分布式全文检索服务器——ElasticSearch(1)
写在前面
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单
ElasticSearch的使用
从官网下载好后,找到bin目录下的
双击,等待启动。之后从浏览器访问看到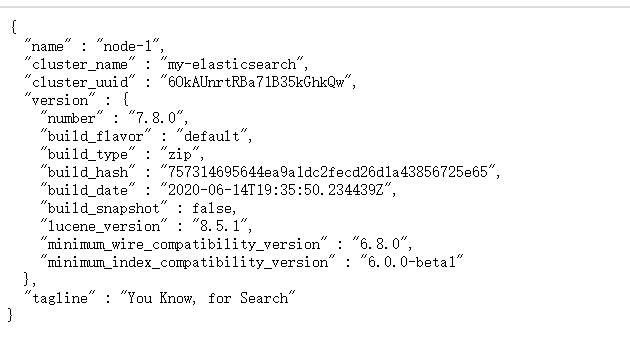
即证明启动成功了。
ElasticSearch图形化界面插件——elasticsearch-head
从github上下载该插件的最新版后,安装node.js启动该服务,在浏览器输入http://localhost:9100/即可访问:
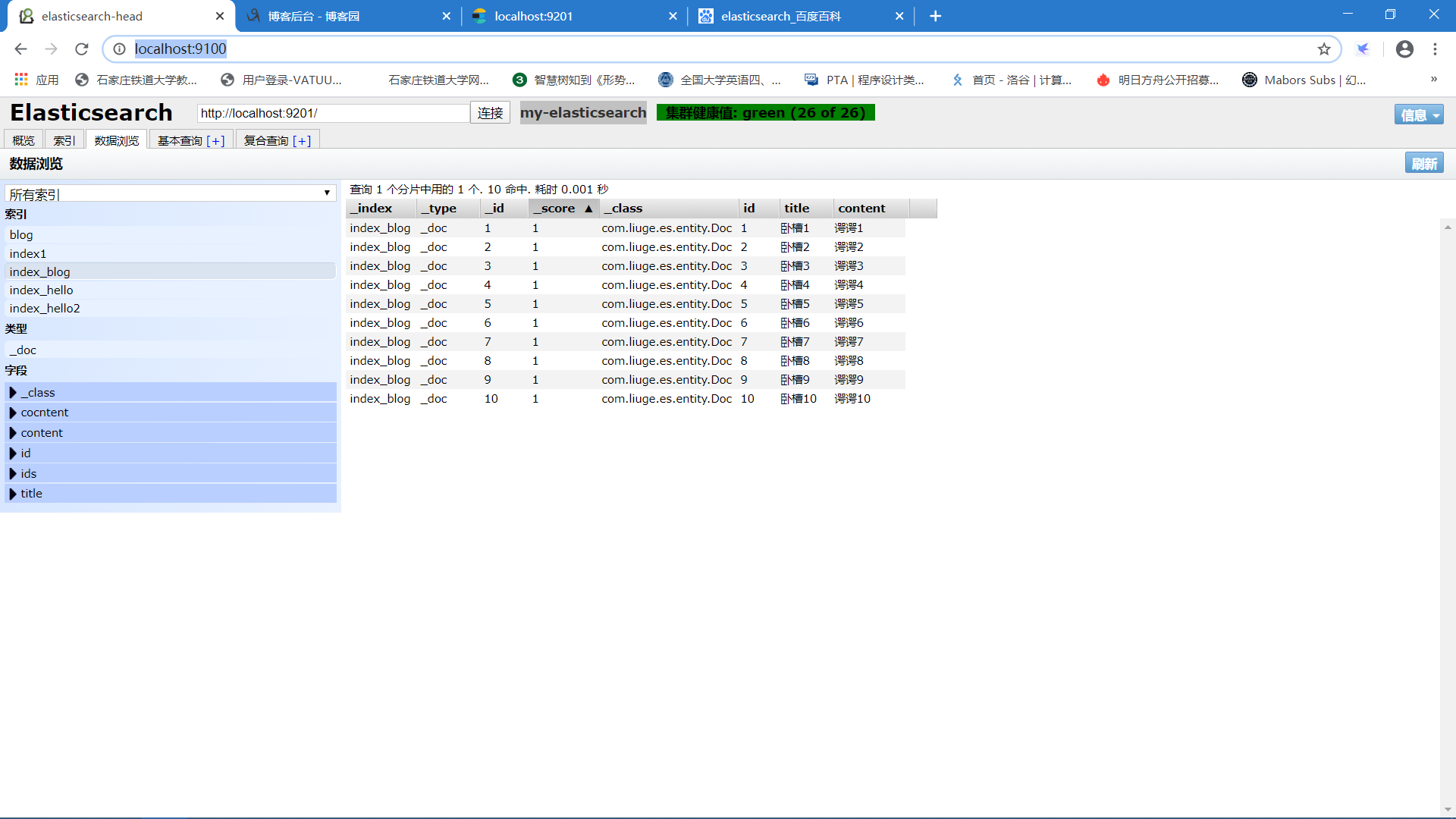
ElasticSearch中的一些核心概念
索引 index
一个索引就是一个拥有几分相似的文档的集合,类似于数据库的概念。
类型 type
该属性已经在最新版ElasticSearch中被抛弃,只允许_doc的type,不再允许自定义type
字段Field
相当于数据库中的表字段。
映射 mapping
其实就是对一些处理数据的方式和规则方面做一些限制,一些约定俗成的东西。
文档 Docuemnt
文档物理上是存在于一个索引中的,文档都用json格式来表示。
集群,节点,分片和复制
见图:
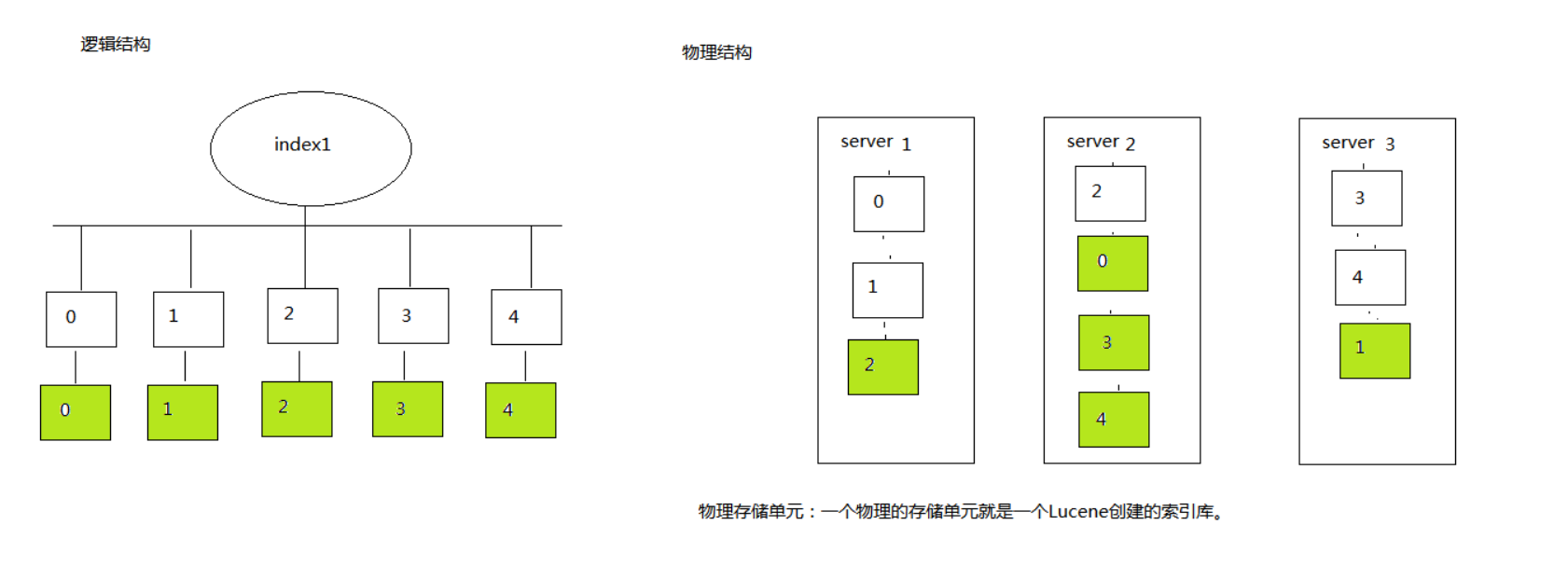
集群就是物理上结构,如图中的三台服务器,每个服务器都叫一个节点。每个index下有多个分片,同时分片有复制。复制主要是为了防止某台服务器出故障后整体服务器还可以继续运行。
通过PostMan来使用ElasticSearch
ElasticSearch使用了Restful的风格,即通过不同类型的请求来分别处理请求而不写参数。我们可以通过postman来完成一些请求。
创建索引index和mapping
请求使用json格式字符串:
{
"mappings":{
"properties":{
"id":{
"type":"long",
"store":true
},
"title":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
},
"cocntent":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
}
}
}
}
创建索引后设置mapping
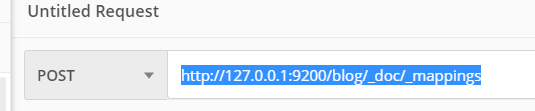
{
"properties":{
"id":{
"type":"long",
"store":true
},
"title":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
},
"cocntent":{
"type":"text",
"store":true,
"index":true,
"analyzer":"standard"
}
}
}
删除index
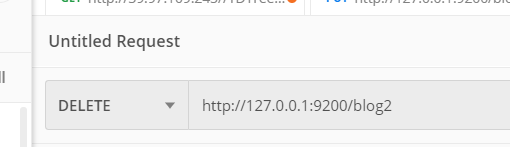
写不写参数都可以
创建文档

{
"id":1,
"title":"新添加的文档",
"content":"新添加的文档的内容"
}
修改文档
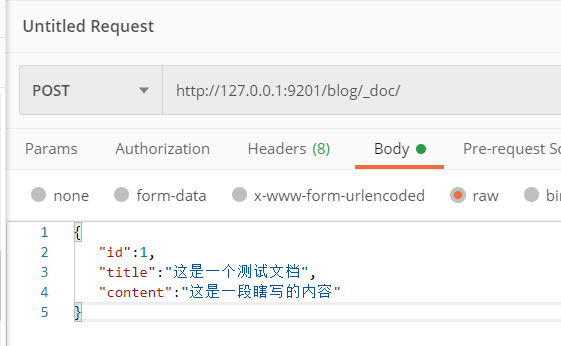
{
"id":1,
"title":"这是一个测试文档",
"content":"这是一段瞎写的内容"
}
修改文档和创建文档基本是一样的,因为在ElasticSearch中修改文档就是先删除后创建
删除文档

根据id查询文档
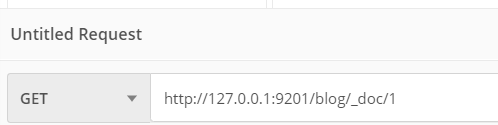
在_doc/后写上文档的id即可。
queryString查询
{
"query":{
"query_string":{
"default_field":"title",
"query":"修改"
}
}
}
term查询
{
"query":{
"term":{
"content":"爱"
}
}
}
中文分词插件
从github上下载IK分词器,按照教程装好后重启ElasticSearch。
之后我们在创建索引时指定分词器:
{
"mappings":{
"properties":{
"id":{
"store":true,
"type":"long"
},
"title":{
"store":true,
"analyzer":"ik_smart",
"type":"text"
},
"content":{
"store":true,
"analyzer":"ik_smart",
"type":"text"
}
}
}
即可使用中文分词器了。
集群
其实在实际开发中,很少使用单机。一般都会使用集群。这里就不再多讲集群的使用了,比较复杂,需要的可以百度搜索一下。
总结
可以看到ElasticSearch还是十分复杂的,不仅是配置还是操作。接下来会学习一下使用java客户端来对其进行操作。
