
爬取简书思路:
1)使用selenium模拟浏览器打开网页
2)由于分页是通过点击【阅读更多】按钮来加载数据的,因此需要模拟单击该按钮
3)确定要爬取多少页的数据,如果要爬取10页的数据,就需要模拟单机10次【阅读更多】按钮
4)单击该按钮后,需要定位这个信息列表元素,然后使用xpath提取数据
5)提取到该数据之后,将它保存到mysql数据库中
第一个错误
第二个错误
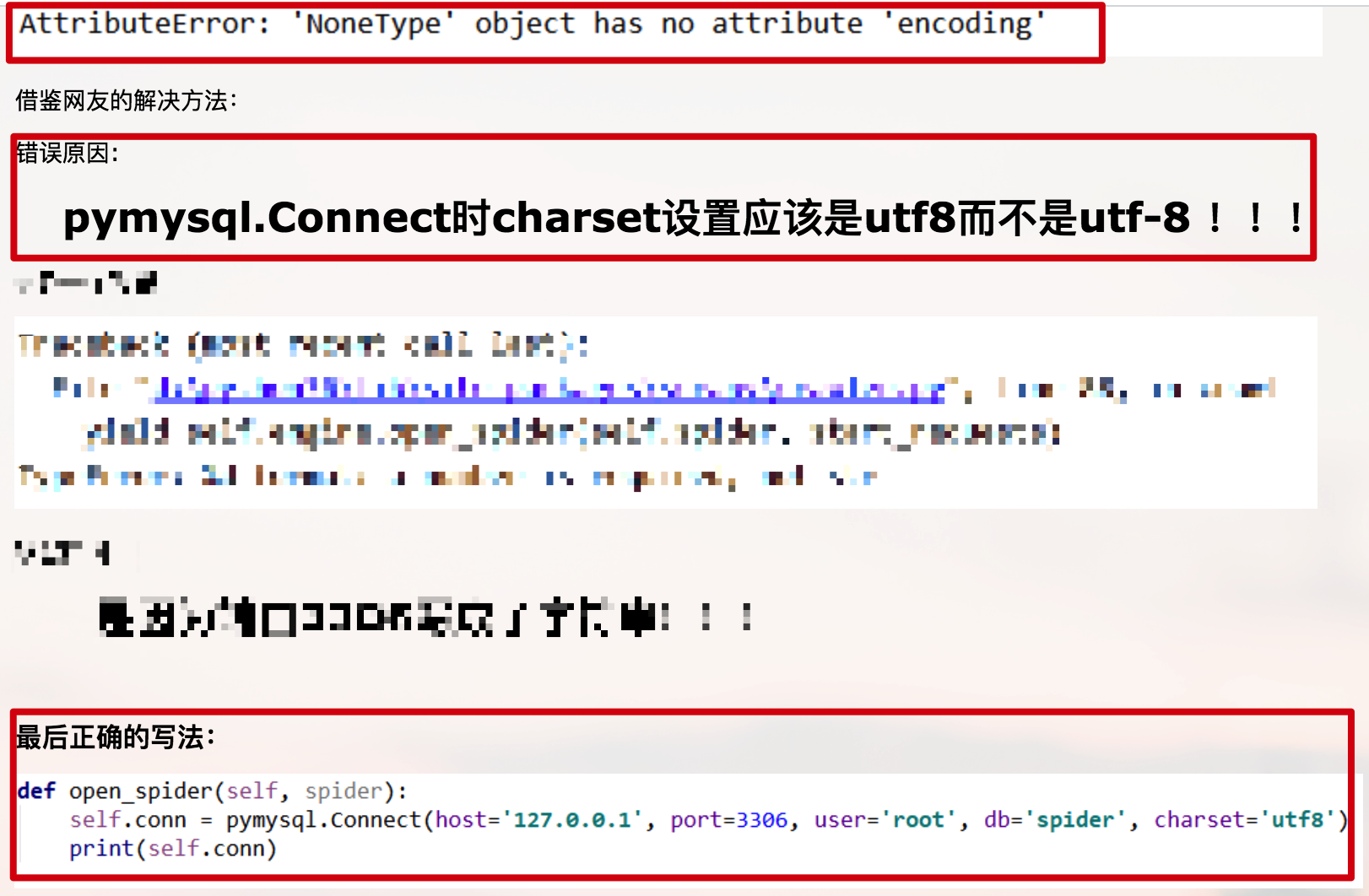
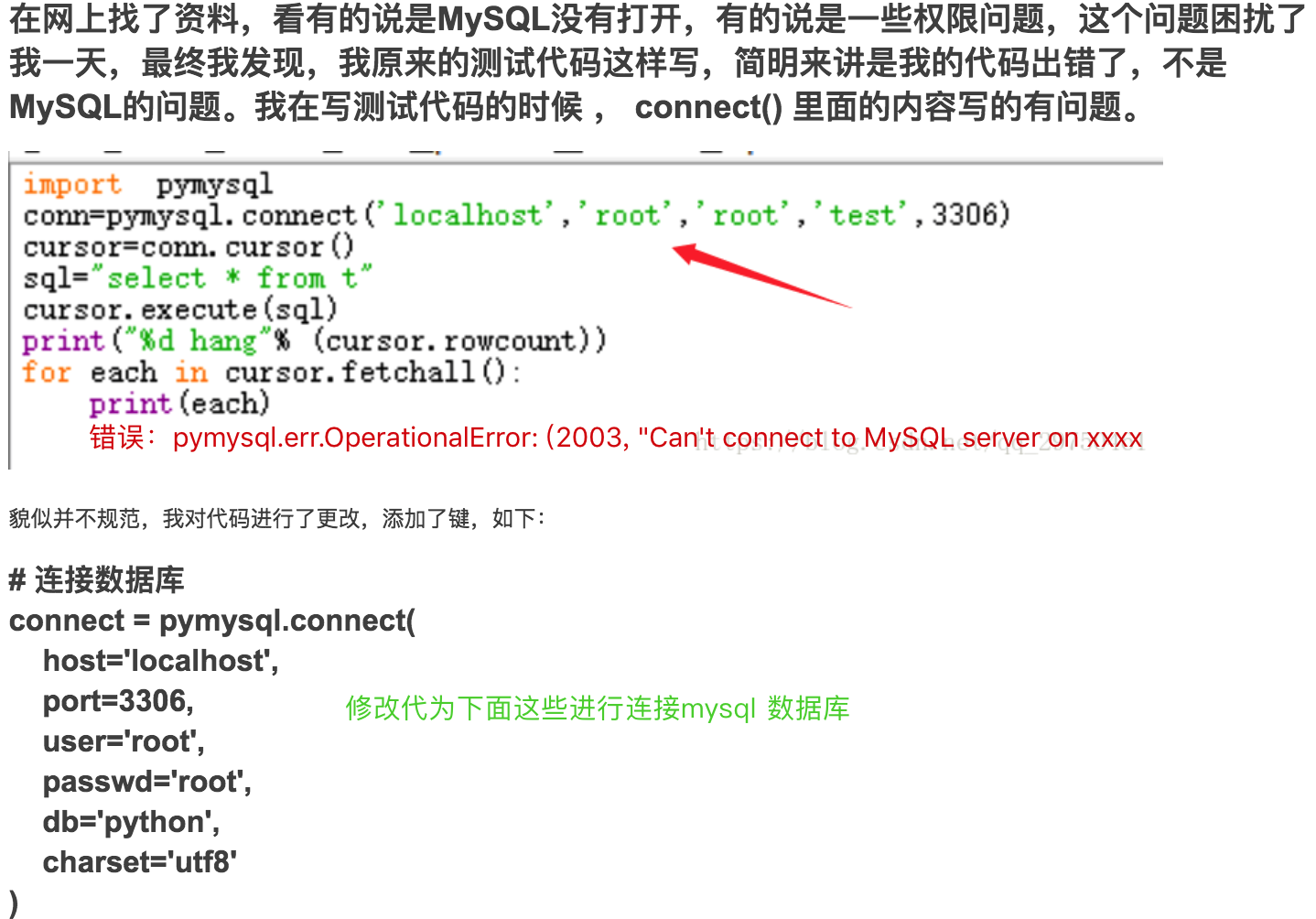
第三个错误
附上源码:

1 import time 2 import pymysql 3 from lxml import etree 4 from selenium import webdriver 5 6 # 浏览器操作对象 7 driver = webdriver.Chrome() 8 # 爬取的url 9 driver.get('https://www.jianshu.com/') 10 11 12 # 加载更多 13 def load_mord(num): 14 # 通过观察发现, 打开页面需要鼠标滑动5次才会出现【阅读更多】按钮 15 for i in range(5): 16 js = "var q = document.documentElement.scrollTop = 1000000" 17 driver.execute_script(js) 18 # 休眠 2 秒 19 time.sleep(2) 20 if num == 0: 21 # 休眠 2 秒 22 time.sleep(2) 23 # 定位并单击【阅读更多】按钮加载更多 24 load_more = driver.find_element_by_class_name('load-more') 25 # 点击 26 load_more.click() 27 28 29 def get_html(): 30 """获取内容源码""" 31 note_list = driver.find_element_by_class_name('note-list') 32 html = note_list.get_attribute('innerHTML') 33 return html 34 35 36 def extract_data(content_html): 37 """传入内容网页源码,使用Xpath提取信息标题,简介,发布昵称""" 38 html = etree.HTML(content_html) 39 # 标题 40 title_list = html.xpath('//li//a[@class="title"]/text()') 