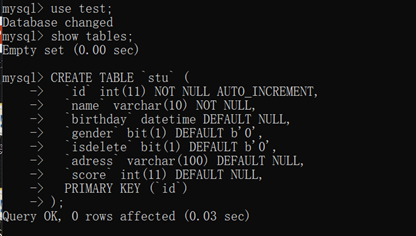
mysql使用三
ER模型关系:
不建议表与表之间建立循环的关系闭合
- 多表约束 产生关系 如果有删除修改操作,对应的关联表数据 ,就会报错
逻辑删除解决这个问题 - 先建表 在约束:
alter table scores add constraint stu foreign key(stuid) referrnces stu(id) on delete cascade
cascade:级联关系
restrict:限制关系
set null:外键置空
no action
前提:建表
在成绩表中创建两个外键,与学生表、科目表关联
create table subjects(
id int auto_increment primary key not null,
title varchar(10) not null
);
insert into subjects values (0,'语文') ,(0,'数学'),(0,'英语'),(0,'科学');
create table stu(
id int auto_increment primary key,
name varchar(10) not null,
birthday datetime,
gender bit default 0,
isdelete bit default 0,
adress varchar(100),
score int
);
(1,”小明”,”2018-01-01”,0,0,”北京”,90),
(2,”小红”,”2007-01-01”,1,0,”上海”,80),
(3,”小兰”,”2006-01-01”,1,0,”广州”,100),
(4,”小王”,”2005-01-01”,0,0,”深圳”,20),
(5,”老王”,”2009-01-01”,0,0,null,30),
(6,”老刘”,”2004-01-01”,0,0,null,40),
(7,”小丽”,”2003-01-01”,1,0,”东莞”,50),
(8,”小芳”,”2002-01-01”,1,0,”福建”,60),
(9,”小莉”,”2001-01-01”,0,0,”福州”,70);
create table scores(
id int auto_increment primary key,
stuid int,
subid int,
score decimal(5,2),
foreign key(stuid) references stu(id),
foreign key(subid) references subjects(id)
);
//decimal(5,2):用来存储精确的数值,可以存储2位小数的5位数
insert into scores values(0,1,1,80),(0,2,2,60),(0,2,3,70),(0,3,1,90),(0,4,4,60),(0,5,2,75);
链接查询:
- inner join
查询学生的名字,学科对应的成绩
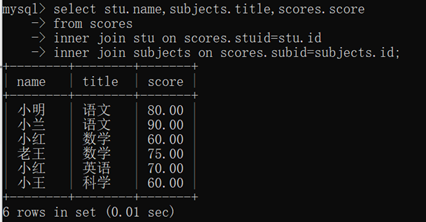
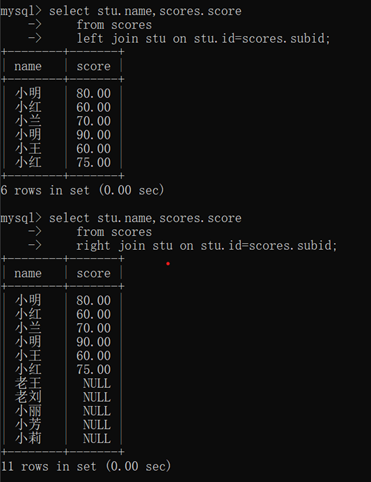
- left join:A左链接B表:查询结果以A为基准操作
- right join:A右链接B表:查询结果以B为基准操作
select *
from scores
right join stu on stu.id=scores.subid;
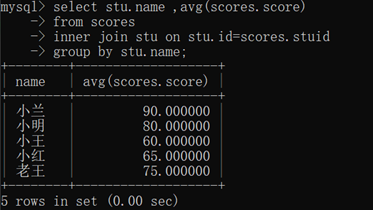
求每个人的score平均值:
求每个科目的平均分:
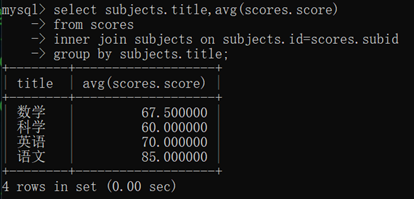
学生中id<5的最高分
select stu.name,subjects.title,Max(scores.score)
from scores
inner join stu on scores.stuid=stu.id
inner join subjects on scores.subid=subjects.id
where stu.id<5
group by stu.name;

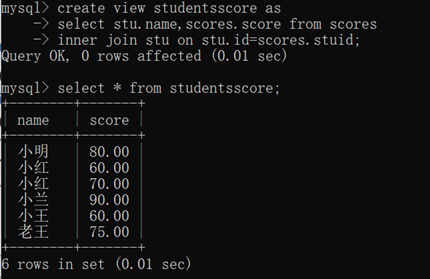
视图view:对复杂sql语句的封装
- 创建:create view 视图的名字 as sql的查询语句
- 查看视图的结果:select * from 视图名字
- 删除视图:drop view 视图名字
事务:
-
事务的四大特性:ACID
Atomic原子性:把事务看作一段程序,要么一起成功,要么一起失败,一个数据库的操作是不可分割的,只有所有的操作都成功,整个事务才提交
consistency一致性:数据库所处的状态和他的业务规则是一致的,即数据不会被破坏。如A账户转账100元到B账户,不管操作成功与否,A和B账户的存款总额是不变的。
isolation隔离性:事务和事务之间是隔离的
durability持久性: 一旦事务提交成功后,事务中所有的数据操作都必须被持久化到数据库中。即使在事务提交后,数据库马上崩溃,在数据库重启时,也必须保证能够通过某种机制恢复数据。 -
表要求类型:innodb/ddb
查看表创建语句:show create table table名字 -
开启事务:begin
-
提交事务:commit
-
事务回滚:rollback
-
开启事务就相当于在缓冲区进行一系列操作,提交后才会执行完成
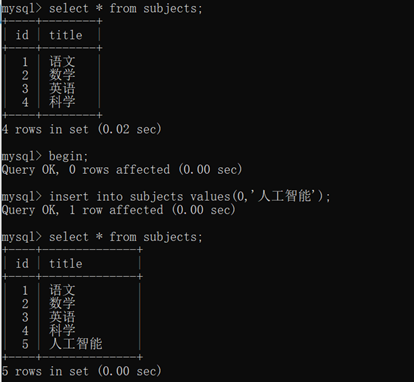
打开另一个终端,在事务没commit之前,是查询不到添加的数据的
查询效率问题:
- 索引查询:效率最高
- 提高效率:数据类型越小越好
能用整型最好
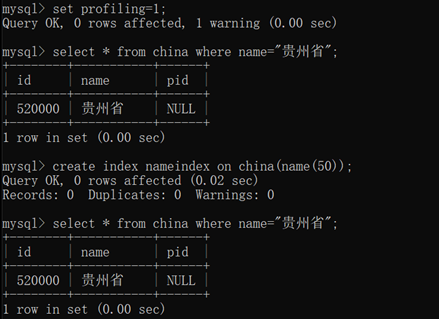
最好别用NULL,用0,或特殊符号代替 - 创建索引:create index indexname on tablename(key(length))
- 查看所有索引:show index from tablename
- 删除索引:drop index indexname on tablename
- 索引用完就删
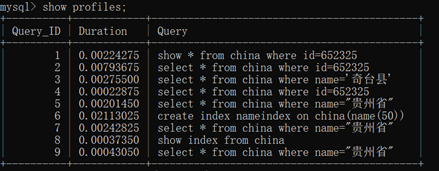
- 验证时间:set profiling=1;
- 查询完后显示时间:show profiles;
mysql的备份与恢复
备份:mysqldump -u root -p db_name table_name > 备份文件的绝对路径
恢复:mysql -u root -p db_name > 备份文件的绝对路径

恢复:必须先在数据库中创建空表,且表名与备份文件中的表名一致