
MySQL+MGR单主模式集群环境部署
MySQL Group Replication(简称MGR)是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决方案。MGR是MySQL官方在5.7.17版本引进的一个数据库高可用与高扩展的解决方案,以插件形式提供,实现了分布式下数据的最终一致性, 它提供了高可用、高扩展、高可靠的MySQL集群服务。
MySQL组复制分单主模式和多主模式。如果仅使用mysql主从模式,mysql主从模式的复制技术仅解决了数据同步的问题,如果 master 宕机,意味着数据库管理员需要介入,应用系统可能需要修改数据库连接地址或者重启才能实现。组复制在数据库层面上做到了,只要集群中大多数主机可用,则服务可用,也就是说如果有一个3台服务器的集群,则允许其中1台宕机。
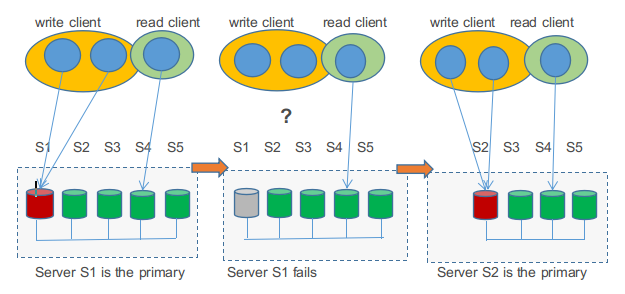
如上图:S1-S5分别为数据库服务器,5台数据库为一个集群,S1为master主节点,是读写节点,其他4个数据库服务为备节点,是只读节点,当S1这个master节点挂掉后,四个备节点中会有一个节点被选为master节点(可能是S2节点),然后S2成为master主节点,是读写节点,S3-S5为备节点,是只读节点。
1. MGR组复制的特点
- 高一致性:基于分布式paxos协议实现组复制,保证数据一致性;
- 高容错性:自动检测机制,只要不是大多数节点都宕机就可以继续工作,内置防脑裂保护机制;
- 高扩展性:节点的增加与移除会自动更新组成员信息,新节点加入后,自动从其他节点同步增量数据,直到与其他节点数据一致;
- 高灵活性:提供单主模式和多主模式,单主模式在主库宕机后能够自动选主,所有写入都在主节点进行,多主模式支持多节点写入。
2.MGR组复制原理
组复制是一种可用于实现容错系统的技术。 复制组是一个通过消息传递相互交互的 server 集群。通信层提供了原子消息(atomic message)和完全有序信息交互等保障机制实现了基于复制协议的多主更新 复制组由多个 server成员构成,并且组中的每个 server 成员可以独立地执行事务。但所有读写(RW)事务只有在冲突检测成功后才会提交。只读(RO)事务不需要在冲突检测,可以立即提交。换句话说,对于任何 RW 事务,提交操作并不是由主节点 server 决定的,而是由组来决定是否提交。准确地说,在主节点 server 上,当事务准备好提交时,该 server 会广播写入值(已改变的行)和对应的写入集(已更新的行的唯一标识符)。然后会为该事务建立一个全局的顺序。最终,这意味着所有 server 成员以相同的顺序接收同一组事务。因此,所有 server 成员以相同的顺序应用相同的更改,以确保组内一致。
MySQL组复制协议工作流程:
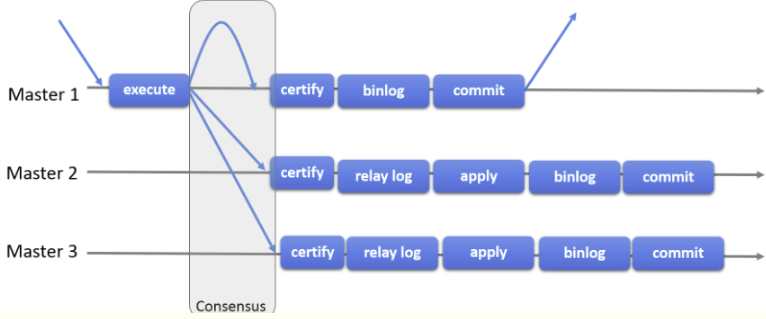
需要注意:MGR组复制是一种 share-nothing 复制方案,其中每个 server 成员都有自己的完整数据副本。
MGR的限制
- 存储引擎必须为Innodb,即仅支持InnoDB表,并且每张表一定要有一个主键,用于做write set的冲突检测;
- 每个表必须提供主键;
- 只支持ipv4,网络需求较高;
- 必须打开GTID特性,二进制日志格式必须设置为ROW,用于选主与write set;
- COMMIT可能会导致失败,类似于快照事务隔离级别的失败场景;
- 目前一个MGR集群组最多支持9个节点;
- 不支持外键于save point特性,无法做全局间的约束检测与部分部分回滚;
- 二进制日志binlog不支持Replication event checksums;
- 多主模式(也就是多写模式) 不支持SERIALIZABLE事务隔离级别;
- 多主模式不能完全支持级联外键约束;
- 多主模式不支持在不同节点上对同一个数据库对象并发执行DDL(在不同节点上对同一行并发进行RW事务,后发起的事务会失败);
3. 组复制两种运行模式
-> 在单主模式下, 组复制具有自动选主功能,每次只有一个 server成员接受数据更新。单写模式group内只有一台节点可写可读,其他节点只可以读。对于group的部署,需要先跑起primary节点(即那个可写可读的节点,read_only = 0表示此节点可读写)然后再跑起其他的节点,并把这些节点依次加进group。其他的节点就会自动同步primary节点上面的变化,然后将自己设置为只读模式(read_only = 1表示只读节点)。当primary节点意外宕机或者下线,在满足大多数节点存活的情况下,group内部发起选举,选出下一个可用的读节点,提升为primary节点。primary选举根据group内剩下存活节点的UUID按字典序升序来选择,即剩余存活的节点按UUID字典序排列,然后选择排在最前的节点作为新的primary节点。
-> 在多主模式下, 所有的 server 成员都可以同时接受更新。group内的所有机器都是primary节点,同时可以进行读写操作,并且数据是最终一致的。
按照我的理解来说:
单主模式:比多主模式多一个选举程序,第一次引导开启集群的为主,后加入的为追随者(也可以叫从机Slave),只有住的有读写权限,别的追随者在加入组的时候自动把权限禁了。如果主的挂了,其他服务器会根据UUID和一个值(类似权重)进行重新选主。每次选主都会重新把权限禁一遍。
多主模式:所有服务器加入组时,读写权限全部放开,大家都可以读写,但是只能更改不同行的数据,如果后加入集群的服务器改了一行数据,那前面的服务器就不能再对这行数据进行改动了,如果改动则报事务回滚取消改动,而后加入的可以改前面加入集群改过的数据。
4. 下面记录下 MGR 基于单主模式的集群环境部署过程(多主模式的略,后面在更新...)
4.1 准备环境
