


python爬虫框架—scrapy
scrapy的架构图:
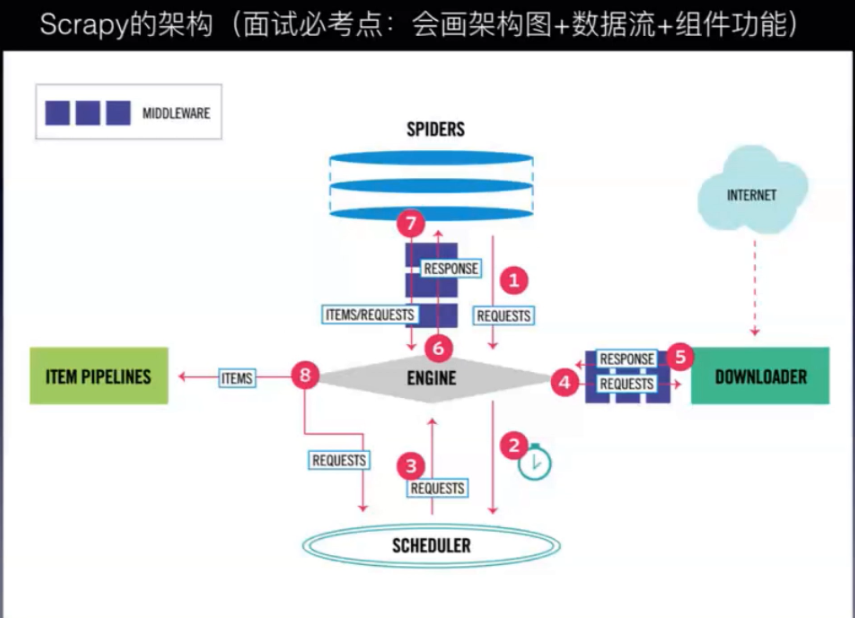
engine:引擎:控制数据流的流向
四大组件:
scheduler:调度器:处理requests,排队再返回给engine
downloader:下载器:把requests变为response再返回给engine
spiders:爬虫:解析response变为items/requests
item pipelines:数据项管道:对item做一些入库操作,也叫持久化
数据流:
1.engine从spider得到初始的requests
2.engine把初始requests传递给scheduler
3.scheduler返回给engine下一个要爬取的requests
4.engine将requests传递给downloader
5.downloader把response传递回engine
pipelines的作用:
1.清理html数据
2.做确认
3.查重
4.存入数据库
