
GlusterFS分布式存储基础梳理以及优缺点
有NFS文件系统,为什么还要使用GlusterFS分布式系统:
NFS面临的问题
1)存储空间不足,需要更大容量的存储,一个存储只能通过增加硬盘来增加存储容量,不适用于大数据存储。
2)直接用NFS挂载存储,有一定风险,存在单点故障,因为数据存储了一份,一旦存储服务器坏了,数据就丢失了。
3)单设备存储,虽然可以通过增加硬盘来增加存储空间,但是当有大量的访问时,存储的磁盘IO会成为性能的瓶颈。
GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,就是把多台存储服务器的存储空间整合起来给用户提供统一的命名空间,有多种分布式存储模式。包括分布式存储,复制卷存储等,可以理解为raid的raid0、raid1、raid10这种模式。
1.GlusterFS存储几个常用的几个术语
Brick:GlusterFS中的存储单元,可以是一个分区目录,也可以是一个文件系统,一般为/dev/db1、/dev/sdc1等,一个服务器节点可以有多个Brick。可以通过主机名和目录名来标识,如'SERVER:EXPORT'。
Client:挂载了GlusterFS卷的设备。
Volfile:Glusterfs进程的配置文件,通常位于/var/lib/glusterd/vols/volname
Volume:一组bricks的逻辑集合
Node:一个拥有若干brick的设备,通俗就是一个服务器节点。
GFID:GlusterFS卷中的每个文件或目录都有一个唯一的128位的数据相关联,其用于模拟inode。
Namespace:每个Gluster卷都导出单个ns作为POSIX的挂载点。
RDMA:远程直接内存访问,支持不通过双方的OS进行直接内存访问。
RRDNS:round robin DNS是一种通过DNS轮转返回不同的设备以进行负载均衡的方法
Self-heal:用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。
Split-brain:脑裂
2.Bricks
• Brick是一个节点和一个文件系统(也可以是一个目录)的组合,例如:node1这一个服务器上有一个/dev/sdb1文件系统,可以表示为 node1/dev/sdb1,
• 每个节点上的brick数是不限的,例如:node1服务器上有多个目录,/dev/sdc1、/dev/sdd1、/mnt/data1等都可以是brick。
• 建议一个集群的所有节点的所有Brick大小都一样。因为如果一个复制卷有两个,一个是100GB,一个是150GB,那么这个复制卷的有效空间只有100GB。
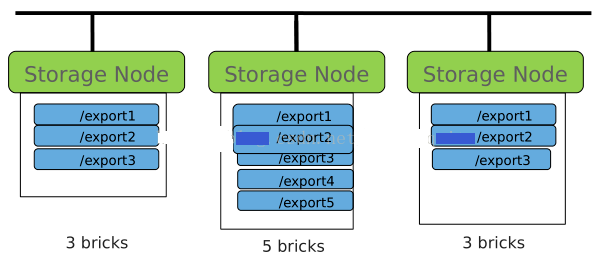
如下图:三个存储节点分别有3个brick、5个brick、3个brick
3.Volumes
• Volume是brick的逻辑组合,根据需求Volume可以由任意个brick创建生成。
• 创建时命名来识别
• Volume是一个可挂载的逻辑目录,由多个brick组成。例如:gluster volume create vol1 node1:/storage1/rep_vol1 node2:/storage1/rep_vol1,创建一个Volume名称为vol1的分布式逻辑卷(类似于raid0,卷的总容量为两个brick之和),并且 由node1的/storage1/rep_vol1 node2和/storage1/rep_vol1
• 一个节点上的不同brick可以属于不同的卷
• 支持如下种类:
a) 分布式卷
b) 条带卷
c) 复制卷
d) 分布式复制卷
e) 条带复制卷
f) 分布式条带复制卷
3.1)分布式卷
• 文件分布存在不同的brick里
• 目录在每个brick里都可见
• 单个brick失效会带来数据丢失
• 无需额外元数据服务器
3.2)复制卷
• 同步复制所有的目录和文件
• 节点故障时保持数据高可用
• 事务性操作,保持一致性
• 有changelog
• 副本数任意定
3.3)分布式复制卷
• 最常见的一种模式
• 读操作可以做到负载均衡
3.4)条带卷
• 文件切分成一个个的chunk,存放于不同的brick上
• 只建议在非常大的文件时使用(比硬盘大小还大)
• Brick故障会导致数据丢失,建议和复制卷同时使用
• Chunks are files with holes – this helps in maintaining offset consistency.
