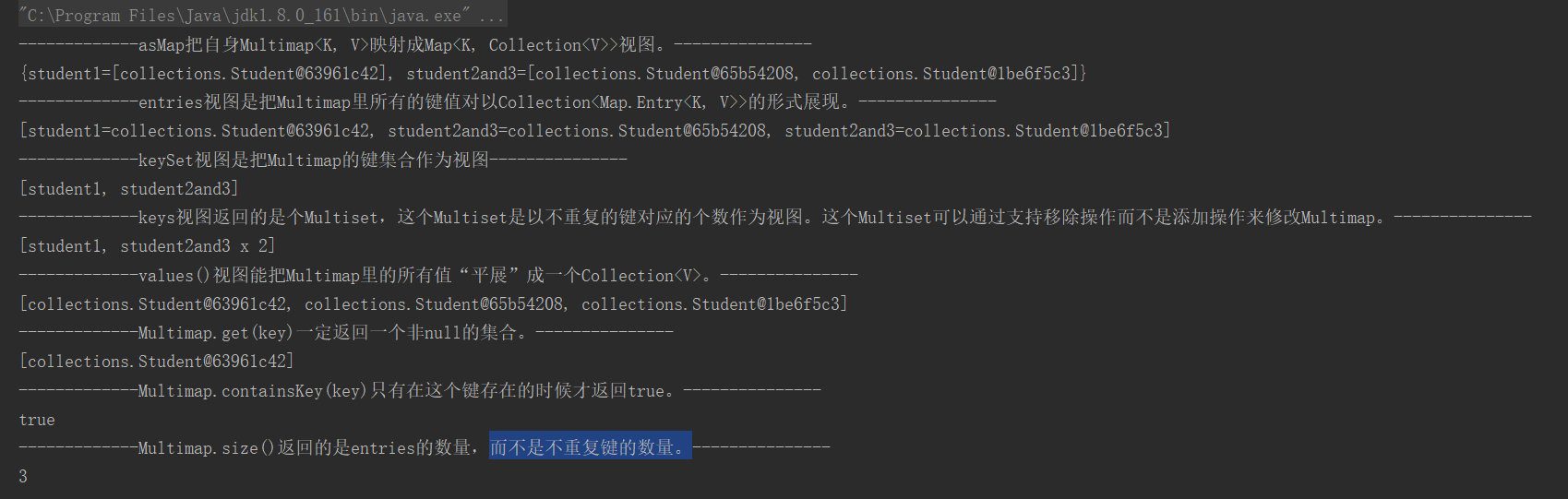
package collections; import com.google.common.collect.ArrayListMultimap; import com.google.common.collect.Multimap; import com.google.common.collect.Multiset; import java.util.Collection; import java.util.Map; import java.util.Set; public class GuavaMultimap { public static void main(String[] args) { Multimap<String,Student> stuMultimap = ArrayListMultimap.create(); Student student1 = new Student(); student1.setName("student1"); student1.setAge(1); Student student2 = new Student(); student2.setName("student2"); student2.setAge(2); Student student3 = new Student(); student3.setName("student3"); student3.setAge(3); stuMultimap.put("student1",student1); stuMultimap.put("student2and3",student2); stuMultimap.put("student2and3",student3); Map<String, Collection<Student>> stringCollectionMap = stuMultimap.asMap(); System.out.println("-------------asMap把自身Multimap<K, V>映射成Map<K, Collection<V>>视图。---------------"); System.out.println(stringCollectionMap); Collection<Map.Entry<String, Student>> entries = stuMultimap.entries(); System.out.println("-------------entries视图是把Multimap里所有的键值对以Collection<Map.Entry<K, V>>的形式展现。---------------"); System.out.println(entries); Set<String> strings = stuMultimap.keySet(); System.out.println("-------------keySet视图是把Multimap的键集合作为视图---------------"); System.out.println(strings); Multiset<String> keys = stuMultimap.keys(); System.out.println("-------------keys视图返回的是个Multiset,这个Multiset是以不重复的键对应的个数作为视图。这个Multiset可以通过支持移除操作而不是添加操作来修改Multimap。---------------"); System.out.println(keys); Collection<Student> values = stuMultimap.values(); System.out.println("-------------values()视图能把Multimap里的所有值“平展”成一个Collection<V>。---------------"); System.out.println(values); Collection<Student> stus = stuMultimap.get("student1"); System.out.println("-------------Multimap.get(key)一定返回一个非null的集合。---------------"); System.out.println(stus); boolean student1Key = stuMultimap.containsKey("student1"); System.out.println("-------------Multimap.containsKey(key)只有在这个键存在的时候才返回true。---------------"); System.out.println(student1Key); int size = stuMultimap.size(); System.out.println("-------------Multimap.size()返回的是entries的数量,而不是不重复键的数量。---------------"); System.out.println(size); } }
运行结果:
三.BiMap
相信有很多开发者会遇到这种情况:在开发的过程中,定义了一个Map,往往是通过key来查找value的,但如果需要通过value来查找key,我们就需要额外编写一些代码了。
刚好BiMap提供了一种新的集合类型,它提供了key和value的双向关联的数据结构。下面我们来看看这两者的实现:
1.传统的做法:
package com.guava; import java.util.Map; import java.util.Map.Entry; import com.google.common.collect.Maps; public class BiMapTest { public static void main(String[] args) { Map<Integer,String> idToName = Maps.newHashMap(); idToName.put(1,"zhangsan"); idToName.put(2,"lisi"); idToName.put(3,"wangwu"); System.out.println("idToName:"+idToName); Map<String,Integer> nameToId = Maps.newHashMap(); for(Entry<Integer, String> entry: idToName.entrySet()) { nameToId.put(entry.getValue(), entry.getKey()); } System.out.println("nameToId:"+nameToId); } }
运行结果:

