
Keepalive原理总结
什么是keepalived呢?keepalived是实现高可用的一种轻量级的技术手段,主要用来防止单点故障(单点故障是指一旦某一点出现故障就会导致整个系统架构的不可用)的发生。
1. VRRP
VRRP是一种容错性协议,它是通过将多台设备虚拟化成一台设备,如果其中一台设备出现故障,那么另一台设备可以迅速接替其工作,已保证通讯的可靠性和连续性。
1.1. 工作原理
在企业网当中,PC一般是需要使用"网关"来与外部网络进行通讯,这样如果网关出现了故障那么整一个子网的对外通讯都会被切断,VRRP的出现就能把这个问题很好地解决了,VRRP可以通过把多台设备(路由器、交换机、防火墙等)虚拟化成一台设备,然后通过配置虚拟IP地址作为网关就能实现对网关的备份(这虚拟IP地址是代表整个VRRP组内的所有设备),当其中一台设备出现故障之后,VRRP组内其他设备会通过某些机制来接替故障设备的工作。

如上图所示,SW7和SW8若配置了VRRP 那么SW7和SW8就是一个整体,其中一台出现故障都不会对业务造成很大的影响。
1.1.1. VRRP概念
虚拟设备:由一个"主(Master)"设备和多个"备(Backup)"设备组成的一个虚拟网关。
主设备(Master):负责转发数据报文和周期性向备设备发送VRRP协议报文。
备设备(Backup):不负责转发数据报文,在Master设备发生故障的时候会通过选举形式成为新的Master设备,该角色会接收来自Master设备的VRRP报文并加以分析。
VRID:用来表示一个VRRP组。
虚拟IP:配置在虚拟设备上的虚拟IP地址,一个虚拟设备可以拥有一个或者多个虚拟IP地址。
IP地址拥有者:分配给虚拟设备的虚拟IP的真实拥有者(例如:分配个虚拟路由的IP为192.168.1.1,但是这个IP已经分配给物理接口G0/0/1这个接口那么这个接口就是"IP拥有者"),IP拥有者会直接跳过选举成为Master,并且是不可抢占的。
虚拟MAC地址:由虚拟设备生成的虚拟MAC地址,每一个虚拟设备都会自动生成一个虚拟MAC地址,这个MAC地址是用于虚拟设备处理ARP报文的。
优先级:用于表示物理设备的优先级,这个参数用于Master的选举,取值范围是1-254,这个有优先级有两个比较特殊的值,分别是0和255,优先级0是由原来Master设备发送的,这个优先级是声明此设备不再参与VRRP组。优先级为255的是IP拥有者的优先级,拥有这个优先级会直接成为Master。(优先级数值越低优先级则越高)
抢占模式:当Backup 设备接收到的VRRP报文通过分析得出当前Master设备的优先级低于Backup设备,则Backup设备会切换为Master设备。
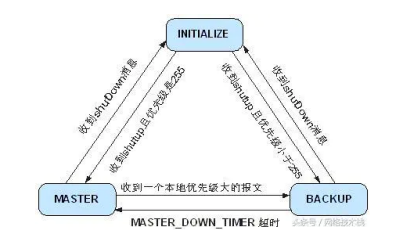
1.1.2. VRRP状态机
VRRP一共有三种状态,分别是:初始状态(Initialize)、活动状态(Master)、备份状态(Backup)。
初始状态:在这个状态下VRRP是不可用的,在这个状态下的设备是不会处理VRRP报文的,通常是刚配置VRRP时和检测到故障是会是这个状态。
活动状态:处于Master状态下的设备将会做下列工作:
- 定期发送VRRP报文。
- 以虚拟MAC地址响应对虚拟IP地址的ARP请求。
- 转发目的MAC地址为虚拟MAC地址的IP报文。
- 如果它是这个虚拟IP地址的拥有者,则接收目的IP地址为这个虚拟IP地址的IP报文。否则,丢弃这个IP报文。
- 如果收到比自己优先级大的报文则转为Backup状态。
- 如果收到优先级和自己相同的报文,并且发送端的IP地址比自己的IP地址大,则转为Backup状态。
- 当接收到接口的Shutdown事件时,转为Initialize。
备份状态:处于Backup状态下的设备,它将会做下列工作:
- 接收Master发送的VRRP报文,判断Master的状态是否正常。
- 对虚拟IP地址的ARP请求,不做响应。
- 丢弃目的MAC地址为虚拟MAC地址的IP报文。
- 丢弃目的IP地址为虚拟IP地址的IP报文。
- Backup状态下如果收到比自己优先级小的报文时,丢弃报文,立即切换为Master(仅在抢占模式下生效)。
- 如果收到优先级和自己相同或者比自己高的报文,则重置定时器,不进一步比较IP地址。
- 当接收到接口的Shutdown事件时,转为Initialize。
- 如果MASTER_DOWN_INTERVAL定时器超时,则切换为Master。
三种状态机的关系如下图:
1.2. 工作流程
VRRP备份组会通过优先级选举出Master,Master会使用虚拟MAC发送ARP报文,使与Master连接的主机或者客户端建立与虚拟MAC对应的ARP映射表,同时Master会周期性发布VRRP报文向所有Backup通告其配置信息与工作状态。
