搭建高可用mongodb集群--副本集
由于mongDB已经不支持主从

现在提到了几个问题?
- 节点挂了如何处理。
- 节点的读写压力过大如何解决?
- 数据压力大到机器支撑不了的时候能否做到自动扩展?
这篇文章看完这些问题就可以搞定了。NoSQL的产生就是为了解决大数据量、高扩展性、高性能、灵活数据模型、高可用性。但是光通过主从模式的架构远远达不到上面几点,由此MongoDB设计了副本集和分片的功能。这篇文章主要介绍副本集
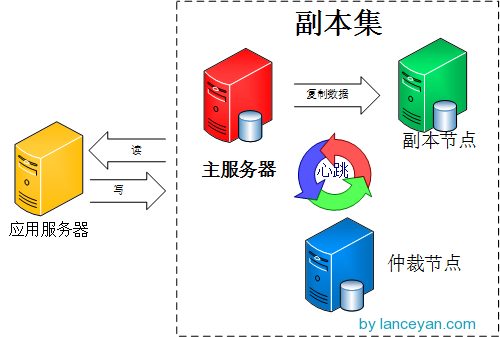
mongoDB的副本也是这个,主从模式其实就是一个单副本的应用,没有很好的扩展性和容错性。而副本集具有多个副本保证了容错性,就算一个副本挂掉了还有很多副本存在,并且解决了上面第一个问题“主节点挂掉了,整个集群内会自动切换”。难怪mongoDB官方推荐使用这种模式。我们来看看mongoDB副本集的架构图:
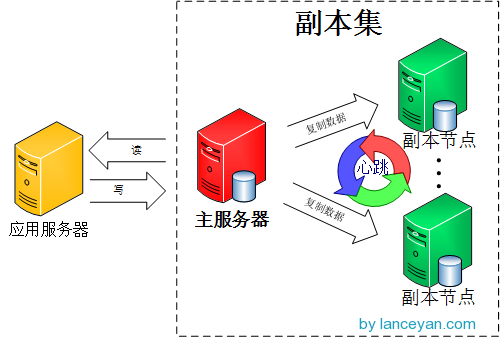
由图可以看到客户端连接到整个副本集,不关心具体哪一台机器是否挂掉。主服务器负责整个副本集的读写,副本集定期同步数据备份,一但主节点挂掉,副本节点就会选举一个新的主服务器,这一切对于应用服务器不需要关心。我们看一下主服务器挂掉后的架构:
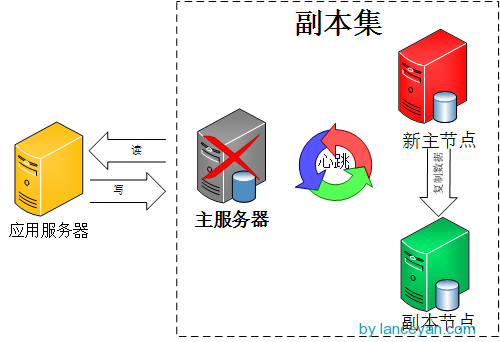
官方推荐的副本集机器数量为至少3个
我们安装好三个并启动三个实例:

初始化副本集 随意登陆三台服务器中任意一台
./mongo --host 10.10.0.114 --port 27017
use admin
#定义副本集配置变量,这里的 _id:”repset” 和上面命令参数“ –replSet repset” 要保持一样。
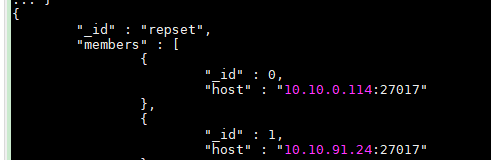
config = { _id:"repset", members:[
{_id:0,host:"10.10.0.114:27017"},
{_id:1,host:"10.10.91.24:27017"},
{_id:1,host:"10.10.91.24:27017"}]
}
输出
#初始化副本集配置
> rs.initiate(config);
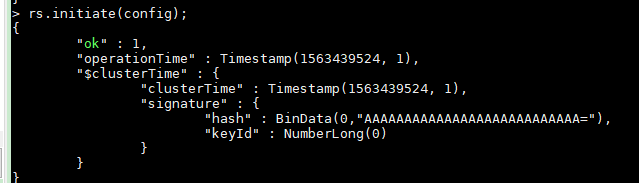
查看日志,副本集启动成功后,114为主节点PRIMARY,其他为副本节点SECONDARY。