上面的代码可以帮助我们实现map倒转的要求,但是还有一些我们需要考虑的问题:
1. 如何处理重复的value的情况。不考虑的话,反转的时候就会出现覆盖的情况.
2. 如果在反转的map中增加一个新的key,倒转前的map是否需要更新一个值呢?
在这种情况下需要考虑的业务以外的内容就增加了,编写的代码也变得不那么易读了。这时我们就可以考虑使用Guava中的BiMap了。
2.使用Guava中的BiMap
package com.guava; import com.google.common.collect.BiMap; import com.google.common.collect.HashBiMap; public class BiMapTest { public static void main(String[] args) { BiMap<Integer,String> idToName = HashBiMap.create(); idToName.put(1,"zhangsan"); idToName.put(2,"lisi"); idToName.put(3,"wangwu"); System.out.println("idToName:"+idToName); BiMap<String,Integer> nameToId = idToName.inverse(); System.out.println("nameToId:"+nameToId); } }
运行结果:

3.关于Bimap数据的强制唯一性
在使用BiMap进行key、value反转时,会要求Value的唯一性。如果value重复了则会抛出错误:java.lang.IllegalArgumentException,例如:
package com.guava; import com.google.common.collect.BiMap; import com.google.common.collect.HashBiMap; public class BiMapTest { public static void main(String[] args) { BiMap<Integer,String> idToName = HashBiMap.create(); idToName.put(1,"zhangsan"); idToName.put(2,"lisi"); idToName.put(3,"wangwu"); idToName.put(4, "wangwu"); System.out.println("idToName:"+idToName); BiMap<String,Integer> nameToId = idToName.inverse(); System.out.println("nameToId:"+nameToId); } }
运行结果:

如果我们确实需要插入重复的value值,那可以选择forcePut方法。但是我们需要注意的是前面的key也会被覆盖了。
package com.guava; import com.google.common.collect.BiMap; import com.google.common.collect.HashBiMap; public class BiMapTest { public static void main(String[] args) { BiMap<Integer,String> idToName = HashBiMap.create(); idToName.put(1,"zhangsan"); idToName.put(2,"lisi"); idToName.put(3,"wangwu"); idToName.forcePut(4, "wangwu"); System.out.println("idToName:"+idToName); BiMap<String,Integer> nameToId = idToName.inverse(); System.out.println("nameToId:"+nameToId); } }
运行结果:

