
使用python爬取B站弹幕和三连
写在前面
今天和朋友唠嗑,说着说着说到了爬取B站弹幕和三连的事情。于是就想着用python来试试爬取B站的弹幕和三连了
代码
不废话了,先上代码:
# 爬取B站弹幕
import requests
import time
import json
from lxml import etree
# 放入要爬的url
# 弹幕api
url_b = "https://api.bilibili.com/x/v1/dm/list.so?oid=186339235"
# 三连api
url_state = "https://api.bilibili.com/x/web-interface/archive/stat?aid=925611776"
# 设置header
header = {"user-agent": "Mozilla/5.0 (Linux; Android 8.0.0; Pixel 2 XL Build/OPD1.170816.004) "
+ "AppleWebKit/537.36 (KHTML, like Gecko)"
+ " Chrome/80.0.3987.116 Mobile Safari/537.36"}
# 获取信息
try:
# 延时操作,防止爬的太快
time.sleep(0.5)
response = requests.get(url_b, headers=header)
except Exception as e:
print(e)
else:
if response.status_code == 200:
# 下载xml文件
with open("bilibili.xml", 'wb') as f:
f.write(response.content)
# 解析网页
time.sleep(1)
# 文件路径,html解析器
html = etree.parse('bilibili.xml', etree.HTMLParser())
# xpath解析,获取当前所有的d标签
results = html.xpath('//d//text()')
i = 0
sum_self = 0
for result in results:
sum_self = sum_self + 1
if result.find("飞"):
i = i+1
print("总数为: %d 包含飞字的弹幕为:%d" % (sum_self, i))
data_get = requests.get(url_state, headers=header)
data_san = json.loads(data_get.content.decode())
print("硬币为:%d" % data_san['data']['coin'])
print("转发为: %d" % data_san['data']['share'])
print("点赞为:%d" % data_san['data']['like'])
这里关于找api的操作,可以自行用火狐或者谷歌的开发者模式去寻找。
在这里由于B站的弹幕是用xml存的,且最大弹幕量是1000,即只爬了一千条弹幕。
思路分析
首先找一个B站视频,然后寻找弹幕和三连的API:
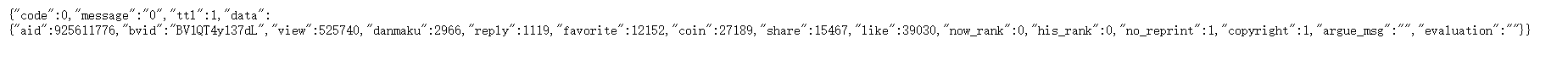
首先发现了这个,阅读英文后发现明显就是三连的英文。
就是简单的json格式,关于json格式的处理已经练习过嘞
然后找弹幕,发现是xml文件:

观察结构可以发现弹幕都是在d标签里的。上次爬取论文的时候也用了类似的操作,我们直接读取d标签的内容即可。
这里我们就用xpath来很方便的找到。关于xpath的语法等有空再开个博客写一写。
结果
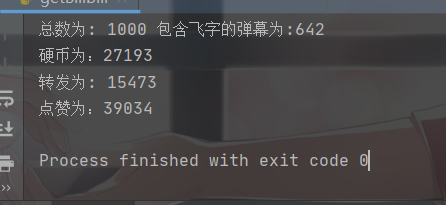
可以看到爬取B站弹幕和三连非常方便,也体会到了python在某些领域的优势。