#查看集群节点的状态 rs.status();
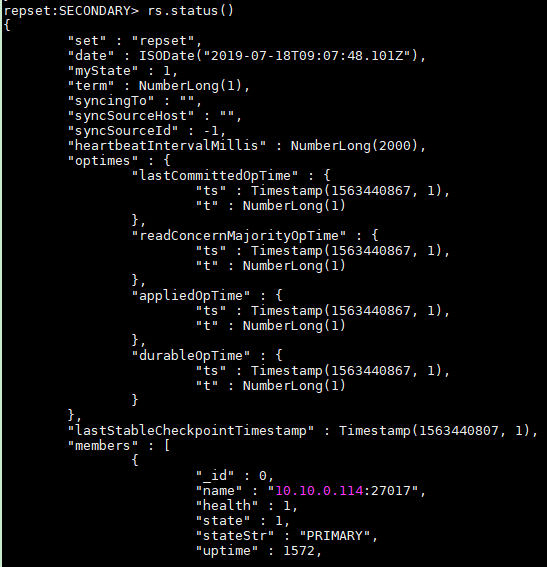
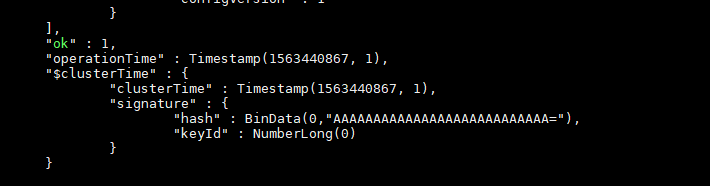
现在测试数据
主节点现在有四条数据,我们删除两条,修改剩下两条数据
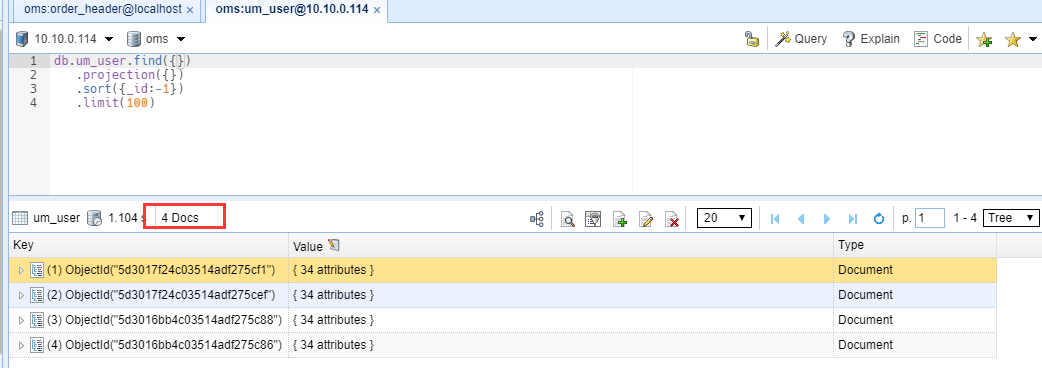
从节点剩下两条数据
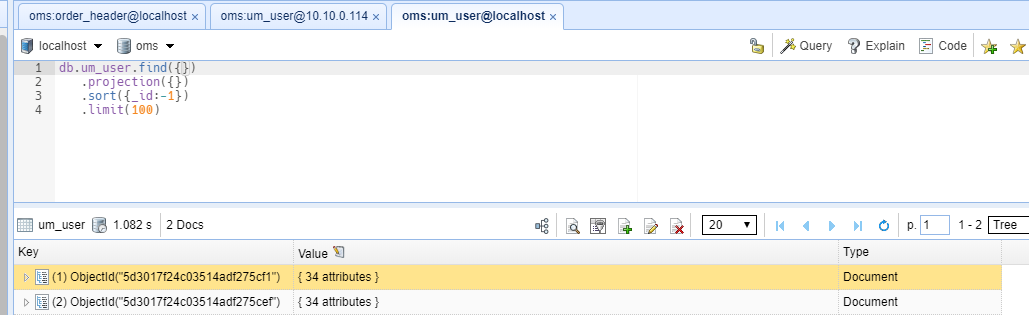
修改的也同步过来了
故障测试也没问题
目前看起来支持完美的故障转移了,这个架构是不是比较完美了?其实还有很多地方可以优化,比如开头的第二个问题:主节点的读写压力过大如何解决?常见的解决方案是读写分离,mongodb副本集的读写分离如何做呢?
常规写操作来说并没有读操作多,所以一台主节点负责写,两台副本节点负责读。
1、设置读写分离需要先在副本节点SECONDARY 设置 setSlaveOk。
primary:默认参数,只从主节点上进行读取操作;
primaryPreferred:大部分从主节点上读取数据,只有主节点不可用时从secondary节点读取数据。
secondary:只从secondary节点上进行读取操作,存在的问题是secondary节点的数据会比primary节点数据“旧”。
secondaryPreferred:优先从secondary节点进行读取操作,secondary节点不可用时从主节点读取数据;
nearest:不管是主节点、secondary节点,从网络延迟最低的节点上读取数据。
好,读写分离做好我们可以数据分流,减轻压力解决了“主节点的读写压力过大如何解决?”这个问题。不过当我们的副本节点增多时,主节点的复制压力会加大有什么办法解决吗?mongodb早就有了相应的解决方案。
Secondary-Only:不能成为primary节点,只能作为secondary副本节点,防止一些性能不高的节点成为主节点。
Hidden:这类节点是不能够被客户端制定IP引用,也不能被设置为主节点,但是可以投票,一般用于备份数据。
Delayed:可以指定一个时间延迟从primary节点同步数据。主要用于备份数据,如果实时同步,误删除数据马上同步到从节点,恢复又恢复不了。
Non-Voting:没有选举权的secondary节点,纯粹的备份数据节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号