Python Flask+Pandas读取excel显示到html网页: 环境搭建、显示内容
前言全局说明
环境搭建显示内容
一、安装flask模块
二、引用模块
三、启动服务
模块安装、引用模块、启动Web服务方法,参考下面链接文章:
https://www.cnblogs.com/wutou/p/17963563
Pandas 安装
https://www.cnblogs.com/wutou/p/17811839.html
Pandas 官方API说明
https://pandas.pydata.org/pandas-docs/stable/reference/index.html
修改内容后,要重启 flask 服务,修改才能生效
四、环境搭建
4.1.2文件名:index.py
from flask import Flask
app=Flask(__name__)
@app.route("/excel_to_html")
def excel_to_html():
if request.method == 'GET':
## 读取EXCEL文件
df = pd.read_excel('e_to_h.xlsx')
#df = pd.read_excel('doc/e_to_h.xlsx')
#df = pd.read_excel(r'/home/q/temp/e_to_h.xlsx')
#df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
## 转为html表格
htm_table= df.to_html(index=False)
## 渲染模板
return render_template('e_to_h.html')
if __name__ == '__main__':
# app.debug = True
# app.run(host='127.0.0.1',port = 5000)
app.run(host='0.0.0.0',port = 5000)
e_to_h.xlsx 放到和 index.py 同目录下,可以指定绝对路径和相对路径、网络路径
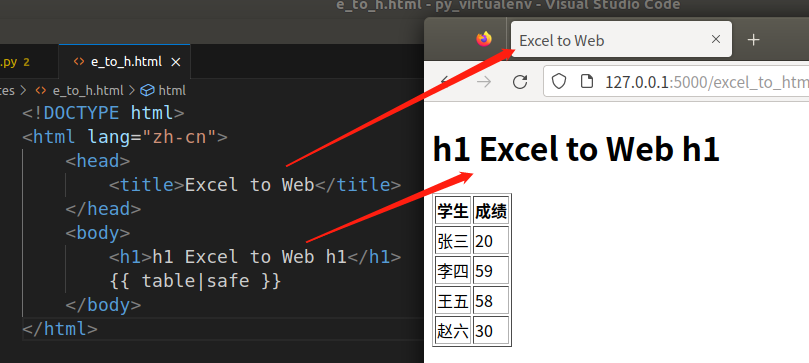
4.1.2 文件名:templates/index.html
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<title>Excel to Web</title>
</head>
<body>
<h1>h1 Excel to Web h1</h1>
{{ table|safe }}
</body>
</html>
|safe过滤器被用来告诉Jinja2这个字符串是安全的,不应该被自动转义。
4.2 访问连接:
http://127.0.0.1:5000/excel_to_html
4.3 效果:
五、函数说明
5.1.1 read_excel函数
能够读取的格式包含:xls, xlsx, xlsm, xlsb, odf, ods 和 odt 文件扩展名。支持读取单一sheet或几个sheet。
以下是官方文档中提供的全部参数信息:
pandas.read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=None,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
decimal='.',
comment=None,
skipfooter=0,
convert_float=None,
mangle_dupe_cols=True,
storage_options=None
)
常用参数的含义:
io:文件路径,支持 str, bytes, ExcelFile, xlrd.Book, path object, or file-like object。默认读取第一个sheet的内容。案例:"/desktop/student.xlsx"
sheet_name:sheet表名,支持 str, int, list, or None;默认是0,索引号从0开始,表示第一个sheet。案例:sheet_name=1, sheet_name="sheet1",sheet_name=[1,2,"sheet3"]。None 表示引用所有sheet
header:表示用第几行作为表头,支持 int, list of int;默认是0,第一行的数据当做表头。header=None表示不使用数据源中的表头,Pandas自动使用0,1,2,3…的自然数作为索引。
names:表示自定义表头的名称,此时需要传递数组参数。
index_col:指定列属性为行索引列,支持 int, list of int, 默认是None,也就是索引为0,1,2,3等自然数的列用作DataFrame的行标签。如果传入的是列表形式,则行索引会是多层索引
usecols:待解析的列,支持 int, str, list-like, or callable ,默认是 None,表示解析全部的列。
dtype:指定列属性的字段类型。案例:{‘a’: np.float64, ‘b’: np.int32};默认为None,也就是不改变数据类型。
engine:解析引擎;可以接受的参数有"xlrd"、"openpyxl"、"odf"、"pyxlsb",用于使用第三方的库去解析excel文件
“xlrd”支持旧式 Excel 文件 (.xls)
“openpyxl”支持更新的 Excel 文件格式
“odf”支持 OpenDocument 文件格式(.odf、.ods、.odt)
“pyxlsb”支持二进制 Excel 文件
converters:对指定列进行指定函数的处理,传入参数为列名与函数组成的字典,和usecols参数连用。key 可以是列名或者列的序号,values是函数,可以自定义的函数或者Python的匿名lambda函数
skiprows:跳过指定的行(可选参数),类型为:list-like, int, or callable
nrows:指定读取的行数,通常用于较大的数据文件中。类型int, 默认是None,读取全部数据
na_values:指定列的某些特定值为NaN
keep_default_na:是否导入空值,默认是导入,识别为NaN
5.1.2
5.2 访问连接:
5.3 效果:
免责声明:本号所涉及内容仅供安全研究与教学使用,如出现其他风险,后果自负。
参考、来源:
https://wenku.csdn.net/answer/07fe679e0b644bdc9ce05d05deeeb34b
https://www.zhihu.com/question/595348912/answer/3034106246
https://cloud.tencent.com/developer/article/1853145
https://blog.csdn.net/weixin_43894455/article/details/127547173 (读取网络路径文件)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号