django框架(部分讲解)
图书管理系统讲解
前期准备工作
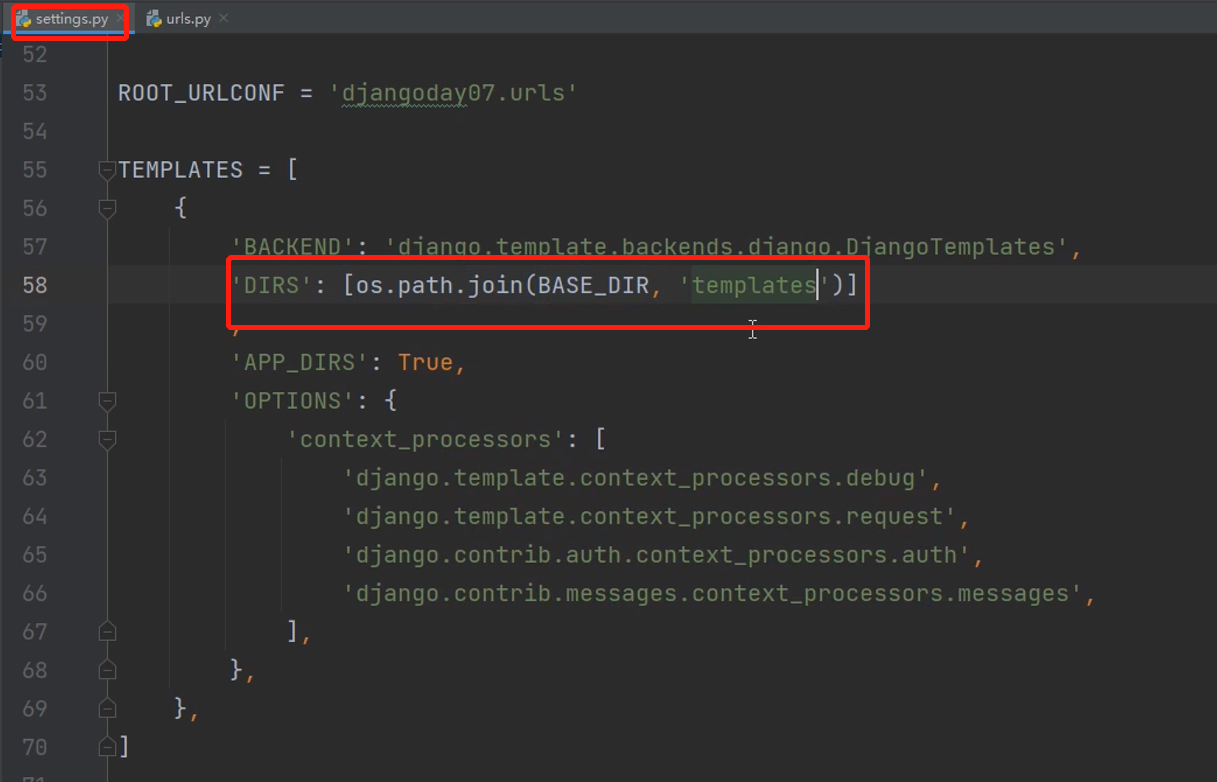
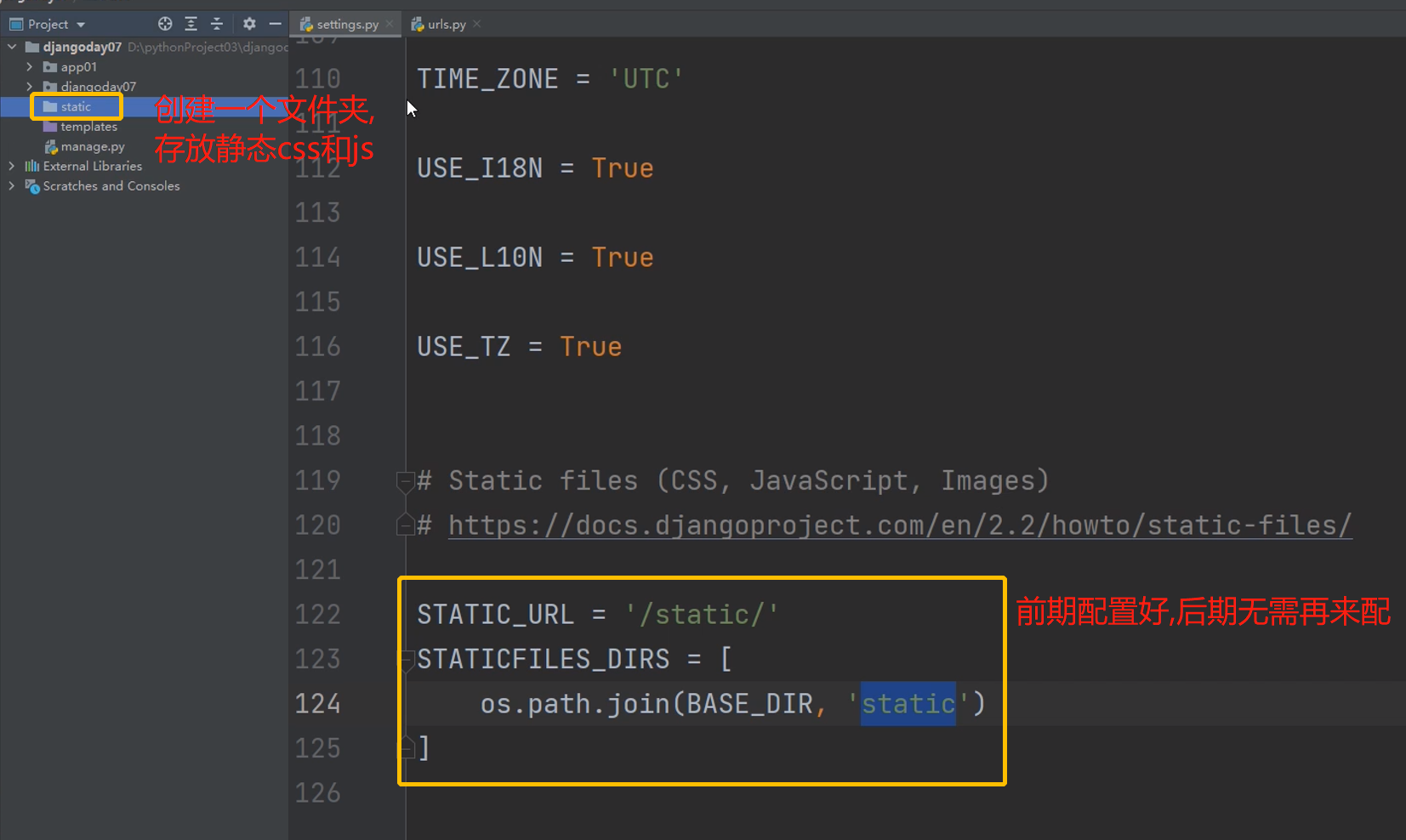
修改配置文件

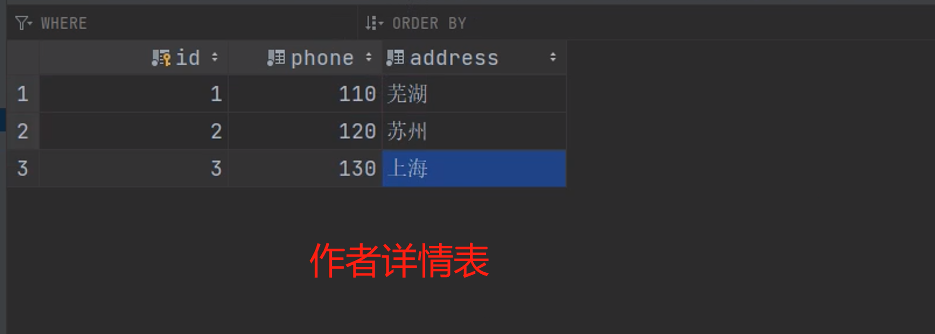
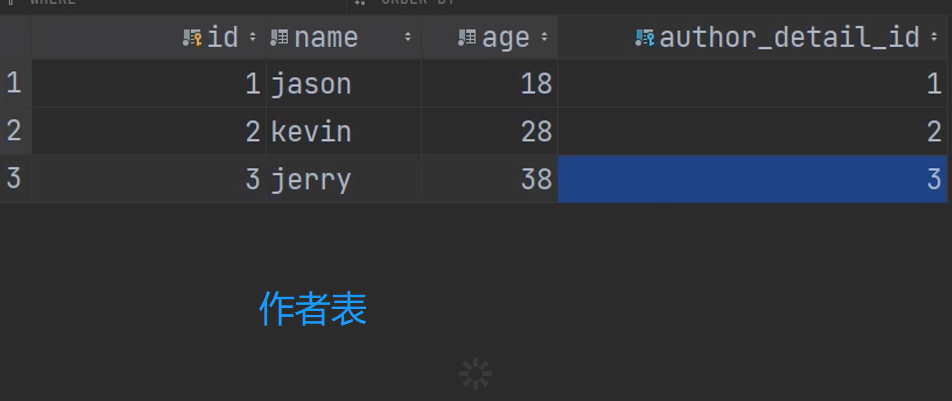
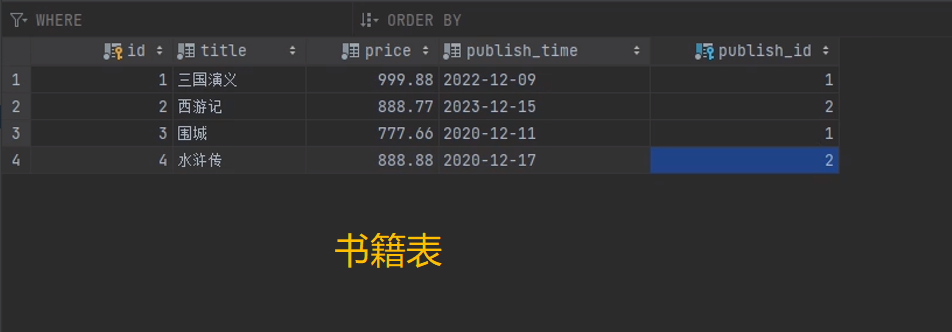
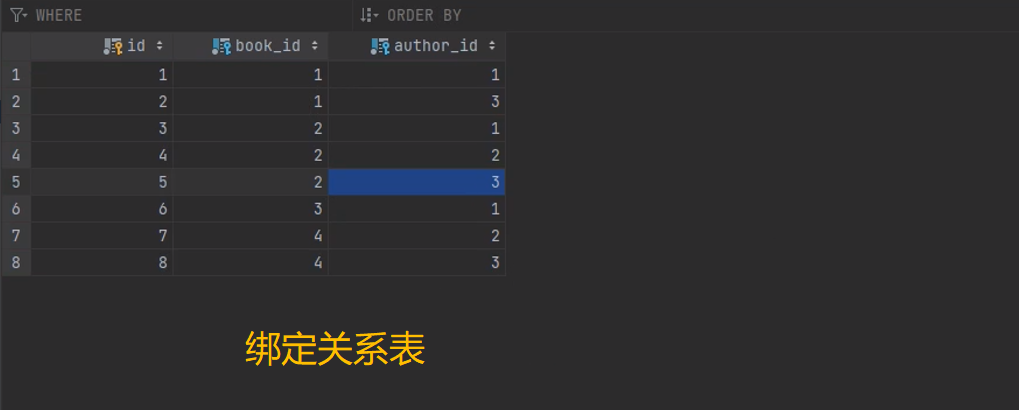
表设计
考虑普通字段
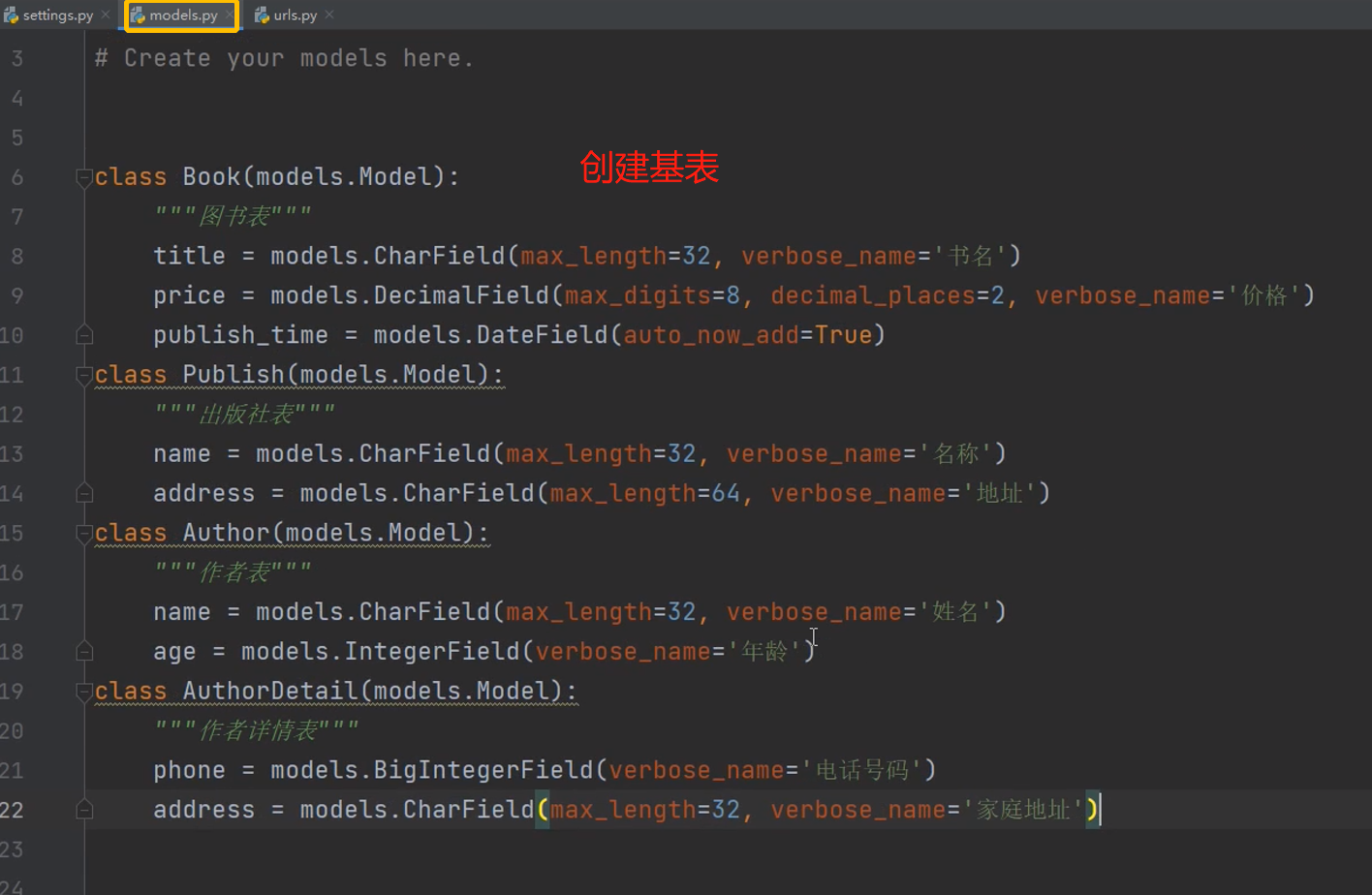
考虑外键字段
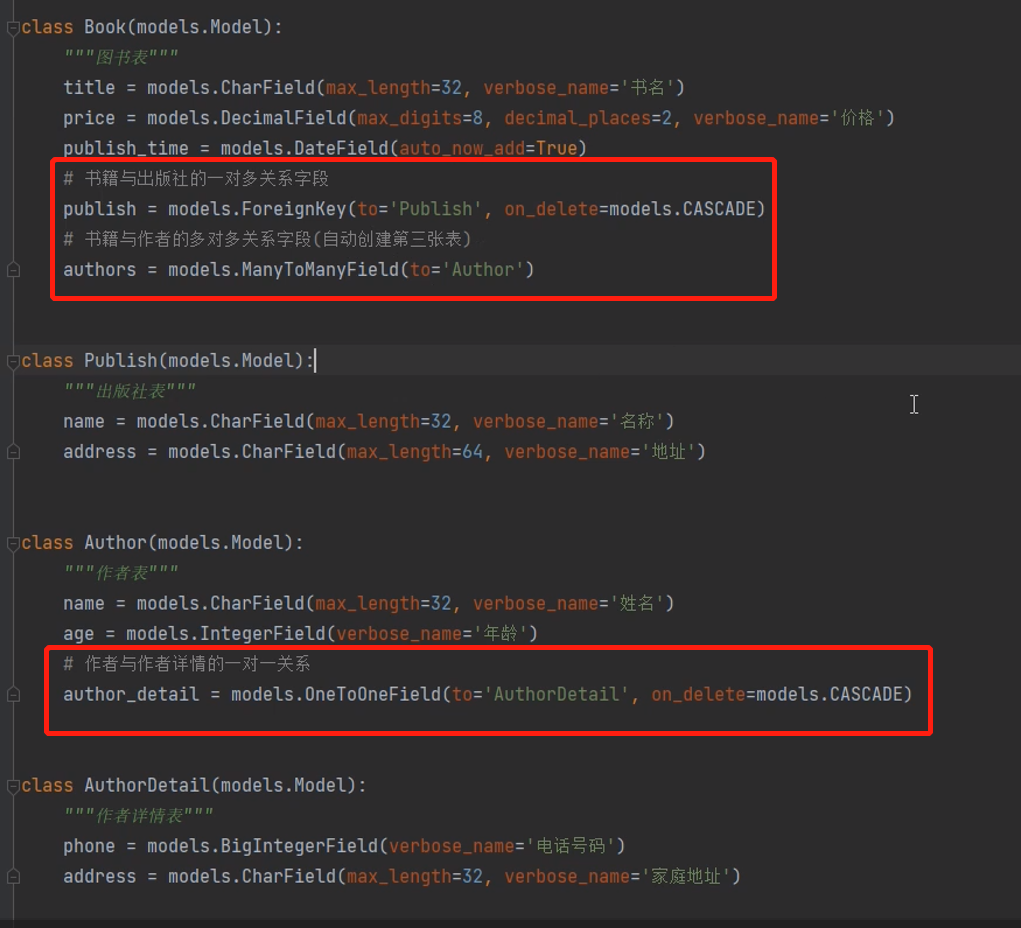
数据库迁移
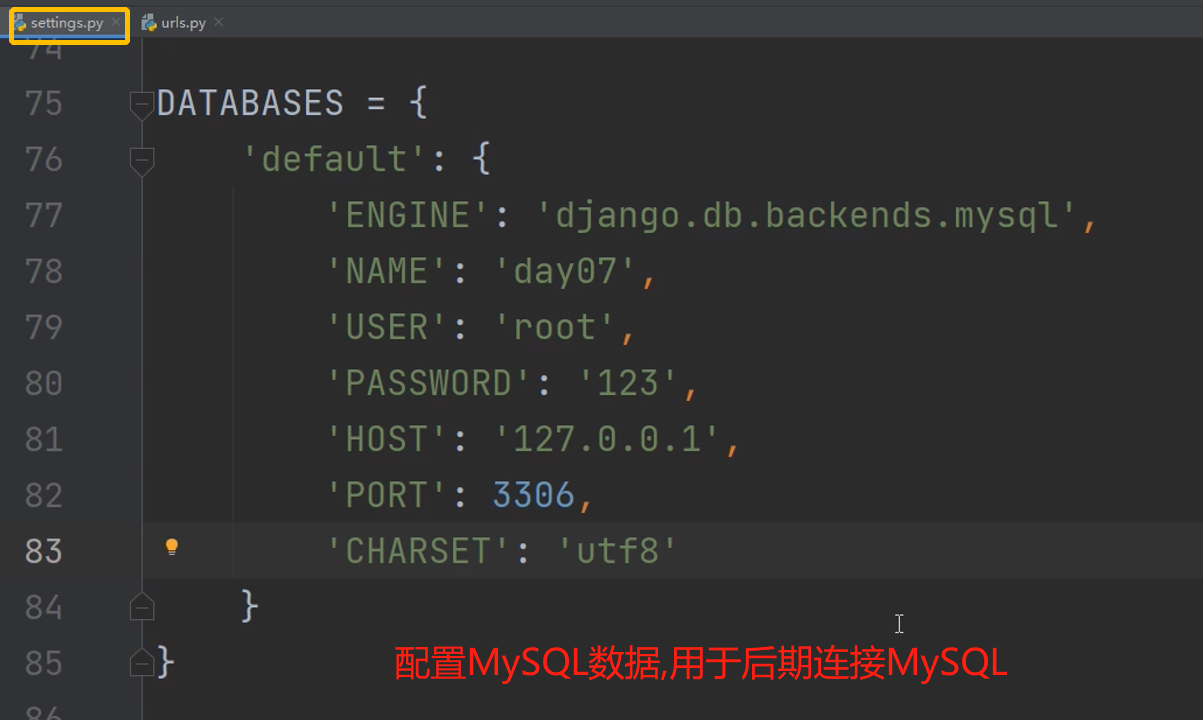
连接数据库
插入数据,测试数据录入
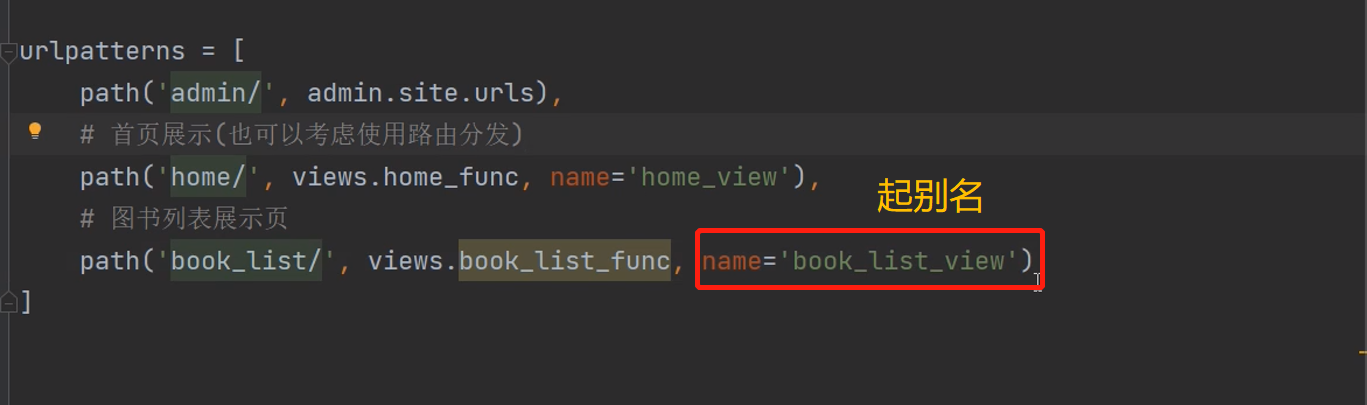
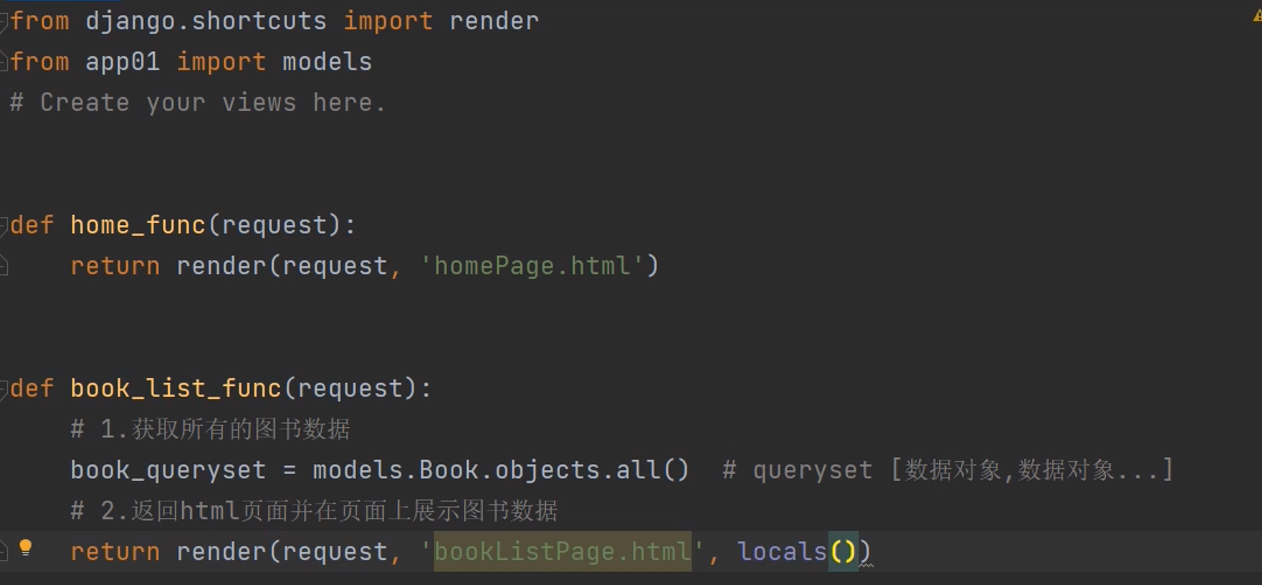
首页展示
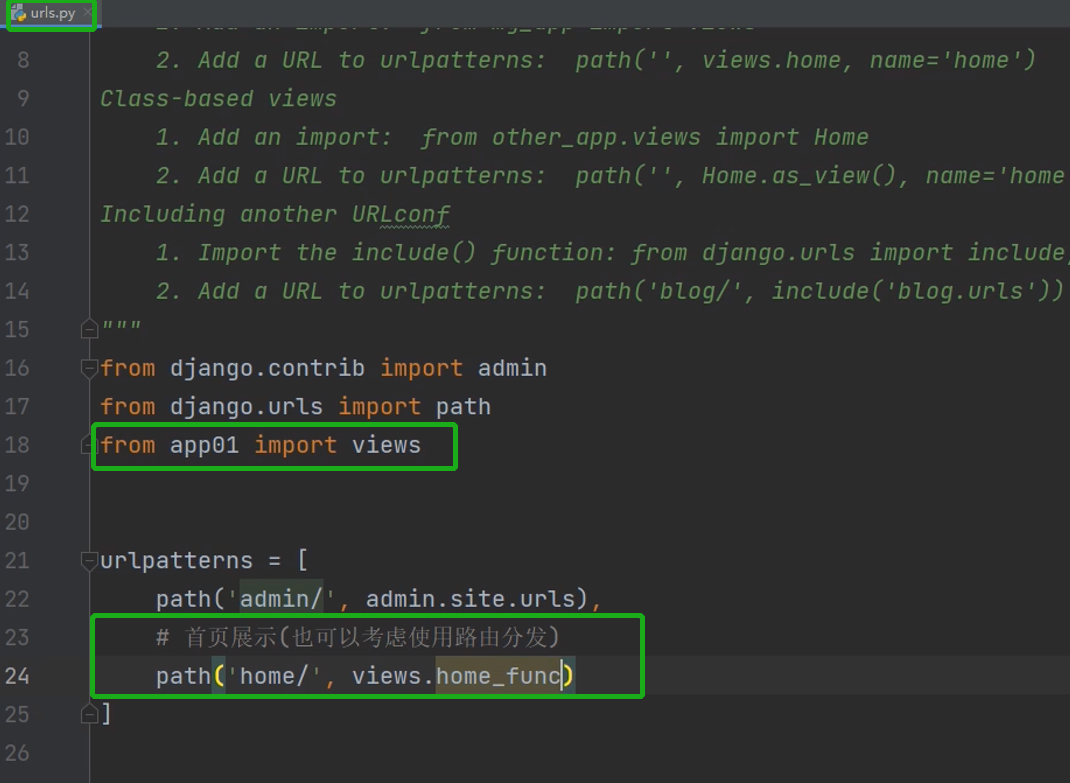
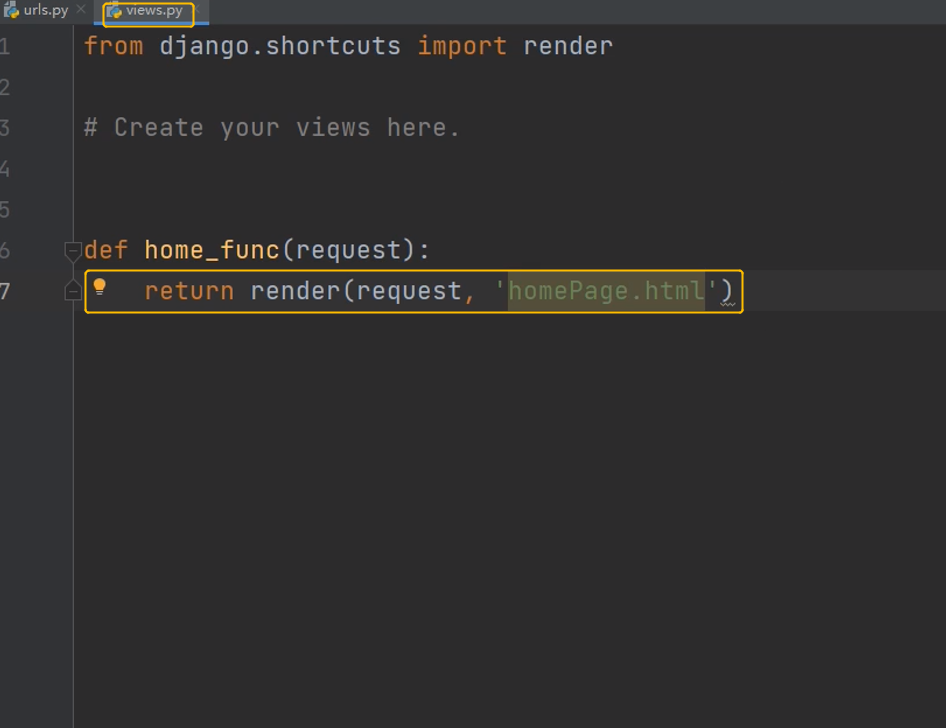
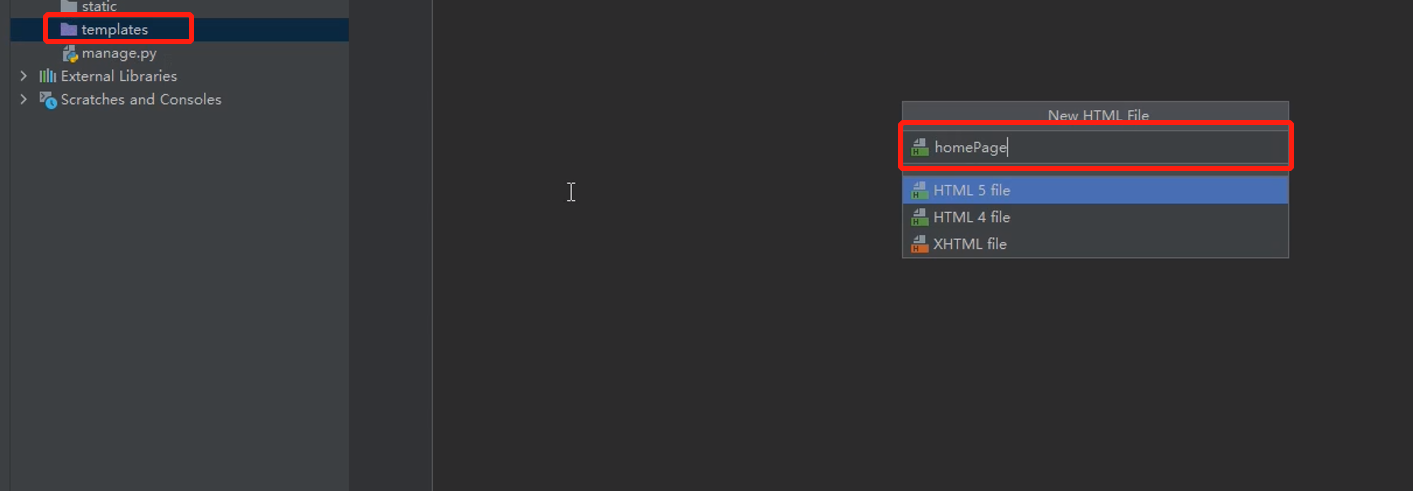
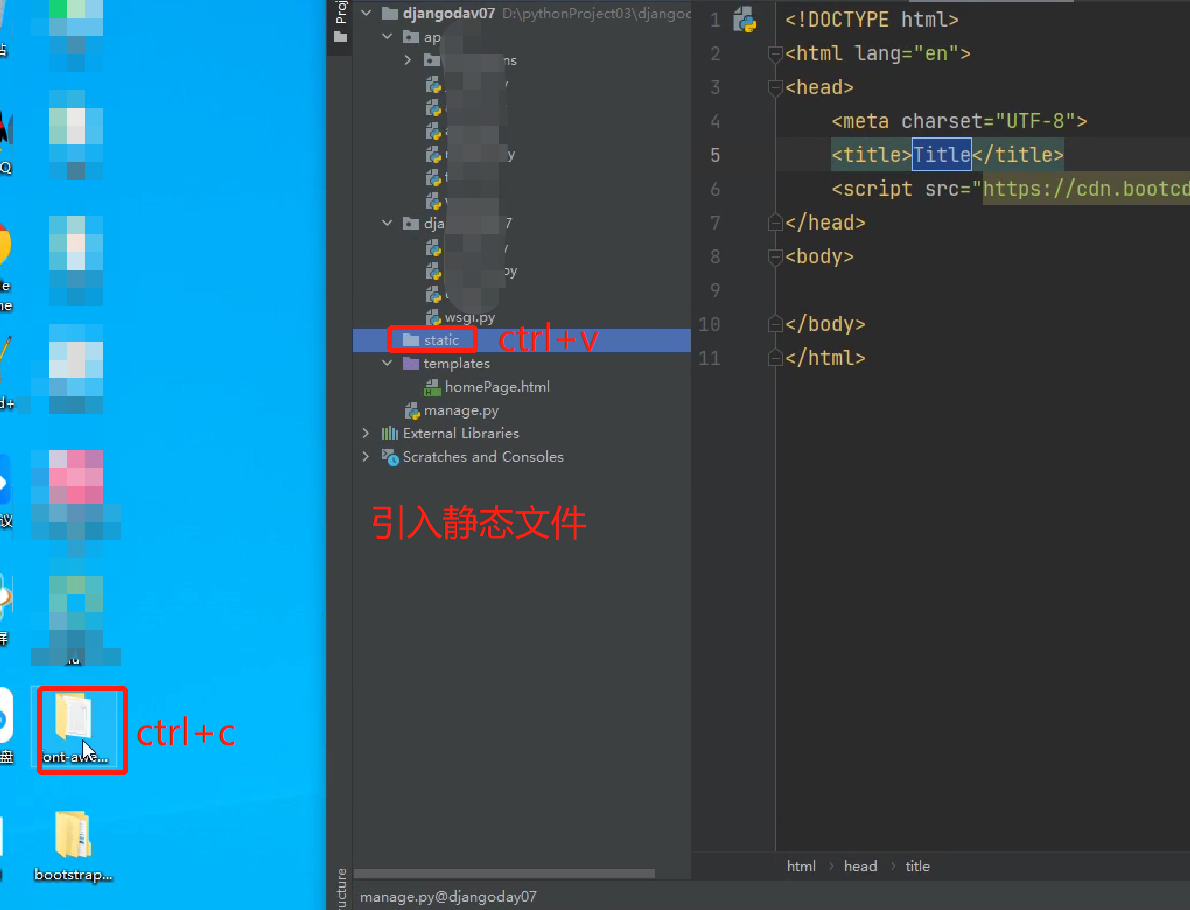
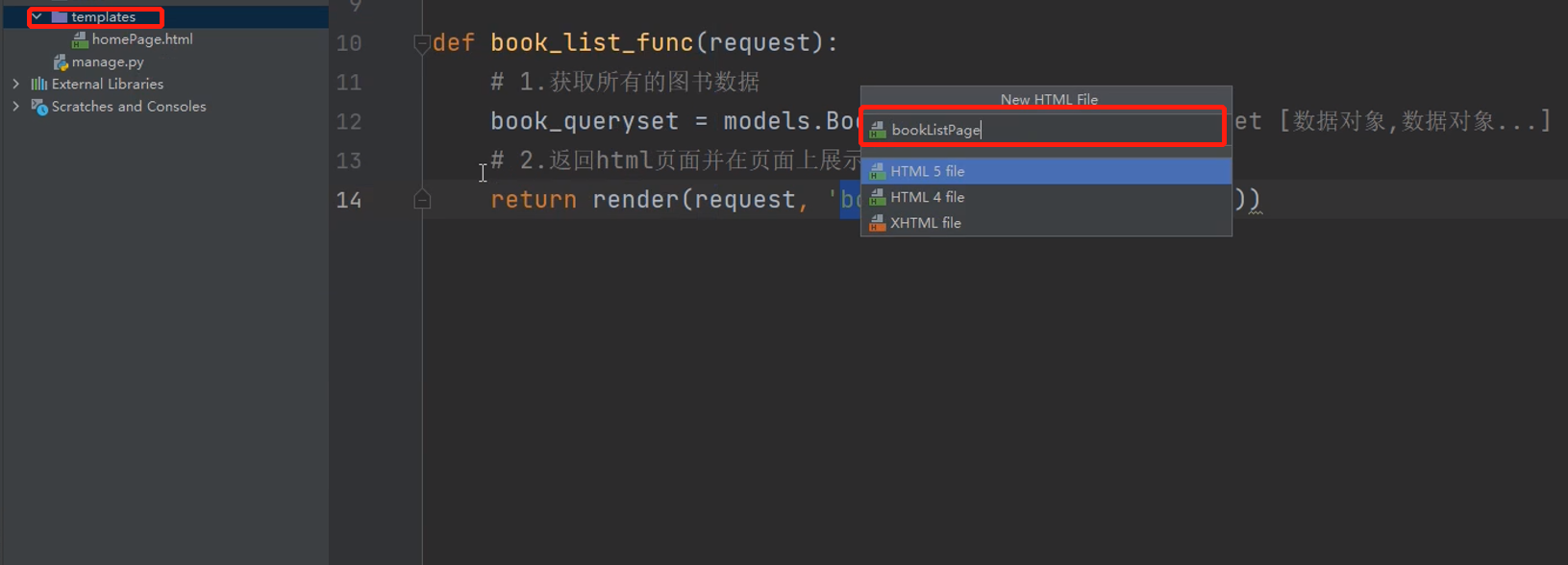
创建一个html页面,配置静态文件
动态匹配

添加样式
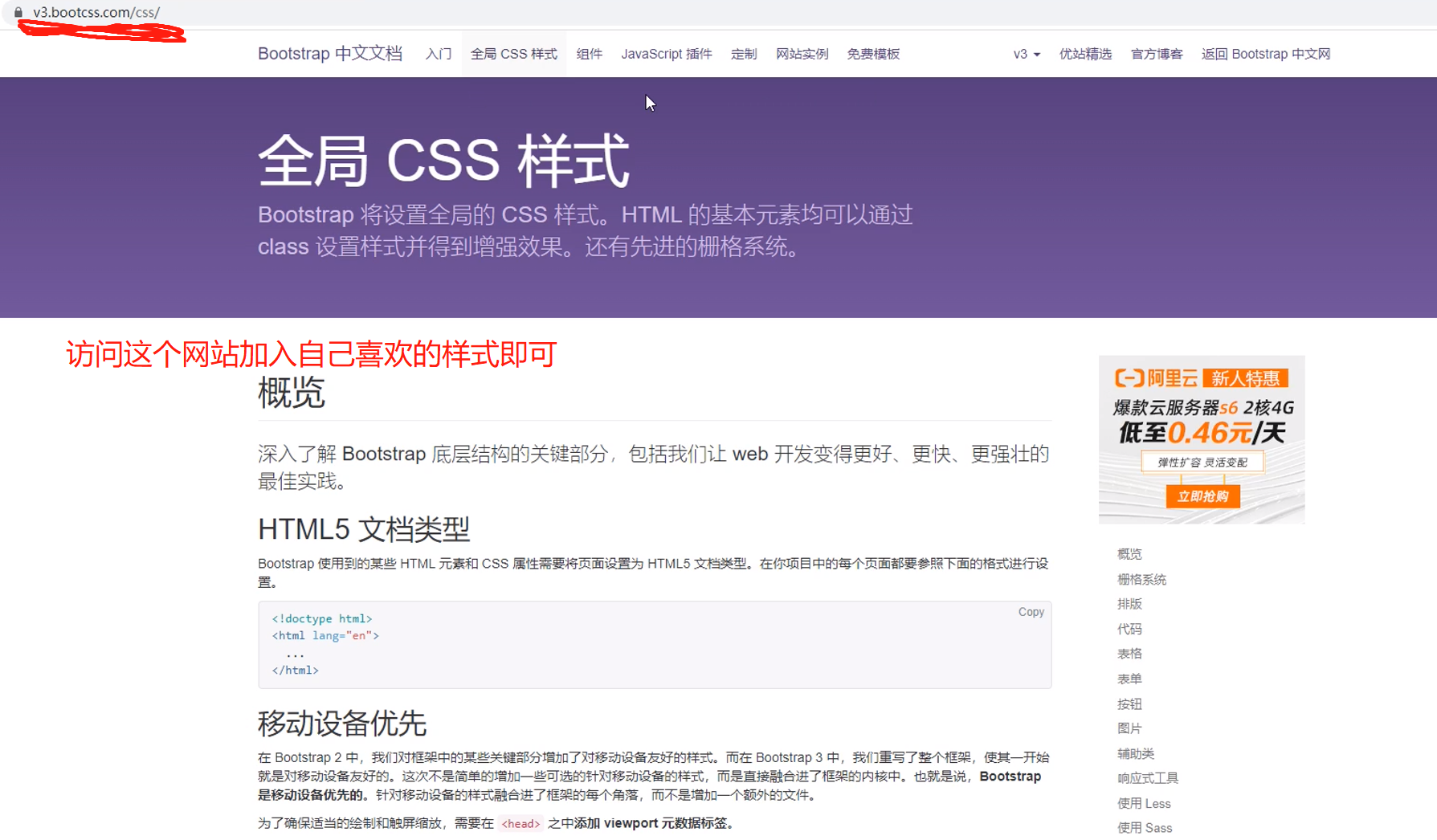
书籍展示
创建一个html页面
继承首页展示
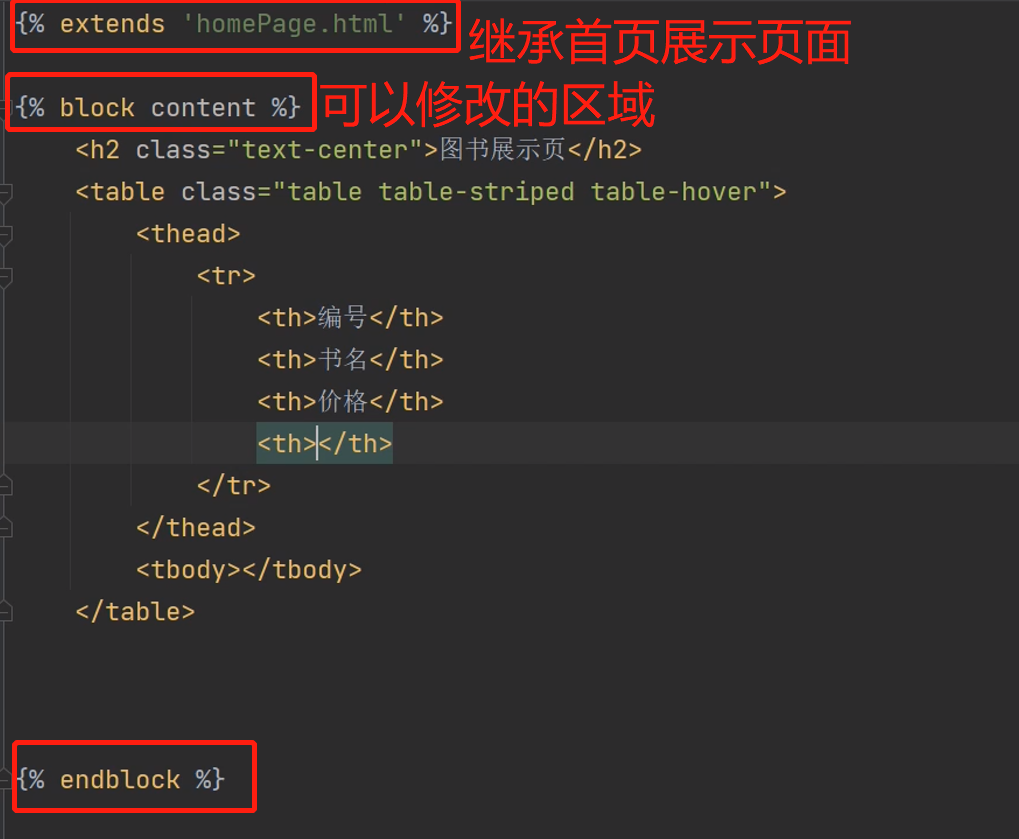
设置继承后可以修改的区域
书籍添加
与上面操作一致
书籍编辑
后端如何获取用户想要编辑的数据、前端如何展示出待编辑的数据
书籍删除
与上面操作一致
聚合查询
在ORM中支持单独使用聚合函数,需要使用aggregate方法。
聚合函数:Max最大、Min最小、Sum总和、Avg平均、count统计
示例1
from django.db.models import Max, Min, Sum, Count, Avg
res = models.Book.objects.aggregate(Max('price'), Count('pk'), 最小价格=Min('price'), allPrice=Sum('price'),平均价格=Avg('price'))
print(res)
注意:我们在进行聚合查询的时候,可以给聚合查询的内容命名,如果不主动命名,也会自动用下划线拼接两个字段名,但是这里的命名不建议用中文(虽然能用)
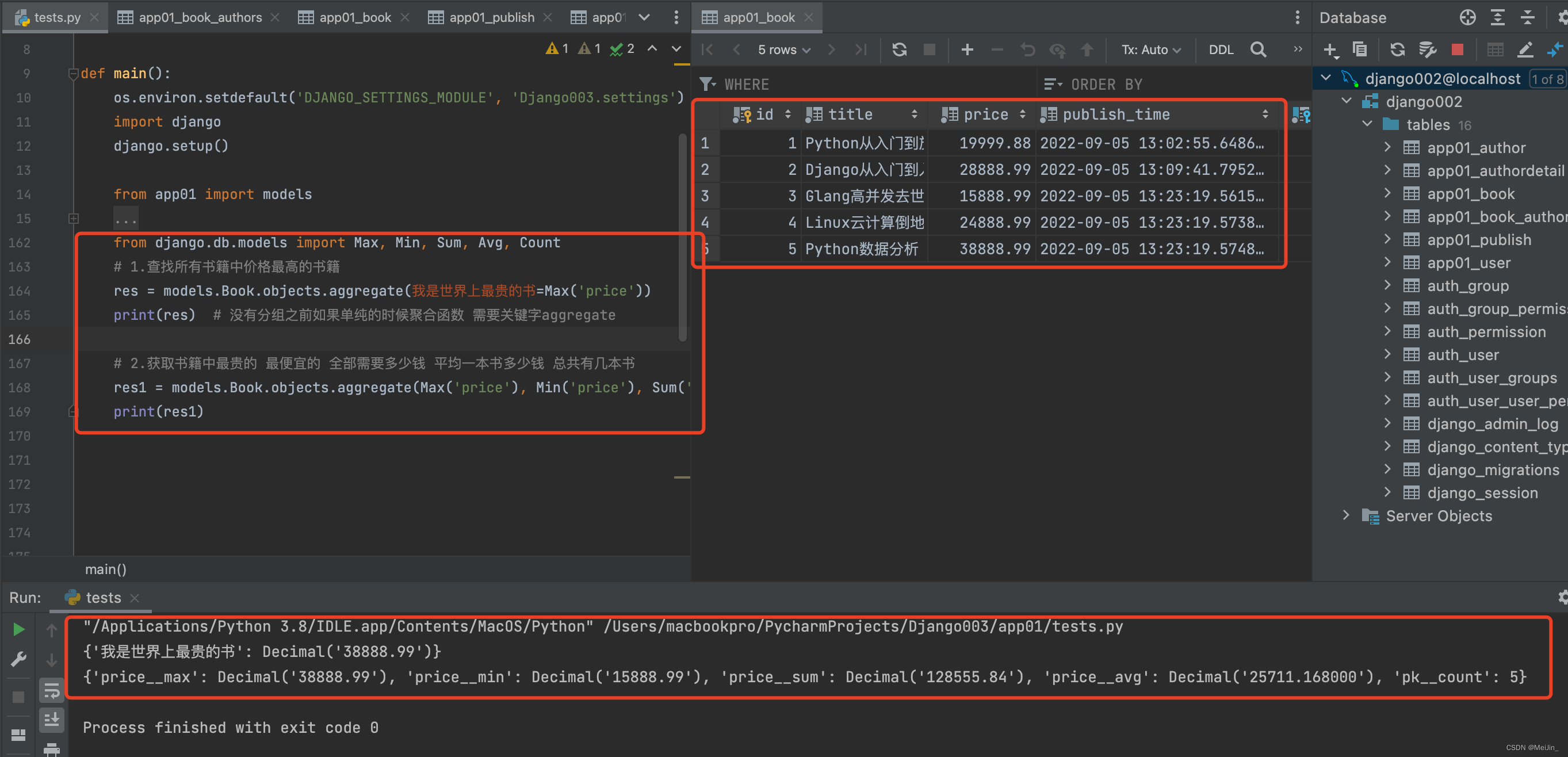
示例2
from django.db.models import Max, Min, Sum, Avg, Count
1.查找所有书籍中价格最高的书籍
res = models.Book.objects.aggregate(我是世界上最贵的书=Max('price'))
print(res) # 没有分组之前如果单纯的时候聚合函数 需要关键字aggregate
2.获取书籍中最贵的 最便宜的 全部需要多少钱 平均一本书多少钱 总共有几本书
res1 = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Avg('price'), Count('pk'))
print(res1)
'''通过 别名 = 聚合函数的方法可以取一个别名'''
分组查询
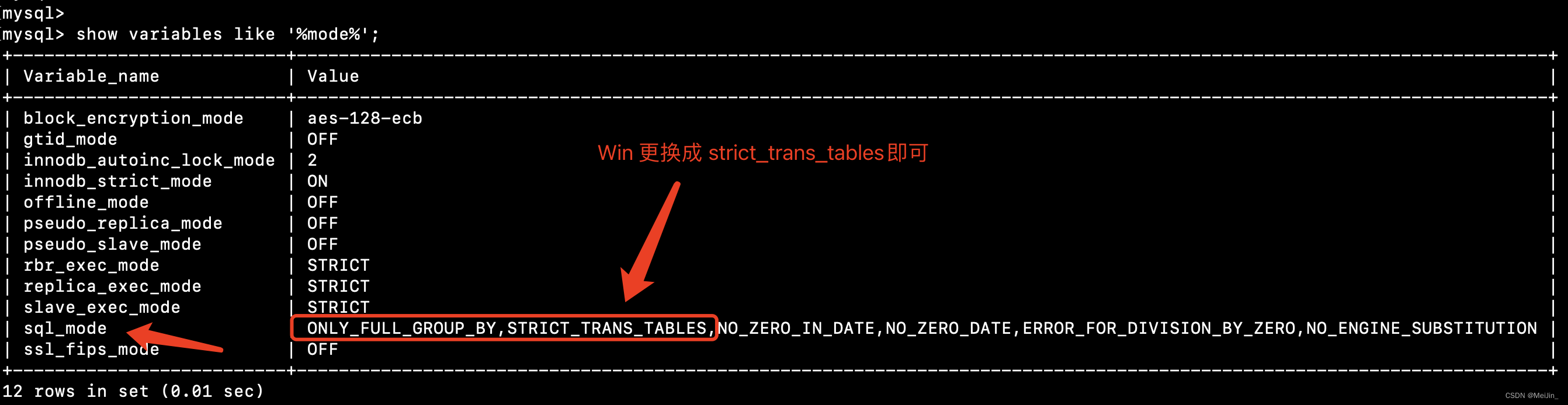
提醒:如果执行orm分组查询报错,并且有关键字sql_mode,需要去mysql配置文件中修改严格模式的配置信息。(Mac不会有)