三台服务器 172.16.60.211 MGR-node1 server_id=1 172.16.60.212 MGR-node2 server_id=2 172.16.60.213 MGR-node3 server_id=3 [root@MGR-node1 ~]# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core) 为了方便实验,关闭所有节点的防火墙 [root@MGR-node1 ~]# systemctl stop firewalld [root@MGR-node1 ~]# firewall-cmd --state not running [root@MGR-node1 ~]# cat /etc/sysconfig/selinux |grep "SELINUX=disabled" SELINUX=disabled [root@MGR-node1 ~]# setenforce 0 setenforce: SELinux is disabled [root@MGR-node1 ~]# getenforce Disabled 特别要注意一个关键点: 必须保证各个mysql节点的主机名不一致,并且能通过主机名找到各成员! 则必须要在每个节点的/etc/hosts里面做主机名绑定,否则后续将节点加入group组会失败!报错RECOVERING!! [root@MGR-node1 ~]# cat /etc/hosts ........ 172.16.60.211 MGR-node1 172.16.60.212 MGR-node2 172.16.60.213 MGR-node3
4.2 在三个节点上安装Mysql5.7(可以二进制安装,本教程为yum安装)
安装MySQL yum资源库 [root@MGR-node1 ~]# yum localinstall https://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm 安装MySQL 5.7 [root@MGR-node1 ~]# yum install -y mysql-community-server 启动MySQL服务器和MySQL的自动启动 [root@MGR-node1 ~]# systemctl start mysqld.service [root@MGR-node1 ~]# systemctl enable mysqld.service 设置登录密码 由于MySQL从5.7开始不允许首次安装后使用空密码进行登录!为了加强安全性,系统会随机生成一个密码以供管理员首次登录使用, 这个密码记录在/var/log/mysqld.log文件中,使用下面的命令可以查看此密码: [root@MGR-node1 ~]# cat /var/log/mysqld.log|grep 'A temporary password' 2022-11-17T11:21:34.381573Z 1 [Note] A temporary password is generated for root@localhost: TaN.k:*Qw2xs 使用上面查看的密码TaN.k:*Qw2xs 登录mysql,并重置密码为123456 [root@MGR-node1 ~]# mysql -p #输入默认的密码:TaN.k:*Qw2xs ............. mysql> set global validate_password_policy=0; Query OK, 0 rows affected (0.00 sec) mysql> set global validate_password_length=1; Query OK, 0 rows affected (0.00 sec) mysql> set password=password("123456"); Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) 查看mysql版本 [root@MGR-node1 ~]# mysql -p123456 ........ mysql> select version(); +-----------+ | version() | +-----------+ | 5.7.24 | +-----------+ 1 row in set (0.00 sec) ===================================================================== 温馨提示 mysql5.7通过上面默认安装后,执行语句可能会报错: ERROR 1819 (HY000): Your password does not satisfy the current policy requirements 这个报错与Mysql 密码安全策略validate_password_policy的值有关,validate_password_policy可以取0、1、2三个值: 解决办法: set global validate_password_policy=0; //密码复杂度为最低 set global validate_password_length=1; //设置密码最小长度
4.3 安装和配置MGR信息(每个节点都要配置)
1) 配置所有节点的组复制信息 MGR-node01节点 [root@MGR-node1 ~]# cp /etc/my.cnf /etc/my.cnf.bak [root@MGR-node1 ~]# >/etc/my.cnf [root@MGR-node1 ~]# vim /etc/my.cnf [mysqld] datadir = /var/lib/mysql socket = /var/lib/mysql/mysql.sock symbolic-links = 0 log-error = /var/log/mysqld.log pid-file = /var/run/mysqld/mysqld.pid #复制框架 server_id=1 gtid_mode=ON enforce_gtid_consistency=ON binlog_checksum=NONE log_bin=binlog log_slave_updates=ON binlog_format=ROW master_info_repository=TABLE relay_log_info_repository=TABLE #组复制设置 #server必须为每个事务收集写集合,并使用XXHASH64哈希算法将其编码为散列 transaction_write_set_extraction=XXHASH64 #告知插件加入或创建组命名,UUID loose-group_replication_group_name="aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa" #server启动时不自启组复制,为了避免每次启动自动引导具有相同名称的第二个组,所以设置为OFF。 