如果当前Master出现故障,Backup设备将会在MASTER_DOWN_INTERVAL定时器超时或者其他联动技术检测到Master出现故障时则会根据Backup组内的成员的优先级选举出新的Master,如果Backup只有一台设备则直接成为Master。
新的Master使用虚拟MAC发送ARP报文,使连接在当前VRRP组内的客户端或者设备刷新其ARP映射表。
如果原来的Master从故障中恢复过来,如果其优先级为255则会直接切换到Master,若不是则会恢复到Backup状态,如果当前为抢占模式,当原Master接收到新Master的VRRP报文发现其优先级高于原Master则原Master会直接成为Master。如果处于非抢占模式,则原Master会在新Master出现故障时通过选举等方式成为Master。
1.2.1. VRRP选举
VRRP通过优先级来确定设备成为Master或者Backup,优先级取值越低,则优先级越高。
初始创建的VRRP设备都处于初始状态,在该状态下,如果设备的优先级为255,则直接成为Master并且跳过接下来的选举,若不是则会切换到Backup状态,然后会等待MASTER_DOWN_INTERVAL超时后成为Master。
首先切换到Master的设备会通过VRRP报文获取其他设备的优先级,然后通过以下规则进行选举:
- 如果Backup设备接收到来自Master的VRRP报文,发现其优先级数值低于自身,则继续处于Backup状态。
- 如果Backup设备接收到来自Master的VRRP报文,发现其优先级数值高于自身,则当前Backup设备会切换到Master,而原Master设备会切换到Backup。如果在非抢占模式下,Backup设备仍然会处于Backup状态。
- 如果同时有多个设备切换到Master,则会互相通过VRRP报文确定其优先级,优先级高的则成为Master,若优先级一样,则对比IP地址,IP地址大的则成为Master。
1.2.2. VRRP状态通告
Master设备会周期性发送VRRP报文,通告其配置信息与工作状态,Backup则会接收并处理VRRP报文确定Master设备的工作状态。
当Master主动退出VRRP组是,会发送优先级为0的报文通知所有的Backup设备,Backup设备接收到之后会直接切换到Master状态,若Backup组内有多台设备则通过上述选举选出新的Master设备,而不需要等待MASTER_DOWN_INTERVAL超时后再进行切换或者选举。
当Master设备由于故障不能发送VRRP报文,所有的Backup设备都需要等待MASTER_DOWN_INTERVAL 超时后才会认为Master设备出现故障,之后才切换到Master。
1.2.3. VRRP两种模式
1、 主备备份模式
主备备份模式就是只由Master设备负责转发数据,而Backup设备则处于待机备份模式不参与数据转发,当Master设备出现故障时才会切换到Master进行数据转发。
参照下图,正常情况下只有SW1转发数据,而SW2则处于待机状态,SW1会周期发送VRRP报文告知SW2自身的配置信息和工作状态,如果SW1发生故障,则SW2会自动切换到到Master继续进行数据转发等。
而当SW1恢复之后,若当前为抢占模式,若SW1的优先级为255那么SW1会直接成为Master否则会先切换到Backup然后再切换到Master。
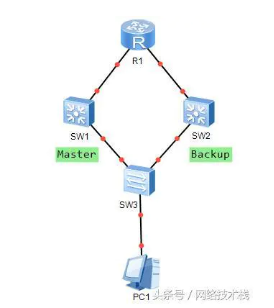
主备模式
2、 负载分担模式
上述的主备备份模式,若SW1一直正常工作,那么SW2则长期处于待机状态,显然这种做法比较浪费,所以一般会采用负载分担模式,负载分到模式会是SW2都处于工作状态。
参照下图,负载分担模式是创建两个VRRP组分别为A组和B组,A组的Master为SW1,Backup为SW2,而B组的Master为SW2,Backup为SW1,通过创建多个拥有不同虚拟IP的VRRP组,为不同的VLAN指定网关实现负载分担。
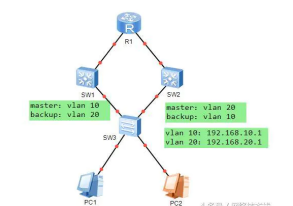
负载分担模式
参照上图,在VLAN10当中Master是SW1,Backup为SW2,两台交换机都分别创建vlan10和vlan20 并且分配好IP地址,正常情况下vlan10的客户端会通过SW1访问R1,vlan20的客户端会通过SW2访问R1这样就实现了负载分担,如果SW1出现故障,那么SW2会成为vlan10的Master(同时也是vlan20的Master),接替SW1的工作,而vlan10的客户端也会通过SW2访问R1,而SW2故障则同理。
2. Keepalived
2.1. 配置说明
keepalived的配置位于/etc/keepalived/keepalived.conf,配置文件格式包含多个必填/可选的配置段,部分重要配置含义如下:
#全局定义块,定义主从切换时通知邮件的SMTP配置
global_defs {
#邮件告警列表
notification_email {
897807300@qq.com
}
#指定发件人
notification_email_from keepalived@localhost
#指定smtp服务器地址
smtp_server 127.0.0.1
#指定smtp连接超时时间
smtp_connect_timeout 30
#负载均衡标识,在局域网内应该是唯一的
router_id waf_lvs_master_01
}
#作用:添加一个周期性执行的脚本。脚本的退出状态码会被调用它的所有的VRRP Instance记录。
#注意:至少有一个VRRP实例调用它并且优先级不能为0.优先级范围是1-254.
vrrp_script chk_nginx
{
script "/home/check.sh"
#重试次数
interval 3
#范围[-254到254]
weight -50
}
vrrp_instance VI_1 {
#实例角色。分为一个MASTER和一(多)个BACKUP。
state BACKUP
#绑定VIP的网络接口
interface eth0
#标识虚拟路由的ID号,两个节点设置必须一样,有效范围为0-255
virtual_router_id 230
#节点优先级,值范围0~254,MASTER>BACKUP
priority 90
#组播信息或者VRRP协议发送时间间隔,两个节点必须设置一样,默认为1秒
advert_int 5
#设置验证信息,两个节点必须一致
authentication {
auth_type PASS
auth_pass 1111
}
#虚拟IP(VIP),两个节点设置必须一致,可以设置多个
virtual_ipaddress {
172.26.130.184
}
#存活状态检测脚本
track_script {
chk_nginx
}
}
virtual_server 172.26.130.184 80 {
#健康检查的时间间隔
delay_loop 60
#rr|wrr|lc|wlc|lblc|sh|dh:LVS调度算法
lb_algo rr
#LVS模式(NAT|DR|TUN)
lb_kind DR
nat_mask 255.255.255.0
#持久化超时时间,单位是秒。默认是6分钟
persistence_timeout 50
#4层协议TCP|UDP|SCTP
protocol TCP
real_server 172.26.130.109 80 {
#给服务器指定权重
weight 50
TCP_CHECK { # 通过TcpCheck判断RealServer的健康状态,其他SMTP_CHECK支持SMTP和DNS_CHECK支持DNS
connect_timeout 10 # 连接超时时间
nb_get_retry 3 # 重连次数
delay_before_retry 3 # 重连时间间隔
connect_port 80 # 检测端口
}
}
real_server 172.26.130.126 80 {
weight 50
TCP_CHECK { # 通过TcpCheck判断RealServer的健康状态
connect_timeout 10 # 连接超时时间
nb_get_retry 3 # 重连次数
delay_before_retry 3 # 重连时间间隔
connect_port 80 # 检测端口
}
}
}
2.2. vrrp_script详解
1、vrrp_script能做什么
keepalived只能做到对网络故障和keepalived本身的监控,即当出现网络故障或者keepalived本身出现问题时,进行切换。但是这些还不够,我们还需要监控keepalived所在服务器上的其他业务进程,比如说nginx,keepalived+nginx实现nginx的负载均衡高可用,如果nginx异常,仅仅keepalived保持正常,是无法完成系统的正常工作的,因此需要根据业务进程的运行状态决定是否需要进行主备切换。这个时候,我们可以通过编写脚本对业务进程进行检测监控。
例如:编写个简单脚本查看haproxy进程是否存活
#!/bin/bash
count = `ps aux | grep -v grep | grep haproxy | wc -l`
if [ $count > 0 ]; then
exit 0
else
exit 1
fi
在keepalived的配置文件中增加相应配置项
vrrp_script checkhaproxy
{
script "/home/check.sh"
interval 3
weight -20
}
vrrp_instance test
{
...
track_script
{
checkhaproxy
}
...
}
2、优先级更新策略
keepalived会定时执行脚本并对脚本执行的结果进行分析,动态调整vrrp_instance的优先级。
如果脚本执行结果为0,并且weight配置的值大于0,则优先级相应的增加 ;如果脚本执行结果非0,并且weight配置的值小于0,则优先级相应的减少
其他情况,维持原本配置的优先级,即配置文件中priority对应的值。
这里需要注意的是:
1) 优先级不会不断的提高或者降低
2) 可以编写多个检测脚本并为每个检测脚本设置不同的weight
3) 不管提高优先级还是降低优先级,最终优先级的范围是在[1,254],不会出现优先级小于等于0或者优先级大于等于255的情况
这样可以做到利用脚本检测业务进程的状态,并动态调整优先级从而实现主备切换。
3、vrrp_script中节点权重改变算法
在Keepalived集群中,其实并没有严格意义上的主、备节点,虽然可以在Keepalived配置文件中设置“state”选项为“MASTER”状态,但是这并不意味着此节点一直就是Master角色。控制节点角色的是Keepalived配置文件中的“priority”值,但并它并不控制所有节点的角色,另一个能改变节点角色的是在vrrp_script模块中设置的“weight”值,这两个选项对应的都是一个整数值,其中“weight”值可以是个负整数,一个节点在集群中的角色就是通过这两个值的大小决定的。
3.1、不设置weight
在vrrp_script模块中,如果不设置“weight”选项值,那么集群优先级的选择将由Keepalived配置文件中的“priority”值决定,而在需要对集群中优先级进行灵活控制时,可以通过在vrrp_script模块中设置“weight”值来实现。
3.2、设置weight
vrrp_script 里的script返回值为0时认为检测成功,其它值都会当成检测失败;weight 为正时,脚本检测成功时此weight会加到priority上,检测失败时不加.
主失败:
主 priority < 从 priority + weight 时会切换。
主成功:
主 priority + weight > 从 priority + weight 时,主依然为主
weight 为负时,脚本检测成功时此weight不影响priority,检测失败时priority – abs(weight)
主失败:
主 priority – abs(weight) < 从priority 时会切换主从
主成功:
主 priority > 从priority 主依然为主
4、配置不抢占nopreempt带来的问题
例如:A,B两台keepalived
A的配置大概为:
vrrp_script checkhaproxy
{
script "/etc/check.sh"
interval 3
weight -20
}
vrrp_instance test
{
....
state backup
priority 80
nopreempt
track_script
{
checkhaproxy
}
....
}
B的配置大概为:
vrrp_script checkhaproxy
{
script "/etc/check.sh"
interval 3
weight -20
}
vrrp_instance test
{
....
state backup
priority 70
track_script
{
checkhaproxy
}
....
}
A,B同时启动后,由于A的优先级较高,因此通过选举会成为master。当A上的业务进程出现问题时,优先级会降低到60。此时B收到优先级比自己低的vrrp广播包时,将切换为master状态。那么当B上的业务出现问题时,优先级降低到50,尽管A的优先级比B的要高,但是由于设置了nopreempt,A不会再抢占成为master状态。
所以,可以在检测脚本中增加杀掉keepalived进程(或者停用keepalived服务)的方式,做到业务进程出现问题时完成主备切换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号