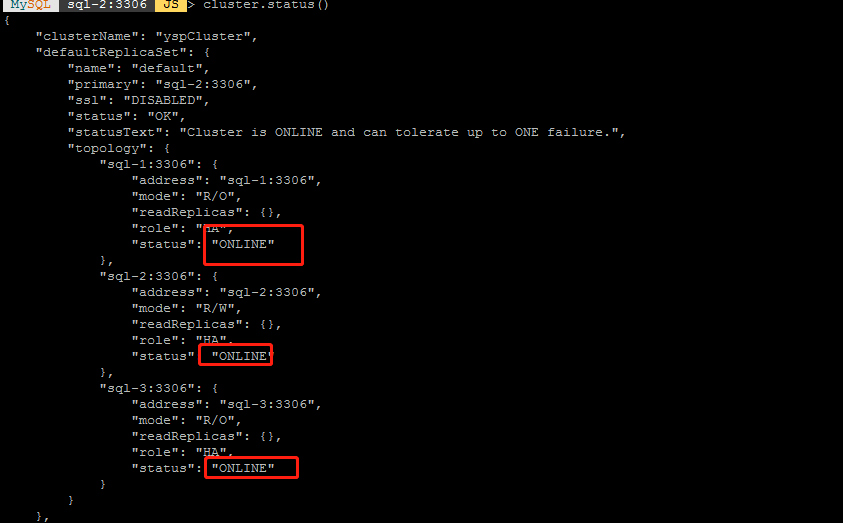
MySQL InnoDB Cluster 恢复故障成员(数据库为5.7版本)
问题:InnoDB Cluster 3个节点中,1个节点丢失,状态为:MISSING

问题分析:因为发现问题比较晚。数据库配置的日志是7天循环删除的。也就是说当MISSING时间大于7天的时候,就不能直接在mysqlsh中使用:cluster.rejoinInstance("root@hostname:3306")重新加入节点的方式恢复,因为主库的日志七天前的日志被清除了,所以无法直接恢复。
解决步骤:
1.导出正常节点的数据库,并传到故障节点
mysqldump -uroot -p --all-databases --triggers --routines --events --quick --single-transaction --flush-logs --master-data=2 > dbs.dump
scp dbs.dump sql-1:~/
2.在集群中删除故障节点:
执行:mysqlsh
MySQL sql-2:3306 JS > var cluster=dba.getCluster(‘yspCluster‘)
MySQL sql-2:3306 JS > cluster.removeInstance('root@sql-1:3306')
3.删除故障节点的data目录,重新初始化数据库。创建用户(这一步其实就是重新初始化sql-1节点)
(1)先备份/etc/my.cnf,然后编辑配置文件
vim /etc/my.cnf
[mysqld]
basedir=/data/mysql
datadir=/data/mysql/data
创建数据库目录
mkdir -pv /data/mysql/data/
chown -R mysql:mysql /data/mysql/data/
(2) 初始化数据库
mysqld --initialize --user=mysql --basedir=/data/mysql/ --datadir=/data/mysql/data (注意:此处会初始化出mysql的初始密码!!!)
(3)初始化mysql密码
mysqladmin -uroot -p'随机生成的密码' password '要设置的密码'
4.在sql-1节点上配置集群实例
dba.configureLocalInstance('root@localhost:3306');

重启数据库后再执行下面的语句,不然状态不会改变为Ok。
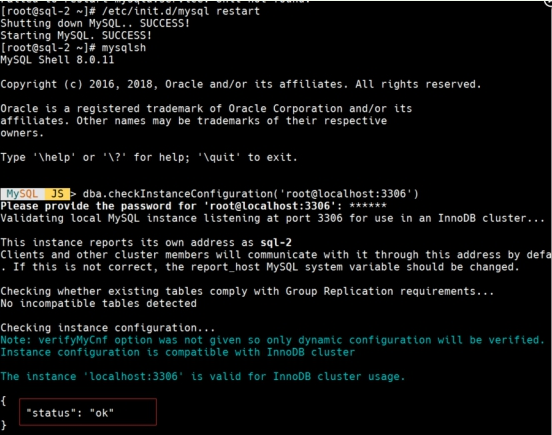
dba.checkInstanceConfiguration('root@localhost:3306') 检查集群实例的状态是否为:OK
5.故障节点导入数据库
登录到故障节点的数据库,执行下面的恢复命令:
mysql> set sql_log_bin=0;
mysql> source dbs.dump
mysql> set sql_log_bin=1;
重启故障节点 MySQL
6.集群中,将故障节点重新加入集群(在正常节点上)
mysqlsh
MySQLsql-2:3306 JS > var cluster=dba.getCluster()
MySQL sql-2:3306 JS > cluster.addInstance('root@sql-1:3306')
7.然后在之前的故障节点使用mysqlsh执行:
dba.configureLocalInstance('root@localhost:3306'); // 保存配置信息到文件,不然读节点重启后无法自动加入到集群中会一直MISSING。