loose-group_replication_start_on_boot=off #告诉插件使用IP地址,端口24901用于接收组中其他成员转入连接 loose-group_replication_local_address="172.16.60.211:24901" //这里写自己的IP地址和MGR要是用的端口 #启动组server,种子server,加入组应该连接这些的ip和端口;其他server要加入组得由组成员同意 loose-group_replication_group_seeds="172.16.60.211:24901,172.16.60.212:24901,172.16.60.213:24901" //这里是group中所有成员的ip+端口 loose-group_replication_bootstrap_group=off report_host=172.16.60.211 //自己的IP地址 report_port=3306 //数据库的端口 如上配置完成后, 将MGR-node1节点的/etc/my.cnf文件拷贝到其他两个节点 [root@MGR-node1 ~]# rsync -e "ssh -p22" -avpgolr /etc/my.cnf root@172.16.60.212:/etc/ [root@MGR-node1 ~]# rsync -e "ssh -p22" -avpgolr /etc/my.cnf root@172.16.60.213:/etc/ 3个MGR节点除了server_id、loose-group_replication_local_address、report_host 三个参数不一样外,其他保持一致。 所以待拷贝完成后, 分别修改MGR-node2和MGR-node3节点/etc/my.cnf文件的server_id、loose-group_replication_local_address、report_host 三个参数 2) 配置完成后, 依次启动三台数据库,安装MGR插件,设置复制账号(所有MGR节点都要执行) [root@MGR-node1 ~]# systemctl restart mysqld [root@MGR-node1 ~]# mysql -p123456 ............. mysql> INSTALL PLUGIN group_replication SONAME 'group_replication.so'; Query OK, 0 rows affected (0.13 sec) mysql> SET SQL_LOG_BIN=0; Query OK, 0 rows affected (0.00 sec) mysql> CREATE USER repl@'%' IDENTIFIED BY 'repl'; Query OK, 0 rows affected (0.00 sec) mysql> GRANT REPLICATION SLAVE ON *.* TO repl@'%'; Query OK, 0 rows affected (0.00 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.00 sec) mysql> SET SQL_LOG_BIN=1; Query OK, 0 rows affected (0.00 sec) mysql> CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='repl' FOR CHANNEL 'group_replication_recovery'; Query OK, 0 rows affected, 2 warnings (0.21 sec)
4.4 启动MGR单主模式
1) 启动MGR,在主库(172.16.60.11)节点上上执行 [root@MGR-node1 ~]# mysql -p123456 ............... mysql> SET GLOBAL group_replication_bootstrap_group=ON; Query OK, 0 rows affected (0.00 sec) mysql> START GROUP_REPLICATION; Query OK, 0 rows affected (2.31 sec) mysql> SET GLOBAL group_replication_bootstrap_group=OFF; Query OK, 0 rows affected (0.00 sec) 查看MGR组信息 mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+---------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ | group_replication_applier | 8769f936-3e51-11e9-acaa-005056ac6820 | 172.16.60.211 | 3306 | ONLINE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ 1 row in set (0.01 sec) 2) 在其他节点加入MGR集群,在从库(172.16.60.212,172.16.60.213)上执行 [root@MGR-node2 ~]# mysql -p123456 ................ mysql> START GROUP_REPLICATION; ERROR 3092 (HY000): The server is not configured properly to be an active member of the group. Please see more details on error log. 查看日志: [root@MGR-node2 ~]# tail -2000 /var/log/mysqld.log ..................... ..................... 2019-03-04T09:11:30.683714Z 0 [ERROR] Plugin group_replication reported: 'This member has more executed transactions than those present in the group. Local transactions: 87135ebb-3e51-11e9-8931-005056880888:1-2 > Group transactions: 851d03bb-3e51-11e9-8f8d-00505688047c:1-2, 8769f936-3e51-11e9-acaa-005056ac6820:1-2, aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1-4' 2019-03-04T09:11:30.683817Z 0 [Warning] Plugin group_replication reported: 'The member contains transactions not present in the group. It is only allowed to join due to group_replication_allow_local_disjoint_gtids_join option' 解决办法: mysql> set global group_replication_allow_local_disjoint_gtids_join=ON; Query OK, 0 rows affected, 1 warning (0.00 sec) 然后再接着加入MGR集群 mysql> START GROUP_REPLICATION; Query OK, 0 rows affected, 1 warning (5.14 sec) 3) 再次查看MGR组信息 (在三个MGR节点上都可以查看) mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+---------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ | group_replication_applier | 851d03bb-3e51-11e9-8f8d-00505688047c | 172.16.60.212 | 3306 | RECOVERING | | group_replication_applier | 87135ebb-3e51-11e9-8931-005056880888 | 172.16.60.213 | 3306 | RECOVERING | | group_replication_applier | 8769f936-3e51-11e9-acaa-005056ac6820 | 172.16.60.211 | 3306 | ONLINE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ 3 rows in set (0.00 sec) 发现新加入的MGR-node2 , MGR-node3两个节点在集群里的状态是RECOVERING!!! 查看日志 [root@MGR-node3 ~]# tail -2000 /var/log/mysqld.log ..................... ..................... 2019-03-04T09:15:35.146740Z 734 [ERROR] Slave I/O for channel 'group_replication_recovery': Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.', Error_code: 1236 解决办法: 登录主库172.16.60.211, 查看被purge的GTID: [root@MGR-node1 ~]# mysql -p123456 .................... mysql> show global variables like 'gtid_purged'; +---------------+------------------------------------------+ | Variable_name | Value | +---------------+------------------------------------------+ | gtid_purged | 8769f936-3e51-11e9-acaa-005056ac6820:1-2 | +---------------+------------------------------------------+ 1 row in set (0.00 sec) 接着在两个从库172.16.60.212, 172.16.60.213的数据库上执行下面命令,即跳过这个GTID: mysql> STOP GROUP_REPLICATION; Query OK, 0 rows affected (10.14 sec) mysql> reset master; Query OK, 0 rows affected (0.06 sec) mysql> set global gtid_purged = '8769f936-3e51-11e9-acaa-005056ac6820:1-2'; Query OK, 0 rows affected (0.24 sec) mysql> START GROUP_REPLICATION; Query OK, 0 rows affected, 1 warning (3.49 sec) 再次查看查看MGR组信息 (在三个MGR节点上都可以查看), mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+---------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ | group_replication_applier | 851d03bb-3e51-11e9-8f8d-00505688047c | 172.16.60.212 | 3306 | ONLINE | | group_replication_applier | 87135ebb-3e51-11e9-8931-005056880888 | 172.16.60.213 | 3306 | ONLINE | | group_replication_applier | 8769f936-3e51-11e9-acaa-005056ac6820 | 172.16.60.211 | 3306 | ONLINE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ 3 rows in set (0.00 sec) 通过上面可以看出: 三个MGR节点状态为online,并且主节点为172.16.60.211,只有主节点可以写入,其他两个MGR节点只读,MGR单主模式搭建成功。 ============================================================================== 验证下MGR单主模式下节点数据的同步以及读写操作: 先在主库节点172.16.60.211上创建测试数据库 [root@MGR-node1 ~]# mysql -p123456 .............. mysql> CREATE DATABASE kevin CHARACTER SET utf8 COLLATE utf8_general_ci; Query OK, 1 row affected (0.06 sec) mysql> use kevin; Database changed mysql> create table if not exists haha (id int(10) PRIMARY KEY AUTO_INCREMENT,name varchar(50) NOT NULL); Query OK, 0 rows affected (0.24 sec) mysql> insert into kevin.haha values(1,"wangshibo"),(2,"guohuihui"),(3,"yangyang"),(4,"shikui"); Query OK, 4 rows affected (0.13 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql> select * from kevin.haha; +----+-----------+ | id | name | +----+-----------+ | 1 | wangshibo | | 2 | guohuihui | | 3 | yangyang | | 4 | shikui | +----+-----------+ 4 rows in set (0.00 sec) 接着在其他的两个从节点172.16.60.212和172.16.60.213上查看数据, 发现主库数据已经同步到两个从库上了 [root@MGR-node2 ~]# mysql -p123456 .................. mysql> select * from kevin.haha; +----+-----------+ | id | name | +----+-----------+ | 1 | wangshibo | | 2 | guohuihui | | 3 | yangyang | | 4 | shikui | +----+-----------+ 4 rows in set (0.00 sec) 然后尝试在两个从库上更新数据, 发现更新失败! 因为这是MGR单主模式, 从库只能进行读操作, 不能进行写操作! [root@MGR-node3 ~]# mysql -p123456 ................. mysql> select * from kevin.haha; +----+-----------+ | id | name | +----+-----------+ | 1 | wangshibo | | 2 | guohuihui | | 3 | yangyang | | 4 | shikui | +----+-----------+ 4 rows in set (0.00 sec) mysql> delete from kevin.haha where id>3; ERROR 1290 (HY000): The MySQL server is running with the --super-read-only option so it cannot execute this statement mysql> insert into kevin.haha values(11,"beijing"),(12,"shanghai"),(13,"anhui"); ERROR 1290 (HY000): The MySQL server is running with the --super-read-only option so it cannot execute this statement 只有在主库上才能进行写操作 [root@MGR-node1 ~]# mysql -p123456 .............. mysql> insert into kevin.haha values(11,"beijing"),(12,"shanghai"),(13,"anhui"); Query OK, 3 rows affected (0.15 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from kevin.haha; +----+-----------+ | id | name | +----+-----------+ | 1 | wangshibo | | 2 | guohuihui | | 3 | yangyang | | 4 | shikui | | 11 | beijing | | 12 | shanghai | | 13 | anhui | +----+-----------+ 7 rows in set (0.00 sec)
4.5 故障切换
1) 单主模式 如果主节点挂掉了, 通过选举程序会从从库节点中选择一个作为主库节点. 如下模拟故障: 关闭主库MGR-node1的mysqld服务 [root@MGR-node1 ~]# systemctl stop mysqld 接着在其他节点上查看MGR组信息. 比如在MGR-node2节点查看 [root@MGR-node2 ~]# mysql -p123456 mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+---------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ | group_replication_applier | 851d03bb-3e51-11e9-8f8d-00505688047c | 172.16.60.212 | 3306 | ONLINE | | group_replication_applier | 87135ebb-3e51-11e9-8931-005056880888 | 172.16.60.213 | 3306 | ONLINE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ 2 rows in set (0.00 sec) 尝试在MGR-node2节点更新数据 mysql> select * from kevin.haha; +----+-----------+ | id | name | +----+-----------+ | 1 | wangshibo | | 2 | guohuihui | | 3 | yangyang | | 4 | shikui | | 11 | beijing | | 12 | shanghai | | 13 | anhui | +----+-----------+ 7 rows in set (0.00 sec) mysql> delete from kevin.haha where id>10; Query OK, 3 rows affected (0.06 sec) 如上, 发现在之前的主库MGR-node1节点挂掉后, MGR-node2节点可以进行写操作了, 说明此时已经选举MGR-node2节点为新的主节点了 那么,MGR-node3节点还是从节点, 只能读不能写 [root@MGR-node3 ~]# mysql -p123456 .............. mysql> select * from kevin.haha; +----+-----------+ | id | name | +----+-----------+ | 1 | wangshibo | | 2 | guohuihui | | 3 | yangyang | | 4 | shikui | +----+-----------+ 4 rows in set (0.00 sec) mysql> insert into kevin.haha values(11,"beijing"),(12,"shanghai"),(13,"anhui"); ERROR 1290 (HY000): The MySQL server is running with the --super-read-only option so it cannot execute this statement 然后再恢复MGR-node1节点, 恢复后, 需要手动激活下该节点的组复制功能 [root@MGR-node1 ~]# systemctl start mysqld [root@MGR-node1 ~]# mysql -p123456 ............... mysql> START GROUP_REPLICATION; Query OK, 0 rows affected (3.15 sec) mysql> SELECT * FROM performance_schema.replication_group_members; +---------------------------+--------------------------------------+---------------+-------------+--------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ | group_replication_applier | 851d03bb-3e51-11e9-8f8d-00505688047c | 172.16.60.212 | 3306 | ONLINE | | group_replication_applier | 87135ebb-3e51-11e9-8931-005056880888 | 172.16.60.213 | 3306 | ONLINE | | group_replication_applier | 8769f936-3e51-11e9-acaa-005056ac6820 | 172.16.60.211 | 3306 | ONLINE | +---------------------------+--------------------------------------+---------------+-------------+--------------+ 3 rows in set (0.00 sec) mysql> select * from kevin.haha; +----+-----------+ | id | name | +----+-----------+ | 1 | wangshibo | | 2 | guohuihui | | 3 | yangyang | | 4 | shikui | +----+-----------+ 4 rows in set (0.00 sec) mysql> insert into kevin.haha values(11,"beijing"),(12,"shanghai"),(13,"anhui"); ERROR 1290 (HY000): The MySQL server is running with the --super-read-only option so it cannot execute this statement 发现MGR-node1节点恢复后, 则变为了从库节点, 只能读不能写. 如果从节点挂了, 恢复后, 只需要手动激活下该节点的组复制功能("START GROUP_REPLICATION;"), 即可正常加入到MGR组复制集群内并自动同步其他节点数据.
