


mysql使用二
数据操作:
总结:
1.只要数学表达式中有Null出现,最终结果都是Null。(所有数据库都是这样规定的)
解决:ifnull:空处理函数
ifnull(可能为null的字段,被当做什么处理) eg:ifnull(sal,0)
2.执行顺序:
select 5 选出数据
XXX
from 1
XXX
where 2 过滤
XXX
group by 3 分组
XXX
having 4 对分组数据再次过滤,不可单独存在,只会出现在group by之后
XXX
order by 6 排序
XXX
3.当一条语句中有group by的话,select后只能跟分组字段和分组函数,其他的都不行,MySQL倒不会报错,oracle一定报错
select ename,max(sal),job from emp group by job;
ename在这毫无意义,并不是最高薪资的名字,而是随机取的
4.多个字段能联合起来进行分组?
找出每个部门不同工作岗位的最高薪资?
select deptno,job,max(sal) from emp group by deptno,job;
+--------+-----------+----------+
| deptno | job | max(sal) |
+--------+-----------+----------+
| 10 | CLERK | 1300.00 |
| 10 | MANAGER | 2450.00 |
| 10 | PRESIDENT | 5000.00 |
| 20 | ANALYST | 3000.00 |
| 20 | CLERK | 1100.00 |
| 20 | MANAGER | 2975.00 |
| 30 | CLERK | 950.00 |
| 30 | MANAGER | 2850.00 |
| 30 | SALESMAN | 1600.00 |
+--------+-----------+----------+
前提:
-
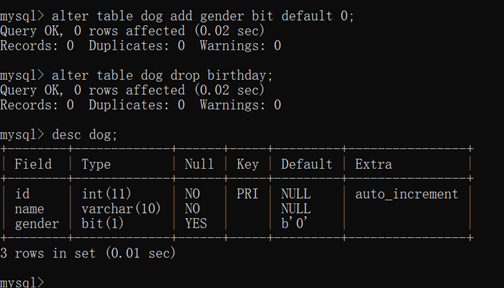
插入数据:缺省插入,
查看表的所有数据
-
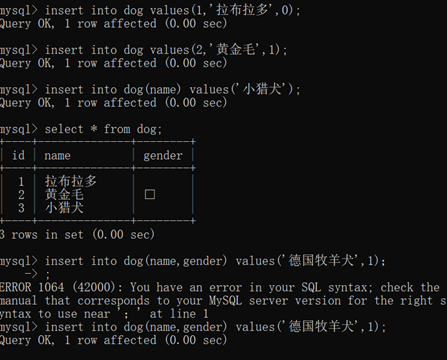
插入多条数据;
primary自增的操作:全列插入的时候写个0占位:insert into dog values(0,'秋田犬',1,0);


-
修改数据:where+筛选条件
mysql> update dog set name="泰迪" where id=8; -
删除数据:
物理删除:delete from dog where id=4;
逻辑删除:增加一个字段isdelete,通过设置这个字段的值来表明数据删没删
alter table dog add isdelete bit default 0;
update dog set isdelete=1 where id=2;
isdelete值为1的表明删除了
查询操作:
准备:
create table stu(
id int auto_increment primary key,
name varchar(10) not null,
birthday datetime,
gender bit default 0,
isdelete bit default 0,
adress varchar(100),
score int
);
(1,”小明”,”2018-01-01”,0,0,”北京”,90),
(2,”小红”,”2007-01-01”,1,0,”上海”,80),
(3,”小兰”,”2006-01-01”,1,0,”广州”,100),
(4,”小王”,”2005-01-01”,0,0,”深圳”,20),
(5,”老王”,”2009-01-01”,0,0,null,30),
(6,”老刘”,”2004-01-01”,0,0,null,40),
(7,”小丽”,”2003-01-01”,1,0,”东莞”,50),
(8,”小芳”,”2002-01-01”,1,0,”福建”,60),
(9,”小莉”,”2001-01-01”,0,0,”福州”,70);

条件查询执行顺序:先from ,然后where,最后select
-
条件运算 =、> < >= <= !=/<>
-
逻辑运算:and or not
-
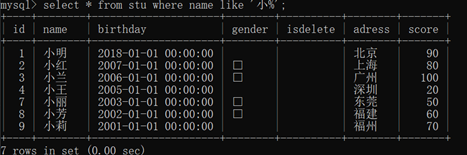
模糊查询:like select * from table_name where 字段 like “模糊值”
%:任意多个字符、_:表示任意一个字符
-
范围查询:
in后面的值可不是表示一个区间。
in:表示一个非连续的范围 not in
between 范围1 and 范围2:表示一个连续的范围

-
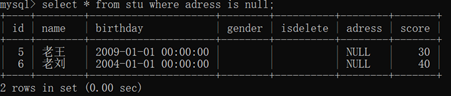
判断空:null 注意:空字符串不是null
-
查询符号的优先级:() not 条件运算 and/or
-
聚合查询:
分组函数:通常和group by联合使用,一共5个,又称多行处理函数:输入多行,最终输出一行,
分组函数自动忽略Null,不统计它,所以不用考虑这种情况:只要数学表达式中有Null出现,最终结果都是Null。
不用添加过滤条件:where sal is not null; sum函数自动忽略null了。
分组函数不可直接使用在where子句中:因为group by在where执行后才执行
找出工资高于平均工资的员工?
select ename,sal from emp where sal>avg(sal); 报错:错误的使用了分组函数
count() count(comm)的区别?
count():统计的是总记录条数
count(comm):统计的是这个字段中不为null的数据元素个数
统计个数:count() select count() from stu where 查询条件
列的最大值:Max()
列的最小值:Min()
列求和:sum()
列的平均值:avg() isdelete=0;女生的编号的平均值

-
分组查询:分组的依据:group by
as:给查询结果的列重命名,as关键字可以省略,以空格分隔
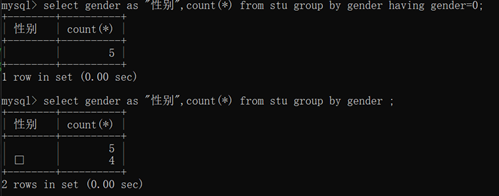
男生女生的总数 select gender as “别名”,count() from stu group by gender;
分组之后继续筛选:having
男生的总人数:——select count() from stu where gender=0;
——select gender as “性别”,count(*) from stu group by gender having gender =0;
where和having的区别:where:原始数据筛选
having:分组结束之后, group by
-
排序:order by字段:asc——升序、desc——降序
没被删除的人按score进行排序:select * from stu where isdelete=0 order by score;
默认升序 其后加desc是降序
越靠前的字段起主导作用。
先按分数升序排,当分数相同时,按名字的降序排:select * from stu order by score asc,name desc; -
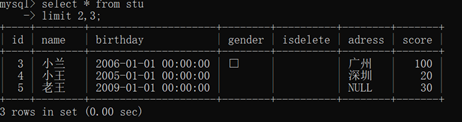
分页:limit start count
limit:若只写了一个数字,则表示从0开始取几个
-
去重:列中的内容 distinct
select distinct name from stu;
mysql> select ename,distinct job from emp; 报错
mysql> select distinct job,ename from emp; 对的
distinct只能出现在所有字段的最前面,