4.BiMap的各种实现
| 键–值实现 | 值–键实现 | 对应的BiMap实现 |
| HashMap | HashMap | HashBiMap |
| ImmutableMap | ImmutableMap | ImmutableBiMap |
| EnumMap | EnumMap | EnumBiMap |
| EnumMap | HashMap | EnumHashBiMap |
四.Table
当我们需要多个索引的数据结构的时候,通常情况下,我们只能用这种丑陋的Map<FirstName, Map<LastName, Person>>来实现。为此Guava提供了一个新的集合类型-Table集合类型,来支持这种数据结构的使用场景。Table支持“row”和“column”,而且提供多种视图。
1.例子
package com.guava; import com.google.common.collect.HashBasedTable; import com.google.common.collect.Table; public class TableTest { public static void main(String[] args) { Table<String, Integer, String> aTable = HashBasedTable.create(); aTable.put("A", 1, "A1"); aTable.put("A", 2, "A2"); aTable.put("B", 2, "B2"); System.out.println(aTable.column(2)); System.out.println(aTable.row("B")); System.out.println(aTable.get("B", 2)); System.out.println(aTable.contains("B", 2)); System.out.println(aTable.containsColumn(2)); System.out.println(aTable.containsRow("B")); System.out.println(aTable.columnMap()); System.out.println(aTable.rowMap()); System.out.println(aTable.remove("B", 2)); } }
运行结果:

2.Table的视图
-
rowMap():用Map<R, Map<C, V>>表现Table<R, C, V>。同样的, rowKeySet()返回”行”的集合Set<R>。
-
row(r) :用Map<C, V>返回给定”行”的所有列,对这个map进行的写操作也将写入Table中。
-
类似的列访问方法:columnMap()、columnKeySet()、column(c)。(基于列的访问会比基于的行访问稍微低效点)
-
cellSet():用元素类型为Table.Cell<R, C, V>的Set表现Table<R, C, V>。Cell类似于Map.Entry,但它是用行和列两个键区分的。
3.Table有如下几种实现:
-
HashBasedTable:本质上用HashMap<R, HashMap<C, V>>实现;
-
TreeBasedTable:本质上用TreeMap<R, TreeMap<C,V>>实现;
-
ImmutableTable:本质上用ImmutableMap<R, ImmutableMap<C, V>>实现;注:ImmutableTable对稀疏或密集的数据集都有优化。
-
ArrayTable:要求在构造时就指定行和列的大小,本质上由一个二维数组实现,以提升访问速度和密集Table的内存利用率。ArrayTable与其他Table的工作原理有点不同。
五.ClassToInstanceMap
ClassToInstanceMap是一种特殊的Map:它的键是类型,而值是符合键所指类型的对象。
为了扩展Map接口,ClassToInstanceMap额外声明了两个方法:T getInstance(Class<T>) 和T putInstance(Class<T>, T),从而避免强制类型转换,同时保证了类型安全。
ClassToInstanceMap有唯一的泛型参数,通常称为B,代表Map支持的所有类型的上界。例如:
ClassToInstanceMap<Number> numberDefaults = MutableClassToInstanceMap.create(); numberDefaults.putInstance(Integer.class, Integer.valueOf(0));
从技术上讲,ClassToInstanceMap<B>实现了Map<Class<? extends B>, B>——或者换句话说,是一个映射B的子类型到对应实例的Map。这让ClassToInstanceMap包含的泛型声明有点令人困惑,但请记住B始终是Map所支持类型的上界——通常B就是Object。
对于ClassToInstanceMap,Guava提供了两种有用的实现:MutableClassToInstanceMap和 ImmutableClassToInstanceMap。
例子:
package com.guava; import com.google.common.collect.ClassToInstanceMap; import com.google.common.collect.MutableClassToInstanceMap; public class ClassToInstanceMapTest { public static void main(String[] args) { ClassToInstanceMap<Object> classToInstanceMapString =MutableClassToInstanceMap.create(); classToInstanceMapString.put(String.class, "lisi"); classToInstanceMapString.put(Integer.class, 666); System.out.println("string:"+classToInstanceMapString.getInstance(String.class)); System.out.println("Integer:"+classToInstanceMapString.getInstance(Integer.class)); } }
运行结果:

六.RangeSet
RangeSet类是用来存储一些不为空的也不相交的范围的数据结构。假如需要向RangeSet的对象中加入一个新的范围,那么任何相交的部分都会被合并起来,所有的空范围都会被忽略。
讲了这么多,我们该怎么样利用RangeSet?RangeSet类是一个接口,需要用它的子类来声明一个RangeSet型的对象,实现了RangeSet接口的类有ImmutableRangeSet和TreeRangeSet,ImmutableRangeSet是一个不可修改的RangeSet,而TreeRangeSet是利用树的形式来实现。下面主要谈TreeRangeSet的用法:
package com.guava; import com.google.common.collect.Range; import com.google.common.collect.RangeSet; import com.google.common.collect.TreeRangeSet; public class RangeSetTest { public static void main(String[] args) { RangeSet<Integer> rangeSet = TreeRangeSet.create(); rangeSet.add(Range.closed(1, 10)); System.out.println("rangeSet:"+rangeSet); rangeSet.add(Range.closedOpen(11, 15)); System.out.println("rangeSet:"+rangeSet); rangeSet.add(Range.open(15, 20)); System.out.println("rangeSet:"+rangeSet); rangeSet.add(Range.openClosed(0, 0)); System.out.println("rangeSet:"+rangeSet); rangeSet.remove(Range.open(5, 10)); System.out.println("rangeSet:"+rangeSet); } }
运行结果:

请注意,要合并Range.closed(1, 10)和Range.closedOpen(11, 15)这样的区间,你需要首先用Range.canonical(DiscreteDomain)对区间进行预处理,例如DiscreteDomain.integers()。
注:RangeSet不支持GWT,也不支持JDK5和更早版本;因为,RangeSet需要充分利用JDK6中NavigableMap的特性。
1.RangeSet的视图
RangeSet的实现支持非常广泛的视图:
- complement():返回RangeSet的补集视图。complement也是RangeSet类型,包含了不相连的、非空的区间。
- subRangeSet(Range<C>):返回RangeSet与给定Range的交集视图。这扩展了传统排序集合中的headSet、subSet和tailSet操作。
- asRanges():用Set<Range<C>>表现RangeSet,这样可以遍历其中的Range。
- asSet(DiscreteDomain<C>)(仅ImmutableRangeSet支持):用ImmutableSortedSet<C>表现RangeSet,以区间中所有元素的形式而不是区间本身的形式查看。(这个操作不支持DiscreteDomain 和RangeSet都没有上边界,或都没有下边界的情况)
2.RangeSet的查询方法
为了方便操作,RangeSet直接提供了若干查询方法,其中最突出的有:
- contains(C):RangeSet最基本的操作,判断RangeSet中是否有任何区间包含给定元素。
- rangeContaining(C):返回包含给定元素的区间;若没有这样的区间,则返回null。
- encloses(Range<C>):简单明了,判断RangeSet中是否有任何区间包括给定区间。
- span():返回包括RangeSet中所有区间的最小区间。
七.RangeMap
RangeMap描述了”不相交的、非空的区间”到特定值的映射。和RangeSet不同,RangeMap不会合并相邻的映射,即便相邻的区间映射到相同的值。
1.RangeMap的视图
RangeMap提供两个视图:
- asMapOfRanges():用Map<Range<K>, V>表现RangeMap。这可以用来遍历RangeMap。
- subRangeMap(Range<K>):用RangeMap类型返回RangeMap与给定Range的交集视图。这扩展了传统的headMap、subMap和tailMap操作。
例子:
package com.guava; import com.google.common.collect.Range; import com.google.common.collect.RangeMap; import com.google.common.collect.TreeRangeMap; public class RangeMapTest { public static void main(String[] args) { RangeMap<Integer, String> rangeMap = TreeRangeMap.create(); rangeMap.put(Range.closed(1, 10), "foo"); System.out.println("rangeMap:"+rangeMap); rangeMap.put(Range.open(3, 6), "bar"); System.out.println("rangeMap:"+rangeMap); rangeMap.put(Range.open(10, 20), "foo"); System.out.println("rangeMap:"+rangeMap); rangeMap.remove(Range.closed(5, 11)); System.out.println("rangeMap:"+rangeMap); RangeMap<Integer, String> subRangeMap = rangeMap.subRangeMap(Range.closed(3, 15)); System.out.println("subRangeMap:"+subRangeMap); } }
运行结果:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架