常用操作:
1.节点管理

# gluster peer command
1)节点状态
[root@localhost ~]# gluster peer status //例如:这是在serser0节点上查看的节点状态,只能看到其他Hostname节点与 server0 的连接状态,看不到server0自己的状态
Number of Peers: 2
Hostname: server1
Uuid: 5e987bda-16dd-43c2-835b-08b7d55e94e5
State: Peer in Cluster (Connected)
Hostname: server2
Uuid: 1e0ca3aa-9ef7-4f66-8f15-cbc348f29ff7
State: Peer in Cluster (Connected)
2)添加节点
[root@localhost ~]# gluster peer probe server3 //将server3添加到存储池中
3)删除节点
[root@localhost ~]# gluster peer detach HOSTNAME
[root@localhost ~]# gluster peer detach server3 //将server3从存储池中移除
//移除节点时,需要确保该节点上没有 brick ,需要提前将 brick 移除
2.卷管理
-------------创建分布式卷(DHT)------------- [root@localhost ~]# gluster volume create dht_vol 192.168.2.{100,101,102}:/sdb1 //DHT 卷将数据以哈希计算方式分布到各个 brick 上,数据是以文件为单位存取,基本达到分布均衡,提供的容量和为各个 brick 的总和。 -------------创建副本卷(AFR)------------- [root@localhost ~]# gluster volume create afr_vol replica 3 192.168.2.{100,101,102}:/sdb1 //AFR卷提供数据副本,副本数为 replica,即每个文件存储 replica 份数,文件不分割,以文件为单位存储;副本数需要等于brick数;当brick数是副本的倍数时,则自动变化为 Replicated-Distributed卷。 [root@localhost ~]# gluster volume create afr_vol replica 2 192.168.2.{100,101,102}:/mnt/sdb1 192.168.2.{100,101,102}:/mnt/sdc1 //每两个 brick 组成一组,每组两个副本,文件又以 DHT 分布在三个组上,是副本卷与分布式卷的组合。 -------------创建条带化卷(Stripe)------------- [root@localhost ~]# gluster volume create str_vol stripe 3 192.168.2.{100,101,102}:/mnt/sdb1 //Stripe 卷类似 RAID0,将数据条带化,分布在不同的 brick,该方式将文件分块,将文件分成stripe块,分别进行存储,在大文件读取时有优势;stripe 需要等于 brick 数;当 brick 数等于 stripe 数的倍数时,则自动变化为 Stripe-Distributed 卷。 [root@localhost ~]# gluster volume create str_vol stripe 3 192.168.2.{100,101,102}:/mnt/sdb1 192.168.2.{100,101,102}:/mnt/sdc1 //没三个 brick 组成一个组,每组三个 brick,文件以 DHT 分布在两个组中,每个组中将文件条带化成 3 块。 -------------创建Replicated-Stripe-Distributed卷------------- [root@localhost ~]# gluster volume create str_afr_dht_vol stripe 2 replica 2 192.168.2.{100,101,102}:/mnt/sdb1 192.168.2.{100,101,102}:/mnt/sdc1 192.168.2.{100,101}:/mnt/sdd1 //使用8个 brick 创建一个组合卷,即 brick 数是 stripe*replica 的倍数,则创建三种基本卷的组合卷,若刚好等于 stripe*replica 则为 stripe-Distrbuted 卷。 [root@localhost ~]# gluster volume info //该命令能够查看存储池中的当前卷的信息,包括卷方式、包涵的 brick、卷的当前状态、卷名及 UUID 等。 卷状态 [root@localhost ~]# gluster volume status //该命令能够查看当前卷的状态,包括其中各个 brick 的状态,NFS 的服务状态及当前 task执行情况,和一些系统设置状态等。 启动/ 停止 卷 [root@localhost ~]# gluster volume start/stop VOLNAME //将创建的卷启动,才能进行客户端挂载;stop 能够将系统卷停止,无法使用;此外 gluster未提供 restart 的重启命令 删除卷 [root@localhost ~]# gluster volume delete VOLNAME //删除卷操作能够将整个卷删除,操作前提是需要将卷先停止
3.Brick 管理
1)给现有的Volume添加 Brick 若是分布式卷,直接给现有的卷添加brick,如下: # gluster volume add-brick VOLNAME NEW-BRICK # gluster volume add-brick dht_vol server3:/mnt/sdc1 //添加 server3 上的/mnt/sdc1 到卷 dht_vol 上。此例中dht_vol为分布式卷,类似于raid0。
若是副本卷(复制卷),则一次添加的 Bricks 数是 replica 的整数倍;stripe 具有同样的要求。
