搭建Hadoop集群
写在前面
按照老师的要求,来学习大数据了。大数据中hadoop体系占据着很大一部分,要学习hadoop相关内容就要先搭建好他的集群。这里就记录一下如何搭建一个hadoop集群。
原文地址:搭建hadoop集群笔记
前期准备
- 三台虚拟机(关闭了防火墙,设置好了静态ip,mac地址和主机名称,安装了JDK和hadoop,并设置了环境变量),如下图:
下面演示一下如何配置一台主机,剩下两台直接克隆(Vmware软件里右键虚拟机管理里有克隆,选择完整克隆)即可。这里使用的是centos7系统。
-
关闭防火墙
在终端界面输入命令
systemctl status firewalld.service查看防火墙状态,active(running)代表正在运行。
输入命令
systemctl stop firewalld.service来停止防火墙,再使用上面的命令查看是否关闭。如果出现disactive(dead)则表示已关闭。
输入命令
systemctl disable firewalld.service来将防火墙的开机自启关闭,永久关闭防火墙。
-
修改主机名
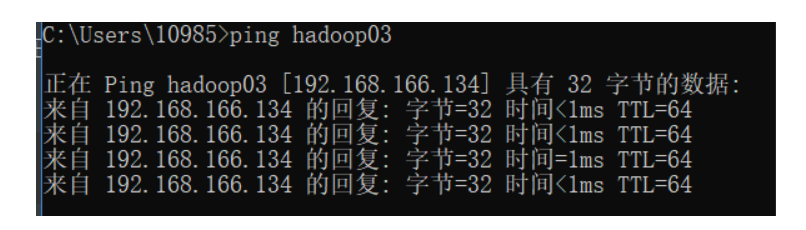
见该文章:centos7修改主机名 并且按照教程来配置好主机名和ip的映射(linux里的hosts文件和windows里的hosts文件),方便日后使用。在设置完后可以在命令行用主机名ping测试一下:
-
创建自己的用户账号,并赋予root权限:
在安装centos7时就会让你创建一个自己的账号,只需要让它具有root权限即可。
修改/etc/sudoers文件,找到如下图的地方:

在root用户下面一行添加你的用户账号,按照上面的格式写就行。
-
在/opt目录下创建module和software文件夹:
sudo mkdir module sudo mkdir software修改module和software的所有者cd
sudo chown liuge:liuge module/ software/这里的liuge是我自己的用户,设置成你自己的就行。
-
安装JDK和hadoop
查看是否安装java软件:
rpm -qa | grep java如果安装版本低于1.8,卸载它:
sudo rpm -e 软件包用ssh软件将jdk和hadoop的gz包传到/opt/software下,这里我用的是MobaXterm
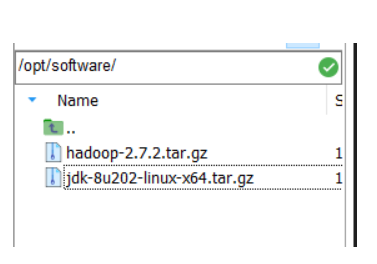
这里使用的是jdk1.8和hadoop2.7.2的版本。
将jdk解压到/opt/module下:
tar -zxvf jdk-8u202-linux-x64.tar.gz -C /opt/module/也把hadoop解压到opt/module/下:
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/接下来配置环境变量。
我们首先获取到jdk的路径和hadoop的路径:
[liuge@hadoop03 jdk1.8.0_202]$ pwd /opt/module/jdk1.8.0_202 [liuge@hadoop03 hadoop-2.7.2]$ pwd /opt/module/hadoop-2.7.2用vim编辑/etc/profile文件:
sudo vim /etc/profile在profile文件的末尾添加JDK和hadoop路径:
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_202 export PATH=$PATH:$JAVA_HOME/bin ##HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin保存后退出(esc :wq)。
让修改后的文件生效:
source /etc/profile查看是否配置完成:
java -version hadoop version如果有版本信息出现,则说明配置完成了。
-
设置mac地址和静态IP
当克隆出新的主机后,先不要打开,用Vmware打开该虚拟机设置,网络适配器,高级,重新生成一个mac地址。
设置静态IP,直接通过图形化界面操作即可。
-
为了方便日后使用,我们编写一个脚本用来集群分发各种配置文件等等。
在/home/liuge 目录下创建bin目录,并在bin目录下创建xsync文件。这里的路径就是你的用户home。在里面写入如下内容:
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=3; host<6; host++)); do echo ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname $user@hadoop0$host:$pdir done这里的循环代码里的条件要换成你自己的虚拟机名称。
修改脚本xsync具有执行权限:
chmod 777 xsync要使用脚本,直接xsync+文件名称即可:
xsync /home/liuge/bin -
配置ssh无密登录
我们进入第一台主机(hadoop03)的/home/liuge/.ssh目录下,生成公钥和私钥:
ssh-keygen -t rsa如果没有这个目录,就先用ssh命令连接一下别的主机。
然后将公钥拷贝到免密登录的机子上:
ssh-copy-id hadoop03 ssh-copy-id hadoop04 ssh-copy-id hadoop05按照这个操作,我们再在hadoop03上用root账号配置一下免密登录到hadoop03、04、05。并且在hadoop04上用liuge账号(自己的账号)配置一下hadoop04免密登录到hadoop03、hadoop04、hadoop05上。
集群配置
首先我们要规划好如何分配:
| hadoop03 | hadoop04 | hadoop05 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManger | NodeManager |
接下来开始设置配置文件。
注意,配置xml时要把property标签都放在configuration标签里,如图
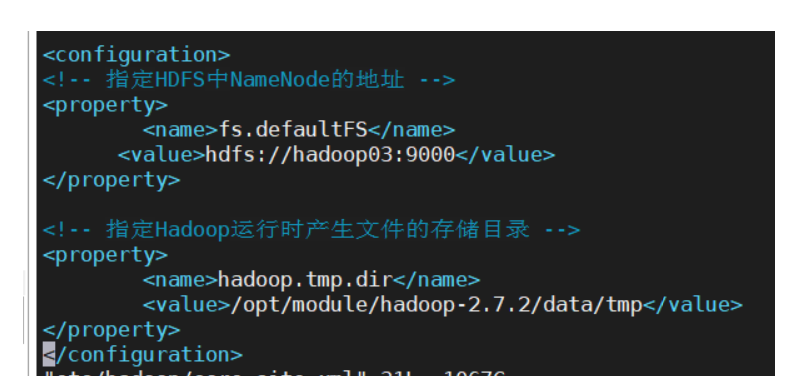
core-site.xml
在/opt/module/hadoop-2.7.2/etc/hadoop 下,打开core-site.xml文件,添加如下内容:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop03:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
hadoop-env.sh
还是在当前目录下,打开hadoop-env.sh,配置JAVA_HOME:
export JAVA_HOME=/opt/module/jdk1.8.0_202
hdfs-site.xml
依然是当前目录,打开hdfs-site.xml文件,添加如下内容:
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop05:50090</value>
</property>
yarn-env.sh
当前目录,打开yarn-env.sh,添加JAVA_HOME:
export JAVA_HOME=/opt/module/jdk1.8.0_202
yarn-site.xml
当前目录,打开yarn-site.xml,添加如下配置:
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop04</value>
</property>
mapred-env.sh
当前目录,打开mapred-env.sh,配置JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_202
mapred-site.xml
当前目录,将mapred-site.xml.template改名为mapred-site.xml,并打开:
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
添加如下配置文件:
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置slaves
当前目录下,打开slaves文件,加入如下内容:
hadoop03
hadoop04
hadoop05
这里写好自己的集群名称(这里需要前面配置了映射,如果没配置请往上翻),同时这个文件不允许有空格或者空行。
分发配置文件
运用我们刚才写的xsync脚本,将配置文件分发:
xsync /opt/module/hadoop-2.7.2/
启动集群
我们在hadoop03(配置了NameNode)的机子上,在/opt/module/hadoop-2.7.2目录下,输入以下命令启动HDFS:
sbin/start-dfs.sh
同理,可以使用stop-dfs.sh来停止HDFS:
sbin/stop-dfs.sh
在hadoop04(配置了ResourceManager)的机子上,在/opt/module/hadoop-2.7.2目录,输入以下命令启动yarn:
sbin/start-yarn.sh
同理,停止:
sbin/stop-yarn.sh
网页测试
在web端进行测试,看看是否启动了。比如hadoop03:50070(我这里是在windows设置了映射,实际还是ip地址),打开HDFS的管理界面。
可以使用hadoop05:50090打开SecondNameNode的界面。
如果打不开,请按照上面的流程再检查一遍。
总结
总的来说,搭建一个hadoop集群还是不容易的。不过如果配置完一次,下一次直接启动就好了。还是比较方便的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号