scrapy+mongodb 爬取麦田房产的信息
利用scrapy框架来抓取网站:http://bj.maitian.cn/esfall,并且用xpath解析response,并将标题、价格、面积、区等信息保存到MongoDb当中
准备工作:
1.安装scrapy
2.创建scrapy工程 maitian
3.开启mongodb服务端
items.py:


import scrapy class MaitianItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title= scrapy.Field() price = scrapy.Field() area = scrapy.Field() district = scrapy.Field()
settings.py:
ITEM_PIPELINES={'maitian.pipelines.MaitianPipeline':300,}
MONGODB_HOST='127.0.0.1'
MONGODB_PORT=27017
MONGODB_DBNAME='maitian'
MONGODB_DOCNAME='zufang'
pipelines.py:
import pymongo import settings class MaitianPipeline(object): def __init__(self): host=settings.MONGODB_HOST port= settings.MONGODB_PORT db_name = settings.MONGODB_DBNAME client=pymongo.MongoClient(host=host,port=port) db=client[db_name] self.post=db[settings.MONGODB_DOCNAME] def process_item(self, item, spider): zufang=dict(item) self.post.insert(zufang) return item
在spiders文件夹下新建一个zufang_spider.py,输入以下代码:
import scrapy import sys import os # 将 项目的根目录添加到sys.path中 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from items import MaitianItem class MaitianSpider(scrapy.Spider): name="zufang" start_urls=["http://bj.maitian.cn/esfall"] def parse(self, response): for zufang_item in response.xpath('//div[@class="list_title"]'): yield { 'title':zufang_item.xpath('./h1/a/text()').extract_first(), 'price': zufang_item.xpath('./div[@class="the_price"]/ol/strong/span/text()').extract_first(), 'area': zufang_item.xpath('./p/span[1]/text()').extract_first(), 'district': zufang_item.xpath('./p/text()').re(r'昌平|朝阳|东城|大兴|房山|丰台|海淀|门头沟|平谷|石景山|顺义|通州|西城')[0], } next_page_url=response.xpath('//div[@id="paging"]/a[@class="down_page"]/@href').extract_first() if next_page_url is not None: yield scrapy.Request(response.urljoin(next_page_url))
打开cmd:cd到maitian所在目录:scrapy crawl zufang

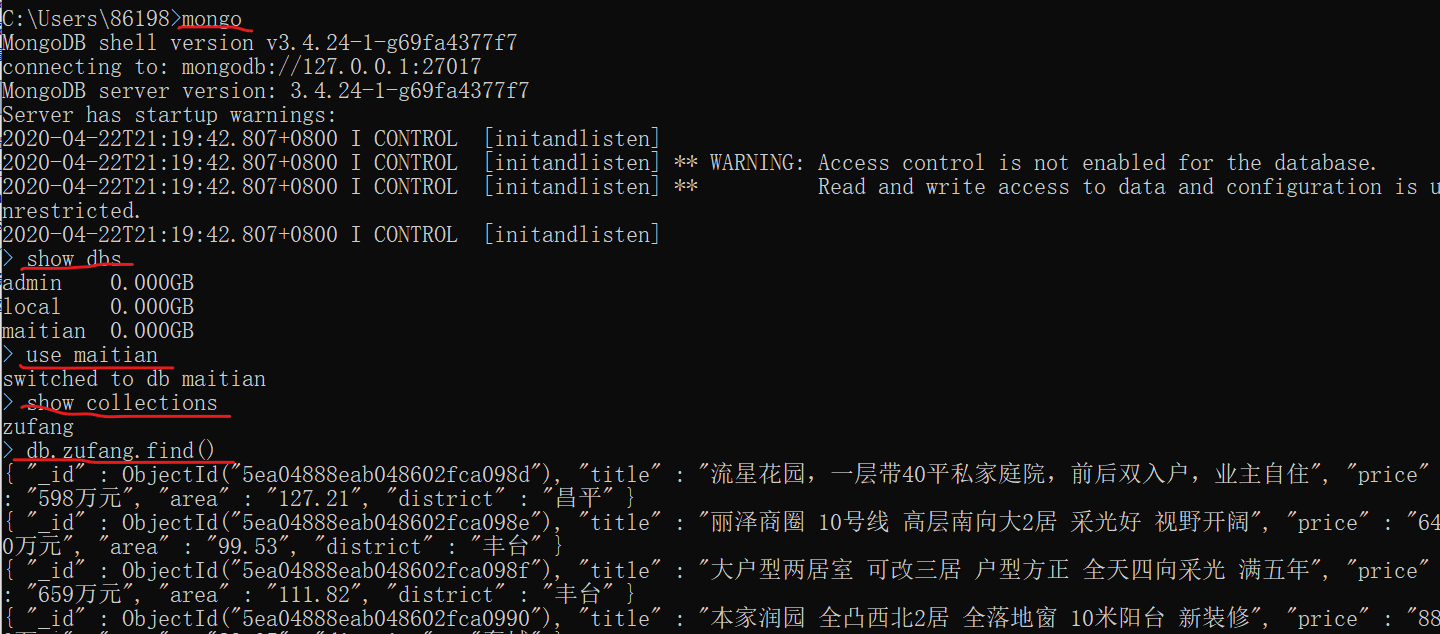
打开mongo,查看数据: