
【算法导论学习笔记】第3章:函数的增长
原创博客,转载请注明:
http://www.cnblogs.com/wuwenyan/p/4982713.html
当算法的输入n非常大的时候,对于算法复杂度的分析就显得尤为重要,虽然有时我们能通过一定的方法得到较为精确的运行时间,但是很多时候,或者说绝大多数时候,我们并不值得去花精力求得多余的精度,因为精确运行时间中的倍增常量和低阶项已经被输入规模本身的影响所支配。我们需要关心的是输入规模无限增加,在极限中,运行时间是如何随着输入规模增大而增加的,通常来说,在极限情况下渐进地更优的算法在除很小的输入外的所有情况下将是最好的选择。
前提假设:本章定义的所有用在渐近记号中的函数均渐近非负(包括f(n),g(n))。
对于一个已知的函数g(n),我们定义Θ(g(n))如下:
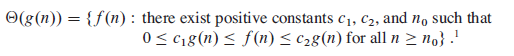
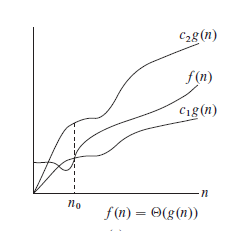
含义是:若存在常数c1和c2,使得对于足够大的n,函数f(n)能够"夹入"c1*g(n)和c2*g(n)之间,则f(n)属于集合Θ(g(n))。我们称g(n)为f(n)的一个渐近紧确界(asymptotially tight bound)。
注意:Θ(g(n))是一个函数的集合,所以如果要表示f(n)是Θ(g(n))的一员,则需写为f(n)∈Θ(g(n)),但是在很多教材中,通常使用f(n)=Θ(g(n))来表示相同的概念,这属于对于等式的一个活用。
下图形象地表示了渐近紧确界的形式:
对于一个已知的函数g(n),我们定义O(g(n))如下:
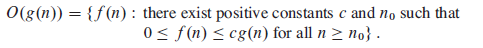
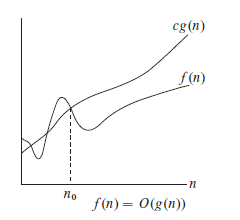
含义是:对于足够大的n,f(n)的值总小于或等于c*g(n)。我们称g(n)为f(n)的一个渐近上界(asymptotic upper bound)。
注意:在很多教材中,会发现用O(g(n))来表示一个渐近紧确界,即Θ(g(n))表示的含义,这是不准确的,在算法文献中,标准的做法是区分渐近上界和渐近紧确界。
下图形象地表示了渐近上界的形式:
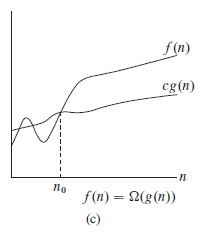
对于一个已知的函数g(n),我们定义Ω(g(n))如下:
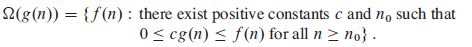
含义是:对于足够大的n,f(n)的值总大于或等于c*g(n)。我们称g(n)为f(n)的一个渐近下界(asymptotic lower bound)。
下图形象地表示了渐近下界的形式:
1.4 相互关系
对任意两个函数f(n)和g(n),我们有f(n)= Θ(g(n)),当且仅当f(n)= O(g(n))且f(n)= Ω(g(n))。
插入排序复杂度分析举例:插入排序最坏情况运行时间的界为Θ(n^2)(并不表示对每个输入的运行时间界都为Θ(n^2))。首先,插入排序的运行时间为O(n^2),这意味着最坏的运行时间为O(n^2)。其次,插入排序的运行时间为Ω(n),这意味着最好的运行时间为Ω(n)(在输入已经排序好的情况下)。
所以,插入排序的运行时间介于Ω(n)和O(n^2)之间,且是一个尽可能紧确的界,例如,不能说插入排序的运行时间是Ω(n^2),因为存在一个输入使得排序在Ω(n)内完成,然而这与插入排序最坏运行时间为Ω(n^2)(由最坏情况运行时间的界为Θ(n^2)所蕴涵)并不矛盾,因为存在一个输入使得需要Ω(n^2)的时间。
对于一个已知的函数g(n),我们定义o(g(n))如下:
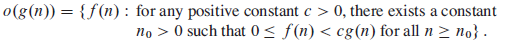
含义可以类比于O(g(n)),表示一个非紧确的上界。
对于一个已知的函数g(n),我们定义ω(g(n))如下:
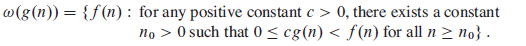
含义可以类比于Ω(g(n)),表示一个非紧确的下界。
2. 常用函数性质总结
(1)对任意整数n,存在以下性质:
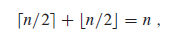
(2)对于某个常量k,如果存在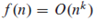 ,则称函数f(n)为多项式有界的。
,则称函数f(n)为多项式有界的。
(3)多项式与指数的增长率可以通过以下事实相关联。对于所有使得a>1的实常量a和b,有
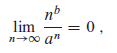
据此可知

因此,任意底大于1的指数函数增长都比多项式函数快。
(4)在(3)的第一个等式中,用lgn代替n,并用2^a代替a,可以使得多项式与多对数的增长相互关联:
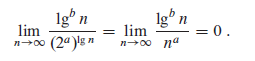
可以得到,对于任意常量a>0,有
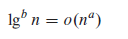
因此,任意正的多项式函数都比任意多对数函数增长快。
(5)阶乘函数的弱上界为n!<=n^n,因为在n的阶乘中,n的每项最多为n。斯特林近似公式给出了一个更紧确的上界和下界:
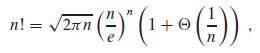
posted on 2015-11-20 23:58 EscapePlan 阅读(1942) 评论(4) 编辑 收藏 举报


