

关于Mysql索引、事务的一些简述
数据结构学习网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
一、索引是什么?
索引是帮助mysql高效获取数据的排好序的数据结构
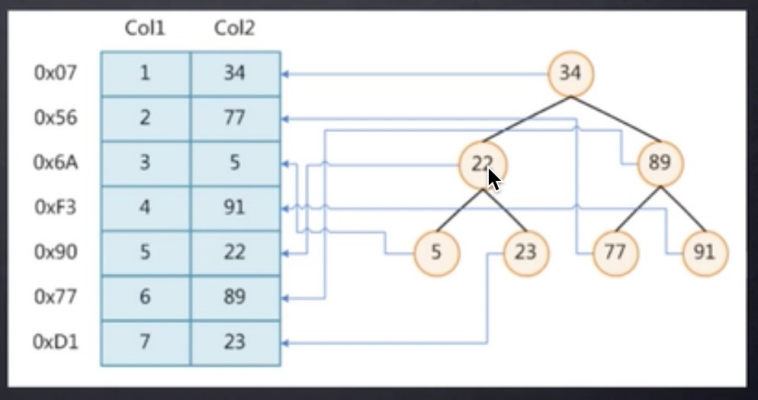
1. 二叉树:数据越多,树越高,操作时,IO消耗就越多,效率就越低
- BST:数据不平衡
- AVL:插入数据时,需经过无数次的旋转,左子树和右子树高度之差不能超过1
- RED/BLACK:插入数据时,尽可能少旋转,最长子树不能超过最短子树的两倍
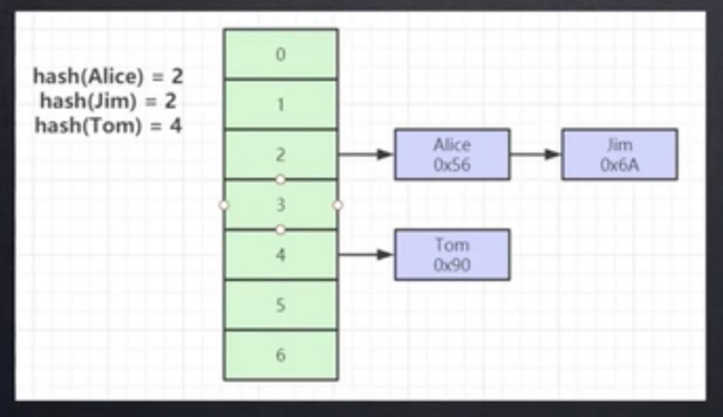
2. Hash:不支持范围查询和模糊查询
- 由数组+链表组成hash表
- 不支持范围查询
- 需要将所有的数据文件存储到内存中,比较消耗内存空间
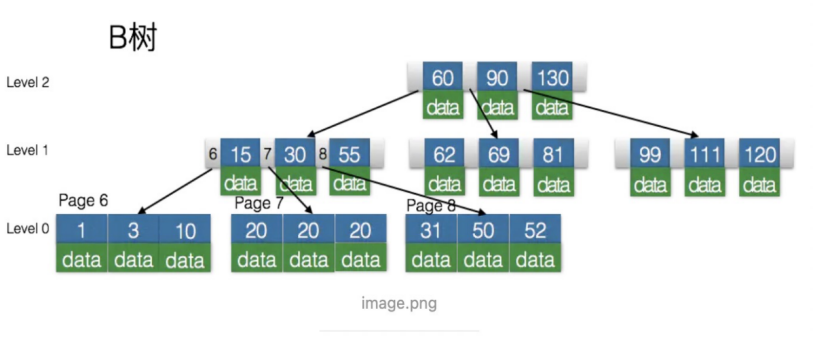
3. B-Tree:多路平衡搜索树,类似于平衡二叉树,不同的是拥有更多的子节点
- 所有键值分布在整棵树中,索引值和data数据都在每个节点里
- 任何一个键值出现且只出现在一个节点中
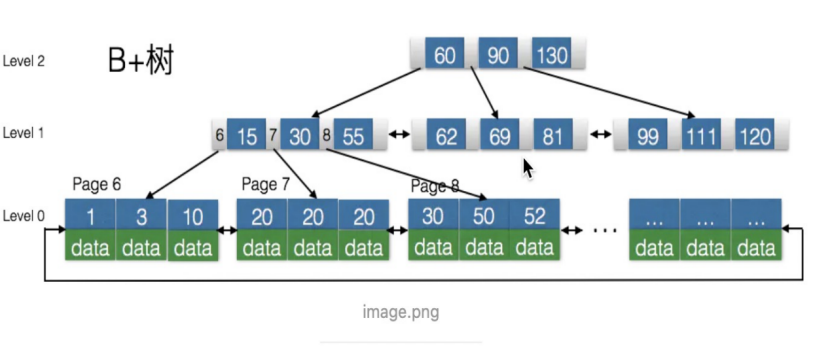
4. B+Tree:B Tree基础之上做多一种优化,变化如下:
- B+Tree每个节点包含更多的节点。这样做的原因有两个,一是为了降低树的高度,二是将数据范围变成多个区间,区间越多,数据检索越快
- 非叶子结点存储key,叶子节点存储key和数据
- 叶子节点两两指针互相连接(符合磁盘的预读特性),顺序查询性能更高
二、索引的文件存储形式与存储引擎有关
1. Myisam:索引文件与数据文件分离,非聚集索引
- *.frm:表结构文件
- *.MYD:表数据文件
- *.MYI:表索引的数据树文件
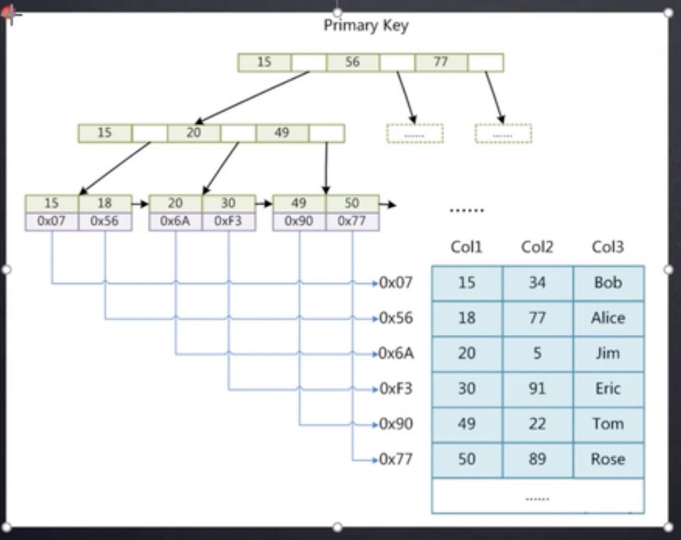
2. Innodb:聚集索引+非聚集索引
- *.frm:表结构文件
- *.ibd:索引文件和数据文件
三、隐藏字段
InnoDB表必须有主键,并且推荐使用整型的自增主键?
设计如此,没有主键,则唯一索引;没有唯一索引,则mysql自建主键。整型的排序性能好。自增的插入效率高。
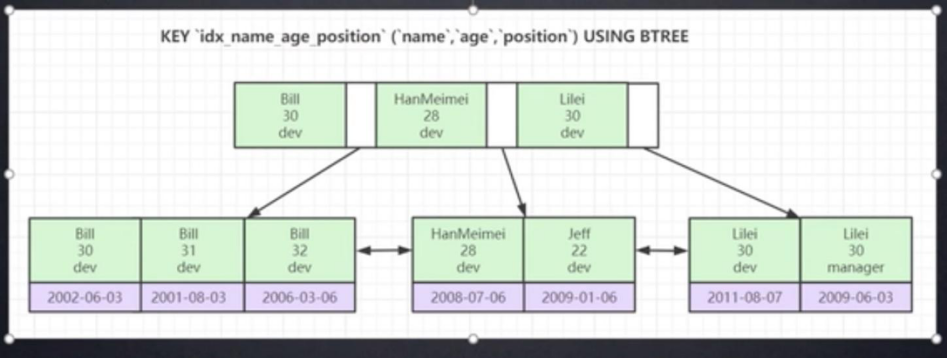
四、联合索引
最左优先原则:
五、事务
- 特性:原子性、一致性、隔离型、持久性、(ACID)
- 是否使用一致性非锁定读
- 当前读:读取的是数据的最新版本(update、delete、select … for update、select …lock in share mode)
- 快照读:读取的是历史数据(select)
- 锁是事务隔离性的实现原理,有以下四种隔离级别
- 读未提交
- 读已提交:解诀脏读问题。当前读
- 可重复读:解决不可重复读问题。快照读
- 串行化
- MVCC:多版本并发控制,一行数据存在多个不同的版本数据
- 隐藏字读:每一列数据,包含3个隐藏字段:隐藏id、事务id、回滚指针。
- 隐藏id:innodb存储引擎每次在进行数据插入的时候,数据必须要跟某一个索引列绑定在一起,这个索引列有一个选择的顺序,如果表有主键,选择主键,如果没有主键,选择唯一键,如果没有唯一键,选择自动生成的一个6字节的rowid
- undo log:用于存放数据修改时被修改前的值。
- 当rollback时将数据恢复到原始数据,保证了事务的原子性。
- 使用undo log实现mvcc,从undo log中读取旧版本的数据
- read view:当进行快照读的时候会生成一个事务id的列表,来保存不同的信息,通过这些信息来做可见性判断,从而计算出当前事务读取的是哪一个版本的历史数据。
- list:生成readview时活跃的id
- up_limit_id:当前活跃id的最小值
- lower_limit_id:尚未分配的下一个事务id
- 锁:用来控制不同的事务并发执行的时候能够操作对应的数据行,innodb加锁是给索引加锁
- 行锁:分为共享锁和排他锁
- 间隙锁
- 临键锁
- 记录锁
- 表锁
- 意向锁
- 自增锁
- 幻读:如果所有的读取都是快照读,那么不会有幻读问题;如果有快照读,也有当前读,才会产生幻读问题
六、Mysql一些名词解释
- 回表:数据在进行插入的时候必须要跟某一个索引列存储在一起,此时的索引列叫做聚簇索引,其他的索引存储的是聚簇索引的key值,在进行数据查找的时候,先从其他索引中找到key,再通过key去聚簇索引中找到数据,这个过程称之为回表
- 索引覆盖:在进行检索的时候,从辅助索引中就能获取到需要的记录,而不需要查找聚簇索引中的记录。使用覆盖索引的一个好处是因为辅助索引不包括一条记录的整行信息,所以数据量较聚集索引要少,可以减少大量io操作
- 最左匹配:一个索引中包含多个索引列被称为联合索引,在建立联合索引的时候会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
- 索引下推(5.7之后默认开启):如果没有进行索引下推优化,在进行索引查询时,首先根据索引来查找记录,然后再根据where条件来过滤记录;而进行索引下推优化之后,在检索数据时,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通