strict mode
移除sql_mode中的only_full_group_by
# 分组查询
from django.db.models import Max, Min, Sum, Count, Avg
# 统计每一本书的作者个数
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('title', 'author_num')
print(res)
# 统计出每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
print(res)
# 统计不止一个作者的图书
# 1.先统计每本书的作者个数
res = models.Book.objects.annotate(author_num=Count('authors__pk'))
print(res)
# 2.筛选出作者个数大于1的数据
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('title',
'author_num')
print(res)
# 查询每个作者出的书的总价格
"""
models.表名.objects.annotate() 按照表分组
models.表名.objects.values('字段名').annotate() 按照values括号内指定的字段分组
"""
res = models.Author.objects.annotate(总价=Sum('book__price'),count_book=Count('book__pk')).values('name','总价','count_book')
print(res)
res = models.Book.objects.values('publish_id').annotate(count_pk=Count('pk')).values('publish_id', 'count_pk')
print(res)
ORM中如何给表再次添加新的字段
当我们在对数据库使用ORM进行操作的时候,如果出现需要新增字段的情况,在模型层中修改了代码后,进行数据库迁移操作前,需要对新增的字段值进行设置,否则不让进行数据库迁移
我们可以把字段值设置成一个固定的值,也可以设置字段值可以为空
首先我们先给我们的书籍表格再添加两条数据(库存以及已销售)
storage_num = models.IntegerField(verbose_name='库存数')
sale_num = models.IntegerField(verbose_name='已销售')
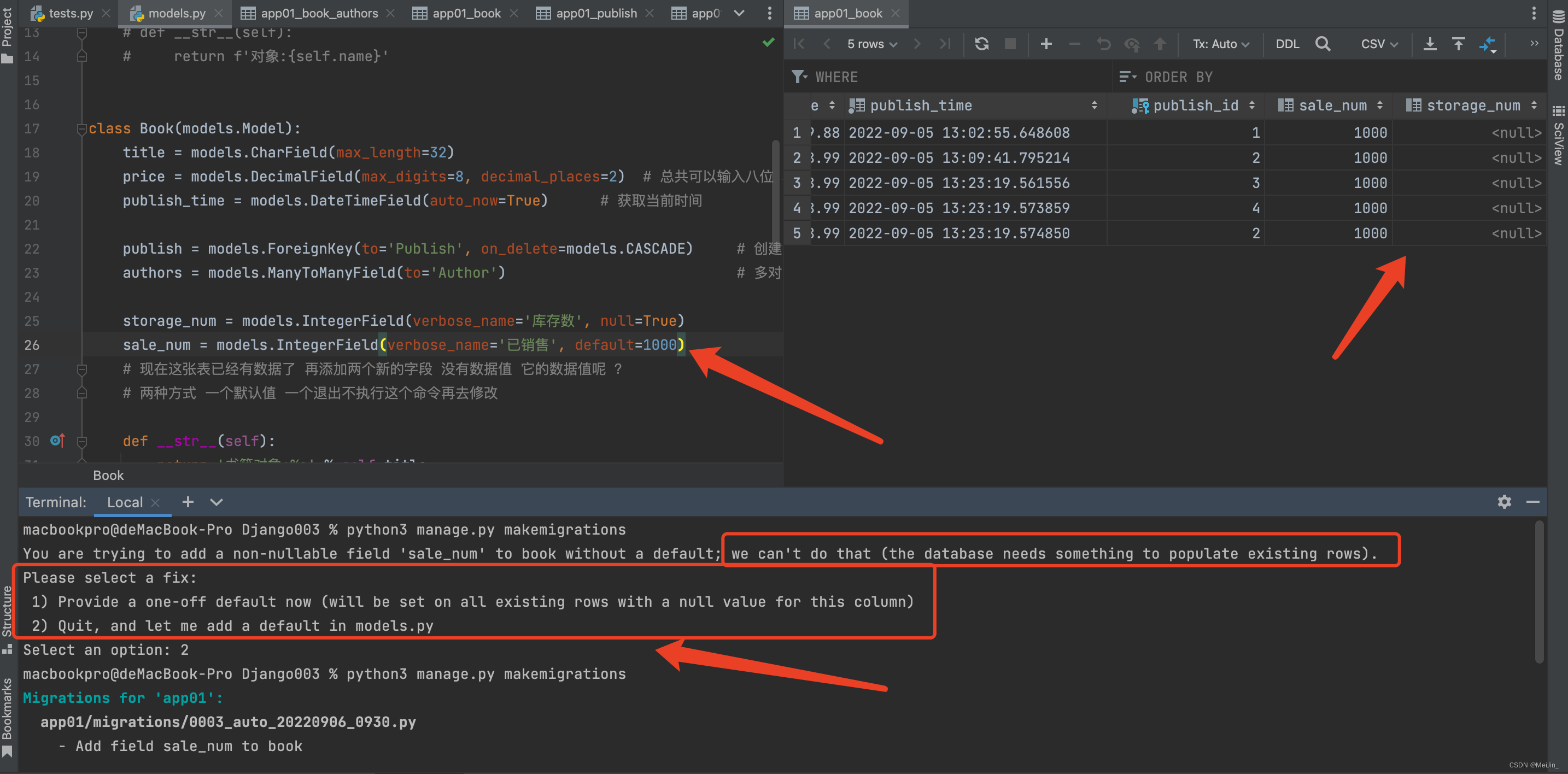
但是出现报错了
we can't do that (the database needs something to populate existing rows)
现在这张表已经有数据了 再添加两个新的字段 没有数据值 它的数据值呢 ?
两种方式 一个默认值 一个退出不执行这个命令再去修改(所以我们得给他加上数据)
storage_num = models.IntegerField(verbose_name='库存数', null=True)
sale_num = models.IntegerField(verbose_name='已销售', default=1000)
如果不对新的字段值进行设置会出现一下提示:
F与Q查询
F查询
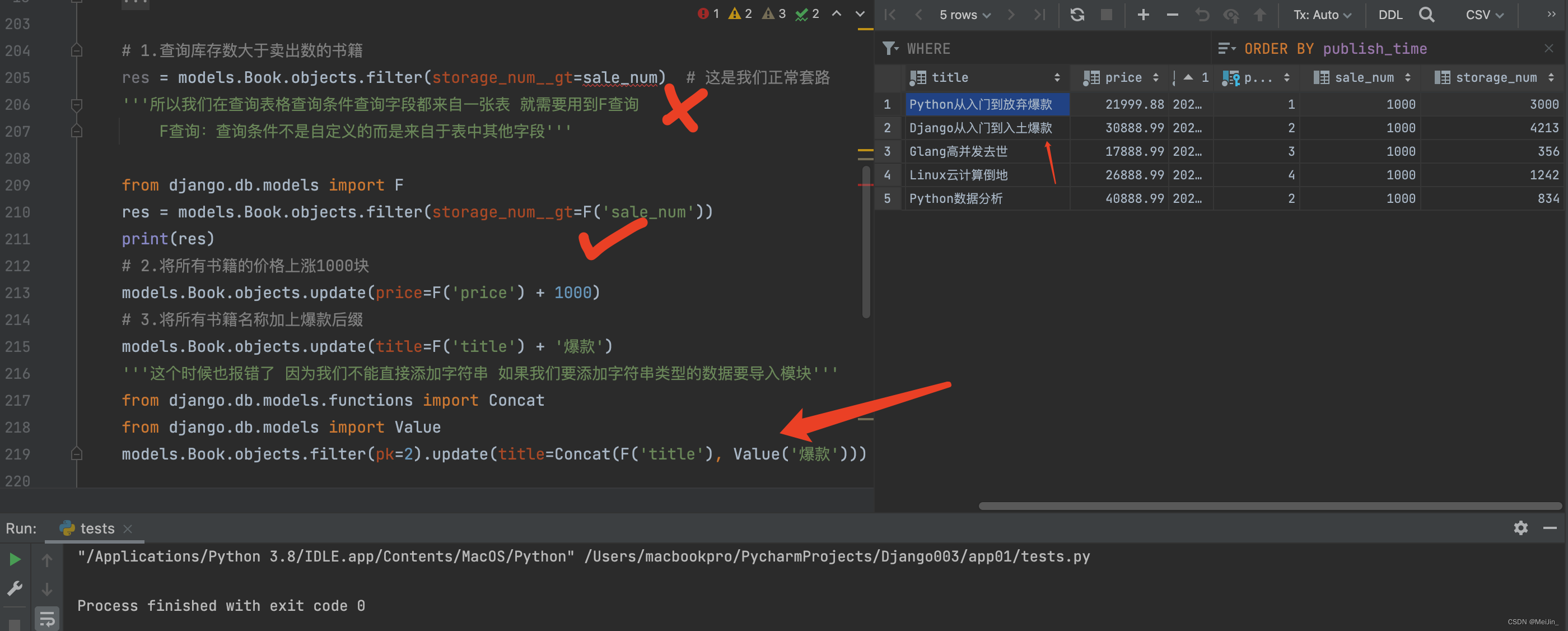
# 1.查询库存数大于卖出数的书籍
'''当查询条件不是明确的 也需要从数据库中获取 就需要使用F查询'''
from django.db.models import F
res = models.Book.objects.filter(kucun__gt=F('maichu'))
print(res)
# 2.将所有书的价格涨800
models.Book.objects.update(price=F('price') + 800)
# 3.将所有书的名称后面追加爆款
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.update(title=Concat(F('title'), Value('新款')))
在用ORM进行查询的时候,我们会发现当查询条件不明确的时候不能执行语句,因此需要用到F查询
Q查询
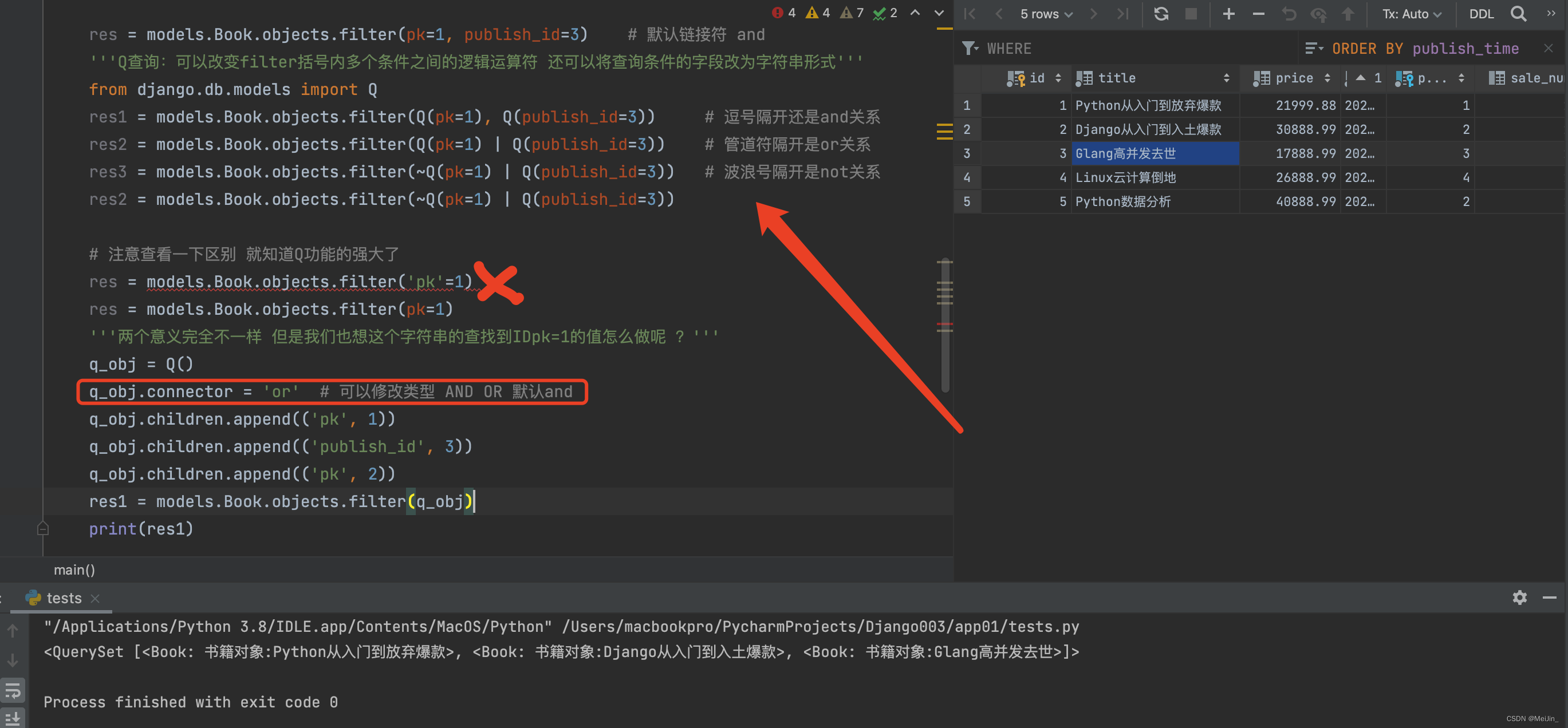
# 查询主键是1或者价格大于2000的书籍
res = models.Book.objects.filter(pk=1, price__gt=2000) # 逗号默认是and关系
from django.db.models import Q
res = models.Book.objects.filter(Q(pk=1), Q(price__gt=2000)) # 逗号是and
res = models.Book.objects.filter(Q(pk=1) | Q(price__gt=2000)) # |是or
res = models.Book.objects.filter(~Q(pk=1) | Q(price__gt=2000)) # ~是not
print(res.query)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY