Hadoop集群操作
写在前面
前文地址1 前文地址2我们搭建了hadoop集群,接下来学习一下如何对HDFS进行操作(即hadoop的分布式文件系统)。毕竟我们不能白搭建集群嘛。主要可以分为shell操作和API操作。
shell操作
以下操作都在hadoop目录下,如我的就在/opt/module/hadoop-2.7.2
这里有两种方法,**bin/hadoop fs 具体命令 **或者 bin/hdfs dfs 具体命令,二者区别不大,dfs是fs的实现类。这里我配置了环境变量,故可以直接hadoop或者hdfs。
-
启动hadoop集群
sbin/start-dfs.sh sbin/start-yarn.sh -
显示目录信息
hadoop fs -ls / -
在HDFS上创建目录
hadoop fs -mkdir -p /sanguo/shuguo -
从本地剪切粘贴到HDFS
touch kongming.txt hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo -
追加一个文件到已经存在的文件末尾
touch liubei.txt vim liubei.txt 输入 san gu mao lu hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt -
显示文件内容
hadoop fs -cat /sanguo/kongming.txt -
-chgrp、-chmod,-chown,用法与linux系统中一样,修改文件的所属权限
hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt hadoop fs -chown liuge:liuge /sanguo/shuguo/kongming.txt -
把本地系统文件拷贝到HDFS上
hadoop fs -copyFromLocal README.txt / -
从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./ -
从HDFS的一个路径拷贝到另一个路径
hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt -
在HDFS目录中移动文件
hadoop fs -mv /zhuge.txt /sanguo/shuguo -
-get等同于copyToLocal,-put等同于copyFromLocal
-
合并多个下载文件
hadoop fs -getmerge /user/liuge/test/* ./zaiyiqi.txt
-
显示一个文件的末尾
hadoop fs -tail /sanguo/shuguo/kongming.txt -
删除文件或者文件夹
hadoop fs -rm /user/liuge/test/jinlian2.txt -
删除空目录
hadoop fs -mkdir /test hadoop fs -rmdir /test -
统计文件夹的大小信息
hadoop fs -du -s -h /user/liuge/test
总的来说,shell操作可以满足我们大多数的需求了。但有时候还是需要编写JAVA API的。下面来看看使用JAVA API。
API操作
准备工作
首先准备一个已经编译好的与linux上的hadoop一个版本的jar包,解压到一个非中文目录,配置HADOOP_HOME环境变量:
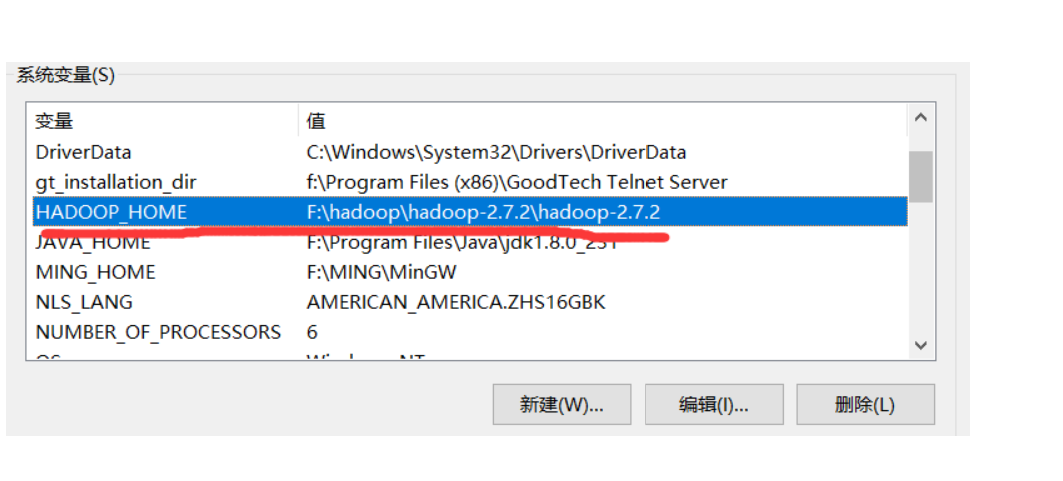
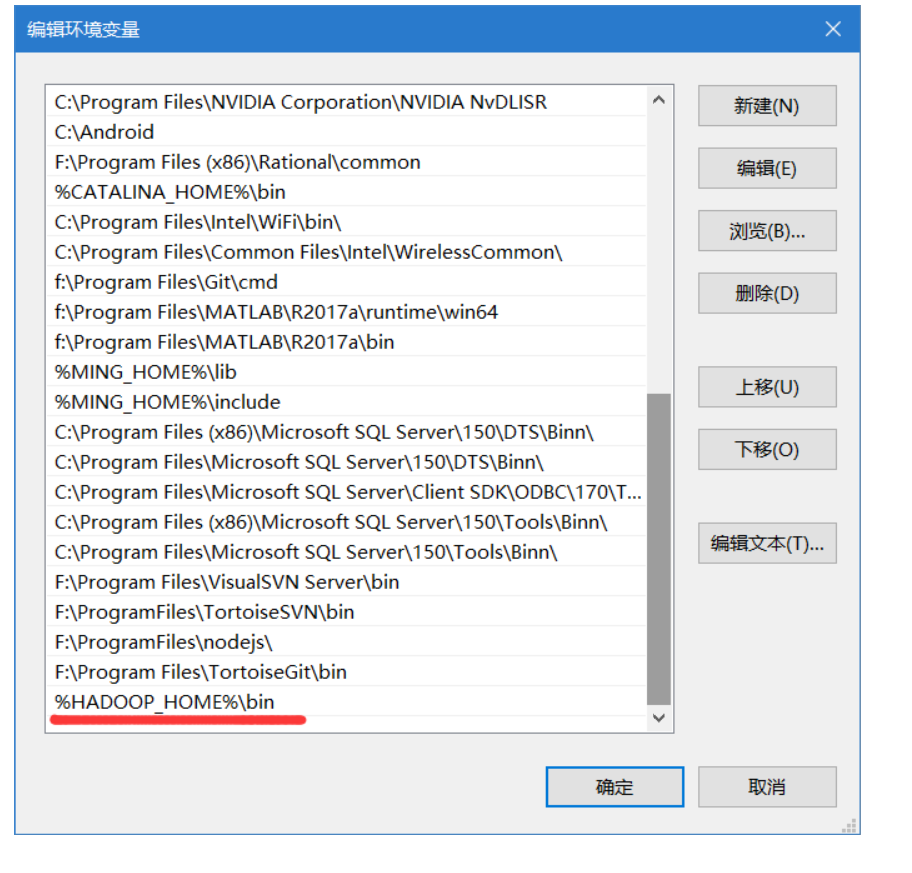
再接着去配置PATH环境变量,添加一条:%HADOOP_HOME%\bin
创建一个maven项目,导入如下的依赖:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
同时在resources目录下新建一个log4j.properties,写入以下内容:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
编写一个HDFSClient类,写入如下代码作为测试:
FileSystem fs = getFileSystem();
// 2.在hdfs上创建路径
fs.mkdirs(new Path("/0529/liuge/banzhang"));
// 3.关闭资源
fs.close();
System.out.println("over");
其中的getFileSystem()方法为:
private static FileSystem getFileSystem() throws Exception {
Configuration conf = new Configuration();
return FileSystem.get(new URI("hdfs://hadoop03:9000"), conf, "liuge");
}
解释一下,在getFileSystem()方法里,要写入你的hadoop集群地址,以及访问的用户,比如我这里是liuge,就写入liuge用户。
之后我们获取到文件系统后,就可以在hdfs上进行操作了。
如果能正确输出over,且在web端上观察到已经创建了文件,则说明能够正确连接到集群。
HDFS文件上传与下载
先直接上代码:
/**
* 1. 文件上传
* 优先级:代码配置>resources配置文件>linux中的配置文件>linux中的默认配置文件
*/
@Test
public void testCopyFromLocalFile() throws Exception {
// 1.获取fs对象
Configuration conf =new Configuration();
conf.set("dfs.replication","2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop03:9000"), conf, "liuge");
// 2.执行上传代码
fs.copyFromLocalFile(new Path("f:/update.txt"),new Path("/ignore.txt"));
// 3.关闭资源
fs.close();
}
/**
* 2.文件下载
* @throws Exception
*/
@Test
public void testCopyToLocalFile() throws Exception{
// 1.获取对象
FileSystem fs = getFileSystem();
// 2.执行下载操作
// fs.copyToLocalFile(new Path("/ignore.txt"),new Path("f:/ignore.txt"));
fs.copyToLocalFile(false,new Path("/ignore.txt"),new Path("f:/ignore.txt"),true);
// 3.关闭资源
fs.close();
}
这里我们在文件上传那里设置了一个参数,用来设置切片数。通过实验得出了如上注释的优先级结论。
在文件下载里,我们发现copyToLocalFile有两个重载方法,我们可以对第三个参数传入true代表使用原生文件系统,就不会生成本地的一些文件了。
HDFS文件删除
/**
* 3. 文件删除
* @throws Exception
*/
@Test
public void testDelete() throws Exception{
// 1.获取对象
FileSystem fs=getFileSystem();
// 2.文件的删除 第二个变量表示是否递归删除
fs.delete(new Path("/0529"),true);
// 3.关闭资源
fs.close();
}
直接上代码,没什么好说的。
文件更名
/**
* 4.文件更名
*
* @throws Exception
*/
@Test
public void testRename() throws Exception {
// 1.获取对象
FileSystem fs = getFileSystem();
// 2.文件的更名
fs.rename(new Path("/update.txt"), new Path("/yanjing.txt"));
// 3.关闭资源
}
同上,也没什么好说的。
查看文件权限信息
先来看代码:
/**
* 5.查看文件权限信息
*
* @throws Exception
*/
@Test
public void testListFiles() throws Exception {
// 1.获取对象
FileSystem fs = getFileSystem();
// 2.查看文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
// 打印信息
// 名称
System.out.println(fileStatus.getPath().getName());
// 权限
System.out.println(fileStatus.getPermission());
// 长度
System.out.println(fileStatus.getLen());
// 存储的块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
// 获取块存储的主机节点
System.out.println(host);
}
}
System.out.println("-------------分割线哦~--------------");
}
// 3.关闭资源
fs.close();
}
我们通过API获得了很多信息,这里我们获取了权限,长度,块信息,并且在块信息中也有很多可以获取的,这里只获取了块存储的主机节点。这个API还是很有用的。
判断是文件夹还是文件
/**
* 判断是文件还是文件夹
*
* @throws Exception
*/
@Test
public void testListStatus() throws Exception {
// 1.获取fs
FileSystem fs = getFileSystem();
// 2.判断操作
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
if (fileStatus.isFile()) {
System.out.println("f:" + fileStatus.getPath().getName());
}
if (fileStatus.isDirectory()) {
System.out.println("d:" + fileStatus.getPath().getName());
}
}
// 3.关闭资源
fs.close();
}
我们通过API可以判断上传的文件是一个文件还是一个文件夹,从而对其进行不同的操作。
总结
总的来说,用API操作还是十分简单的。我们只需要获取一个文件系统,然后调用API就可以了,难度不是很大。
原生IO流操作
有的时候,API不能满足我们的需求,我们就需要使用原生IO流进行操作,自己写了。
首先还是先定义一个获取文件系统的方法:
private static FileSystem getFileSystem() throws Exception {
Configuration conf = new Configuration();
return FileSystem.get(new URI("hdfs://hadoop03:9000"), conf, "liuge");
}
再定义一个通用的关闭方法,来关闭所有的流:
private void closeStream(InputStream fis, OutputStream fos) throws Exception {
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
这里使用了IOUtils,这是hadoop提供的工具。使用它我们可以很方便的关闭一些流。
文件上传与下载
/**
* 把文件上传到HDFS根目录
*/
@Test
public void putFileToHDFS() throws Exception{
// 1.获取对象
FileSystem fs = getFileSystem();
// 2.获取输入流
FileInputStream fis = new FileInputStream(new File("f:/update.txt"));
// 3.获取输出流
FSDataOutputStream fos = fs.create(new Path("/banzhang.txt"));
// 4.流的对拷
IOUtils.copyBytes(fis,fos, conf);
// 5.关闭资源
closeStream(fis, fos);
}
/**
* 从HDFS拷贝文件到本地
* @throws Exception
*/
@Test
public void getFileFromHDFS() throws Exception{
// 1.获取对象
FileSystem fs = getFileSystem();
// 2.获取输入流
FSDataInputStream fis = fs.open(new Path("/banzhang.txt"));
// 3.获取输出流
FileOutputStream fos = new FileOutputStream(new File("f:/banzhang.txt"));
// 4.流的对拷
IOUtils.copyBytes(fis,fos,conf);
// 5.关闭资源
closeStream(fis,fos);
}
可以看到,整个操作也是比较套路化的。我们先获取到文件系统对象,然后创建输入流和输出流,最后对拷就可以了。
分块拷贝
假如我现在有这样的一个需求,我只想要一个大文件的第二块(block),不想要前面的块。要实现这样的需求,我们就可以使用原生IO流:
/**
* 下载第二块
* @throws Exception
*/
@Test
public void readFileSeek2() throws Exception{
// 1.获取对象
fs = getFileSystem();
// 2.获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));
// 3.设置指定读取的起点 单位为B
fis.seek(1024 * 1024 * 128);
// 4.获取输出流
FileOutputStream fos = new FileOutputStream(new File("f:/hadoop-2.7.2.tar.gz.part2"));
// 5.流的对拷
IOUtils.copyBytes(fis,fos,conf);
// 6.关闭资源
closeStream(fis,fos);
}
这里我们传的大文件大小大概是188MB。按照hadoop的分片规则,会分为两块。
可以看到,因为HDFS默认的块大小为128MB,我们这里就按照128MB对输入流进行了定位,然后获取到了128MB以后的块,即第二块。
总结
总的来说,对HDFS的操作还是比较简单的。只需要多加练习就好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号