41 # 简介 42 abstract_list = html.xpath('//li//p[@class="abstract"]/text()') 43 # 昵称 44 nickname_list = html.xpath('//li//a[@class="nickname"]/text()') 45 46 data_list = [] 47 48 for index, x in enumerate(title_list): 49 item = {} 50 51 item['title'] = title_list[index] 52 item['abstract'] = abstract_list[index] 53 item['nickname'] = nickname_list[index] 54 data_list.append(item) 55 return data_list 56 57 58 def insert_data(sql): 59 # db = pymysql.connect("127.0.0.1", 3306, "root", "python", "xs_db", charset="utf8") 60 # 链接mysql 61 db = pymysql.connect( 62 host='localhost', 63 port=3306, 64 user='root', 65 passwd='python', 66 db='xs_db', 67 charset='utf8' 68 ) 69 try: 70 cursor = db.cursor() 71 return cursor.execute(sql) 72 except Exception as ex: 73 print(ex) 74 finally: 75 # 数据库提交 76 db.commit() 77 # 关闭数据库 78 db.close() 79 80 81 # 模拟点击2次 82 for x in range(2): 83 print('模拟点击加载更多第{}次'.format(str(x))) 84 load_mord(x) 85 time.sleep(1) 86 87 resuts = extract_data(get_html()) 88 for item in resuts: 89 # 插入数据 90 sql = "insert into tb_test(title,abstract,nickname) values ('%s','%s','%s')" % ( 91 item["title"], item["abstract"], item["nickname"]) 92 insert_data(sql)
总结:多交流,多操作,多爬取,多思考。
