Python模块之urllib url链接合并、拆分编码
模块作用简介:
Python模块之urllib url编码
官方 简体中文 帮助:https://docs.python.org/zh-cn/3.8/library/urllib.html
官方 英文 帮助:https://docs.python.org/3/library/
官方 简体中文 帮助:https://docs.python.org/zh-cn/3/library/
必要操作:
>>> import urllib
安装:
python3 内置函数,无需安装
如果像在py3里装py2的版本,需要指定版本号
例如:pip install urllib3==1.23
导入包:
>>> import urllib
帮助查看:
>>> help(urllib)
或 单独查看某个子方法(函数)
>>> help(urllib.parse)
>>> help(urllib.parse.urlencode)
方法(函数):
>>>
参数
返回值
返回True,否则返回False。
使用示例:
示例1:
1.1 合并
将字典转成url参数格式(用&分割的参数)
>>> from urllib.parse import urlencode
>>> params = { 'user': 'admin', 'pwd': '123456'}
>>> print(urlencode(params))

1.2 拆分
将带&部分的内容,放到字典中
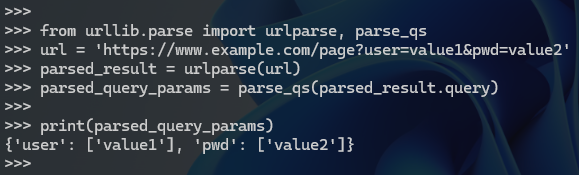
>>> from urllib.parse import urlparse, parse_qs
>>> url = 'https://www.example.com/page?user=value1&pwd=value2'
>>> parsed_result = urlparse(url)
>>> parsed_query_params = parse_qs(parsed_result.query)
>>> print("\n拆分带&链接后:\n\t", parsed_query_params)
示例2: urlparse 拆分、合并
文件名: test_url_urllib_parse_urlparse.py
#!/usr/bin/env python3
#coding: UTF-8
# -*- coding: UTF-8 -*-
from urllib.parse import urlparse, urlunparse
# 输入一个URL
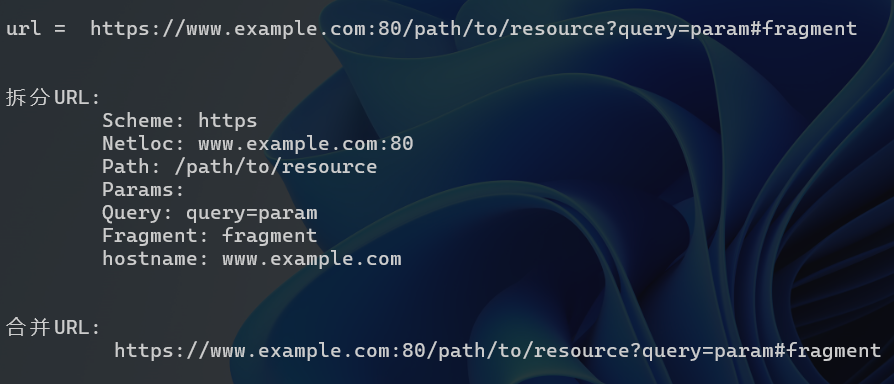
url = "https://www.example.com:80/path/to/resource?query=param#fragment"
print("\n\nurl = ", url)
# 使用 urlparse 拆分URL
print("\n\n拆分URL:")
parsed_result = urlparse(url)
print("\tScheme:", parsed_result.scheme)
print("\tNetloc:", parsed_result.netloc)
print("\tPath:", parsed_result.path)
print("\tParams:", parsed_result.params)
print("\tQuery:", parsed_result.query)
print("\tFragment:", parsed_result.fragment)
print("\thostname:", parsed_result.hostname)
# 使用 urlunparse 合并URL
print("\n\n合并URL:")
unparsed_result = urlunparse(parsed_result)
print("\t", unparsed_result)
示例3: urlunsplit 拆分、合并
文件名: test_url_urllib_parse_urlsplit.py
#!/usr/bin/env python3
#coding: UTF-8
# -*- coding: UTF-8 -*-
from urllib.parse import urlsplit, urlunsplit
# 输入一个URL
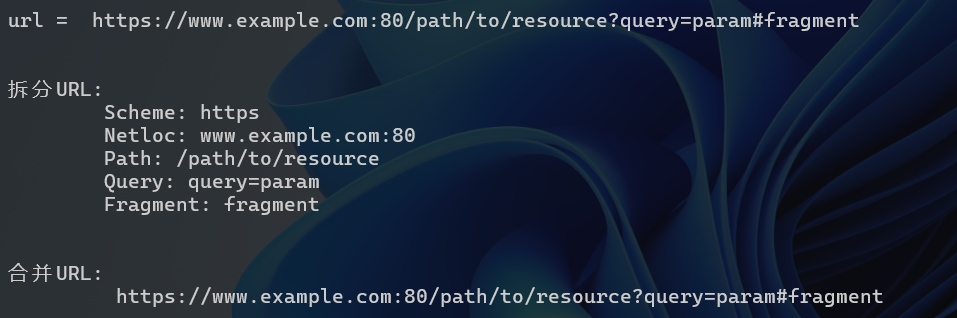
url = "https://www.example.com:80/path/to/resource?query=param#fragment"
print("\n\nurl = ", url)
# 使用 urlsplit 拆分URL
print("\n\n拆分URL:")
split_result = urlsplit(url)
print("\tScheme:", split_result.scheme)
print("\tNetloc:", split_result.netloc)
print("\tPath:", split_result.path)
print("\tQuery:", split_result.query)
print("\tFragment:", split_result.fragment)
# 使用 urlunsplit 合并URL
unsplit_result = urlunsplit(split_result)
print("\n\n合并URL:")
print("\t", unsplit_result)
相关文章:
Python安装包下载:https://www.cnblogs.com/wutou/p/17709685.html
Pip 源设置:https://www.cnblogs.com/wutou/p/17531296.html
pip 安装指定版本模块:https://www.cnblogs.com/wutou/p/17716203.html
【汇总】Python模块 - 总目录 https://www.cnblogs.com/wutou/p/15610071.html
参考、来源:
2024-02-28_路飞_大型网站反爬策略揭秘&逆向实战-Day03 01:28:40
百度AI生成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号