# gluster volume add-brick VOLNAME NEW-BRICK
# gluster volume add-brick dht_vol server3:/mnt/sdc1 server3:/mnt/sdd1 //此例中dht_vol为已经创建的有两个副本复制卷,那么给卷中增加brick必须是2的倍数
2)移除 Brick 若是副本卷,则移除的 Bricks 数是 replica 的整数倍;stripe 具有同样的要求。 [root@localhost ~]# gluster volume remove-brick VOLNAME BRICK start/status/commit [root@localhost ~]# gluster volume remove-brick dht_vol server3:/mnt/sdc1 start //GlusterFS_3.4.1 版本在执行移除 Brick 的时候会将数据迁移到其他可用的 Brick 上,当数据迁移结束之后才将 Brick 移除。执行 start 命令,开始迁移数据,正常移除 Brick。 [root@localhost ~]# gluster volume remove-brick dht_vol server3:/mnt/sdc1 status //在执行开始移除 task 之后,可以使用 status 命令进行 task 状态查看。 [root@localhost ~]# gluster volume remove-brick dht_vol server3:/mnt/sdc1 commit //使用 commit 命令执行 Brick 移除,则不会进行数据迁移而直接删除 Brick,符合不需要数据迁移的用户需求。 PS :系统的扩容及缩容可以通过如上节点管理、Brick 管理组合达到目的。 (1) 扩容时,可以先增加系统节点,然后 添加新增节点上的 Brick 即可。 (2) 缩容时,先移除 Brick ,然后再。 进行节点删除则达到缩容的目的,且可以保证数据不丢失。 3)替换 Brick [root@localhost ~]# gluster volume replace-brick VOLNAME BRICKNEW-BRICK start/pause/abort/status/commit [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 start //如上,执行 replcace-brick 卷替换启动命令,使用 start 启动命令后,开始将原始 Brick 的数据迁移到即将需要替换的 Brick 上。 [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 status //在数据迁移的过程中,可以查看替换任务是否完成。 [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 abort //在数据迁移的过程中,可以执行 abort 命令终止 Brick 替换。 [root@localhost ~]# gluster volume replace-brick dht_vol server0:/mnt/sdb1 server0:/mnt/sdc1 commit //在数据迁移结束之后,执行 commit 命令结束任务,则进行Brick替换。使用volume info命令可以查看到 Brick 已经被替换。
4.GlusterFS系统扩展维护
4.1)系统配额
1)开启/关闭系统配额 [root@localhost ~]# gluster volume quota VOLNAME enable/disable //在使用系统配额功能时,需要使用 enable 将其开启;disable 为关闭配额功能命令。 2)设置( 重置) 目录配额 [root@localhost ~]# gluster volume quota VOLNAME limit-usage /directory limit-value [root@localhost ~]# gluster volume quota dht_vol limit-usage /quota 10GB //如上,设置 dht_vol 卷下的 quota 子目录的限额为 10GB。 PS:这个目录是以系统挂载目录为根目录”/”,所以/quota 即客户端挂载目录下的子目录 quota 3)配额查看 [root@localhost ~]# gluster volume quota VOLNAME list [root@localhost ~]# gluster volume quota VOLNAME list /directory name //可以使用如上两个命令进行系统卷的配额查看,第一个命令查看目的卷的所有配额设置,第二个命令则是执行目录进行查看。 //可以显示配额大小及当前使用容量,若无使用容量(最小 0KB)则说明设置的目录可能是错误的(不存在)。
例:
[root@data-node-01 data2]# gluster volume create vol5 data-node-01:/glusterfs/storage1/rep_vol5 data-node-02:/glusterfs/storage1/rep_vol5 force //创建分布式卷vol5
volume create: vol5: success: please start the volume to access data
[root@data-node-01 data2]# gluster volume start vol5 //start分布式卷
volume start: vol5: success
[root@data-node-01 data2]# mount -t glusterfs 192.168.0.95:vol5 /data5/ //将vol卷挂载到本地的/data5/目录下
[root@data-node-01 data2]# mkdir /data5/d1 //分别创建/data5/d1目录
[root@data-node-01 data2]# mkdir /data5/d2 //创建/data5/d2
[root@data-node-01 data2]# gluster volume quota vol5 enable //开启vol5这个卷的配额
[root@data-node-02 ~]# gluster volume quota vol5 limit-usage /d1 10GB //设置vol5下的 d1目录的容量为10GB
volume quota : success
[root@data-node-02 ~]# gluster volume quota vol5 limit-usage /d2 20GB //同上
volume quota : success
[root@data-node-01 data6]# mount -t glusterfs 192.168.0.95:vol5/d1 /data5/d1 //挂载
[root@data-node-01 data6]# mount -t glusterfs 192.168.0.95:vol5/d2 /data5/d2
[root@data-node-01 data6]# df -h
192.168.0.95:vol5 91G 34G 57G 38% /data5
192.168.0.95:vol5/d1 10G 0 10G 0% /data5/d1 //d1目录最大为10GB
192.168.0.95:vol5/d2 20G 0 20G 0% /data5/d2 //同上


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?