并发编程(完结)
多进程实现TCP服务端并发
服务端
from multiprocessing import Process
import socket
"""
服务端的三个条件:
1、有固定的IP和PORT。
2、24小时不间断提供服务。
3、能够支持并发。
"""
def get_server():
server = socket.socket() # 括号内不加参数默认就是TCP协议
server.bind(('127.0.0.1', 8081))
# 半连接池
server.listen(5)
return server
def get_talk(sock):
# 通讯循环
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
if __name__ == '__main__':
server = get_server()
# 链接循环
while True:
sock, addr = server.accept() # 接客
# 开设多进程去聊天
p = Process(target=get_talk, args=(sock,)) # 叫其他人来服务客户(线程版)
p.start()
客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8081))
while True:
client.send(b'hello baby')
data = client.recv(1024)
print(data)
互斥锁代码实操
互斥锁的概念
-
对共享数据进行锁定,保证同一时刻只能有一个线程去操作
互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到锁的线程需要等待,等互斥锁使用完释放后,其它等待的线程再去抢这个锁
互斥锁的使用
-
threading模块中定义了Lock变量,这个变量本质上是一个函数,通过调用这个函数可以获取一把互斥锁
建议:只加载操作数据的部分 否则整个程序的效率会极低
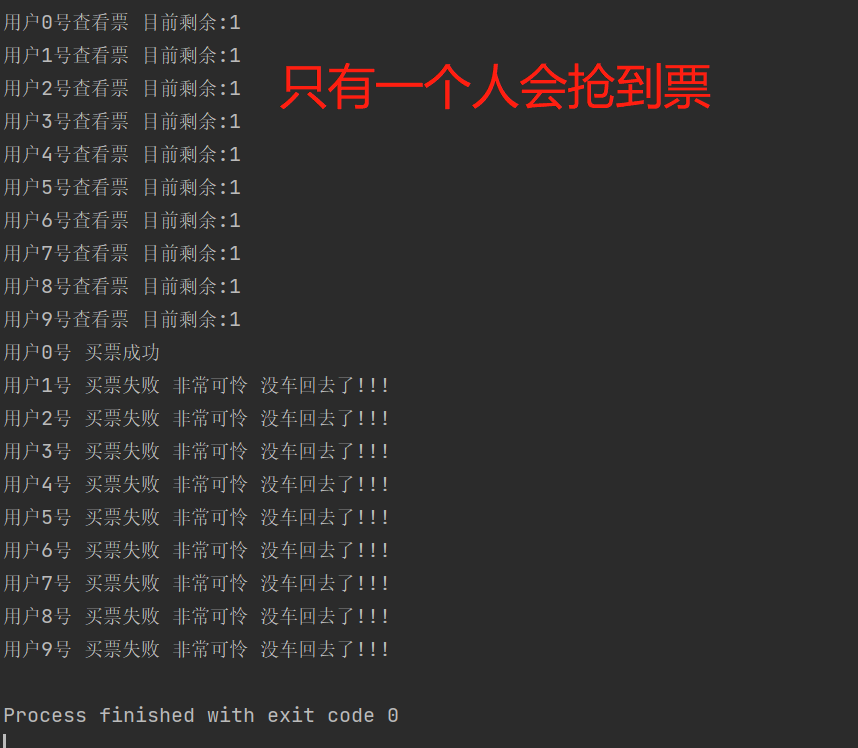
抢票任务代码
锁:建议只加载操作数据的部分 否则整个程序的效率会极低
from multiprocessing import Process, Lock
import time
import json
import random
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
res = data.get('ticket_num')
print(f'{name}查看票 目前剩余:{res}')))
def buy(name):
# 先查询票数
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1, 3))
# 买票
if data.get('ticket_num') > 0:
with open(r'data.json', 'w', encoding='utf8') as f:
data['ticket_num'] -= 1
json.dump(data, f)
print(f'{name} 买票成功')
else:
print(f'{name} 买票失败 非常可怜 没车回去了!!!')
def run(name, mutex):
search(name)
mutex.acquire() # 抢锁
buy(name)
mutex.release() # 释放锁
if __name__ == '__main__':
mutex = Lock() # 产生一把锁
for i in range(10):
p = Process(target=run, args=(f'用户{i}号', mutex))
p.start()
"""
锁有很多种 但是作用都一样
行锁 表锁 ...
"""
创建一个data.json文件
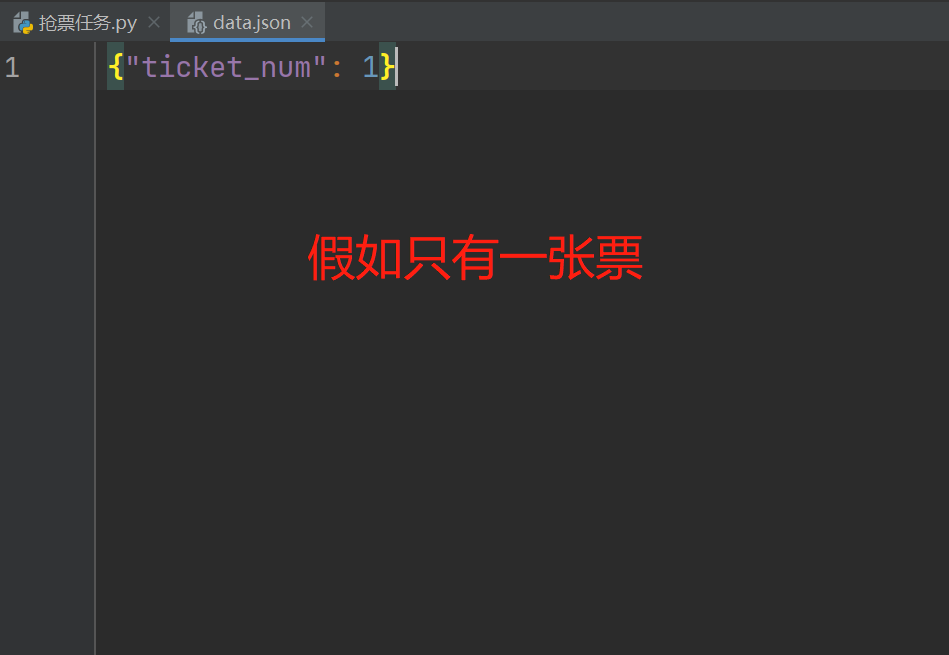
锁死现象
- 这里讲的就是前一个线程拿了a的锁然后想去拿b的锁,同时后一个 进程拿了b的锁,想去拿a的锁,双方都拿不到,代码就卡在那里不会动了,这个现象叫做死锁现象
acquire()
release()
from threading import Thread,Lock
import time
mutexA = Lock() # 产生一把锁
mutexB = Lock() # 产生一把锁
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexB.acquire()
print(f'{self.name}抢到了B锁')
mutexB.release()
print(f'{self.name}释放了B锁')
mutexA.release()
print(f'{self.name}释放了A锁')
def func2(self):
mutexB.acquire()
print(f'{self.name}抢到了B锁')
time.sleep(1)
mutexA.acquire()
print(f'{self.name}抢到了A锁')
mutexA.release()
print(f'{self.name}释放了A锁')
mutexB.release()
print(f'{self.name}释放了B锁')
for i in range(10):
obj = MyThread()
obj.start()
总结
- 互斥锁的作用就是将并发变成串行,牺牲了效率,但是保证了数据的安全
- 使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾完整地去执行
- 互斥锁如果没有使用好容易出现死锁的情况
线程理论
进程是资源单位
进程相当于工厂的车间 进程负责给内部的线程提供相应的资源
线程是执行单位
线程相当于车间里面的流水线 线程负责执行真正的功能
多个线程就多个流水线都是在进程的资源空间内
线程的特征:
1.一个进程至少有一个线程(没有进程哪来的线程 程序(客户端)没有运行什么都没有)
2.多进程于线程的区别
多进程 需要申请内存空间 需要拷贝全部代码 资源消耗大 数据间不能共享
多线程 不需要申请内存空间 也不需要拷贝全部代码 资源消耗小 数据间可以共享
3.一个进程内可以开设多个线程
为什么要使用多线程
- 线程在重新中是独立的、并发的执行流与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存、文件句柄和其他进程应有的状态
- 因为线程的划分尺度小于进程,使得多线程程序的并发性高。进程在执行过程之中拥有独立的内存单元,而多个线程共享内存,从而极大的提升了程序的运行效率
- 线程比进程具有更高的性能,这是由于同一个进程中的线程都有共性,多个线程共享一个进程的虚拟空间。线程的共享环境包括进程代码段、进程的共有数据等,利用这些共享的数据,线程之间很容易实现通信
- 操作系统在创建进程时,必须为改进程分配独立的内存空间,并分配大量的相关资源,但创建线程则简单得多。因此,使用多线程来实现并发比使用多进程的性能高得要多
创建线程的两种方式
方式1:
-
跟进程一样,也是函数和面向对象两种方式
-
创建线程需要用到Threading.Thread类,他和Process模块使用的方法很像
from threading import Thread
from multiprocessing import Process
import time
def task(name):
print(f'{name} is running')
time.sleep(0.1)
print(f'{name} is over')
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(100):
p = Process(target=task, args=('用户%s'%i,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print(time.time() - start_time)
t_list = []
for i in range(100):
t = Thread(target=task, args=('用户%s'%i,))
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(time.time() - start_time)
t = Thread(target=task, args=('jason',))
t.start()
print('主线程')
"""
创建线程无需考虑反复执行的问题
"""
方式2:
-
继承Thread类,在子类中重写run()和init()类
-
通过继承Thread类创建线程,以下程序自定义线程类MyThreading,继承自threading.Thread,并重写了__init__()方法和run()方法。其中run()方法相当于方法一中的任务函数,运行结果与方法一中的结果一致
import time
import threading
class MyThread(threading.Thread):
def __init__(self,counter):
super().__init__()
self.counter=counter
def run(self):
print(f'线程名称:{threading.current_thread().name} 参数: {self.counter} 开始时间:{time.strftime("%Y-%m-%d %H:%M%S")}')
counter=self.counter
while counter:
time.sleep(3)
counter-=1
print(f'线程名称:{threading.current_thread().name} 参数: {self.counter} 开始时间:{time.strftime("%Y-%m-%d %H:%M%S")}')
if __name__=="__main__":
print(f'主线程开始的时间是:{time.strftime("%Y-%m-%d %H:%M:%S")}')
#初始化三个线程,传递不同的参数
t1=MyThread(3)
t2=MyThread(2)
t3=MyThread(1)
#start()方法开启三个线程
t1.start()
t2.start()
t3.start()
#等待运行结束,join()方法阻塞主线程,等待当前线程运行结束
t1.join()
t2.join()
t3.join()
print(f'主线程结束时间:{time.strftime("%Y-%m-%d %H:%M:%S")}')
线程的诸多特性
- join方法(让线程从异步变成同步)
from threading import Thread
import time
def task(name):
print(f'{name} is running')
time.sleep(1)
print(f'{name} is over')
t = Thread(target=task, args=('jason', ))
t.start()
t.join()
print('主线程')
-
同进程内多个线程数据共享(可以看成一个py文件内的变量是通用的)
-
current_thread().name查看线程的名称
-
active_count()查看主线程的名称
GIL全局解释器锁
全局解释器锁GIL
- GIL:又称全局解释器锁。作用就是限制多线程同时执行,保证同一时间内只有一个线程在执行。线程非独立的,所以同一进程里线程是数据共享,当各个线程访问数据资源时会出现“竞争”状态,即数据可能会同时被多个线程占用,造成数据混乱,这就是线程的不安全。所以引进了互斥锁,确保某段关键代码、共享数据只能由一个线程从头到尾完整地执行。
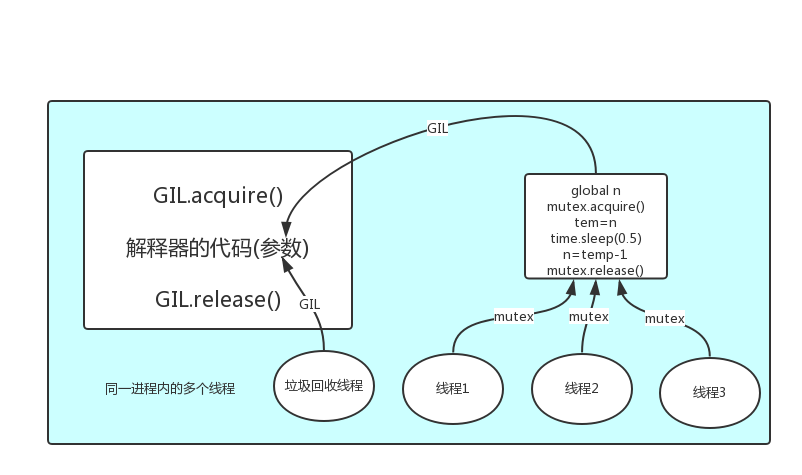
为什么会有GIL
-
Python为了利用多核CPU,开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁,于是有了GIL这把超级大锁。因为有了GIL,所以我们的Python可以实现多进程,但是这是一个假的多进程,虽然它会利用多个CPU共同协作,但实则是利用一个CPU的资源。
-
但是这种GIL导致我们的多进程并不是真正的多进程,所以它的效率很低。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。如果推到重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。所以简单的说:GIL的存在更多的是历史原因。
GIL的总结
- 因为GIL的存在,只有IO Bound场景下的多线程会得到较好的性能。
如果对并行计算性能较高的程序可以考虑把核心部分也成C模块,或者索性用其他语言实现。
GIL在较长一段时间内将会继续存在,但是会不断对其进行改进
官方文档对GIL的解释:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.
"""
1.在CPython解释器中存在全局解释器锁简称GIL
python解释器有很多类型
CPython JPython PyPython (常用的是CPython解释器)
2.GIL本质也是一把互斥锁 用来阻止同一个进程内多个线程同时执行(重要)
3.GIL的存在是因为CPython解释器中内存管理不是线程安全的(垃圾回收机制)
垃圾回收机制
引用计数、标记清除、分代回收
"""
- 当我们在运行python解释器的时候,之所以不能弄成多线程,是因为处于多线程状态下的时候,垃圾回收机制会误删数据值,在数据值还没有和变量名绑定的时候,就会提前把数据值删除,造成异常,因此python中使用的是GIL 来控制线程的运行先后顺序
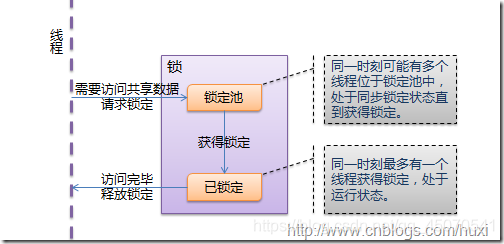
验证GIL的存在
- 根据GIL的作用我们得知,线程都是串行运行的,因此这里我们调用time模块让每个线程运行时睡0.1秒,来验证代码运行一百次是否需要10秒以上
from threading import Thread
num = 100
def task():
global num
num -= 1
t_list = []
for i in range(100):
t = Thread(target=task)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(num)
GIL与普通互斥锁
- 既然CPython解释器中有GIL 那么我们以后写代码是不是就不需要操作锁了!!!
- 回答:GIL只能够确保同进程内多线程数据不会被垃圾回收机制弄乱。并不能确保程序里面的数据是否安全
import time
from threading import Thread,Lock
num = 100
def task(mutex):
global num
mutex.acquire()
count = num
time.sleep(0.1)
num = count - 1
mutex.release()
mutex = Lock()
t_list = []
for i in range(100):
t = Thread(target=task,args=(mutex,))
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(num)
python多线程是否有用
需要看情况
单个CPU
IO密集型
多进程:申请额外的空间 消耗更多的资源
多线程:消耗资源相对较少 通过多道技术
ps:多线程有优势!!!
计算密集型
多进程:申请额外的空间 消耗更多的资源(总耗时+申请空间+拷贝代码+切换)
多线程:消耗资源相对较少 通过多道技术(总耗时+切换)
ps:多线程有优势!!!
多个CPU
IO密集型
多进程:总耗时(单个进程的耗时+IO+申请空间+拷贝代码)
多线程:总耗时(单个进程的耗时+IO)
ps:多线程有优势!!!
计算密集型
多进程:总耗时(单个进程的耗时)
多线程:总耗时(多个进程的综合)
ps:多进程完胜!!!
计算密集型(代码)
from threading import Thread
from multiprocessing import Process
import os
import time
def work():
# 计算密集型
res = 1
for i in range(1, 100000):
res *= i
if __name__ == '__main__':
# print(os.cpu_count()) # 12 查看当前计算机CPU个数
start_time = time.time()
# p_list = []
# for i in range(12): # 一次性创建12个进程
# p = Process(target=work)
# p.start()
# p_list.append(p)
# for p in p_list: # 确保所有的进程全部运行完毕
# p.join()
t_list = []
for i in range(12):
t = Thread(target=work)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('总耗时:%s' % (time.time() - start_time)) # 获取总的耗时
-
多进程:5.665567398071289
-
多线程:30.233906745910645
IO密集型(代码)
def work():
time.sleep(2) # 模拟纯IO操作
if __name__ == '__main__':
start_time = time.time()
# t_list = []
# for i in range(100):
# t = Thread(target=work)
# t.start()
# for t in t_list:
# t.join()
p_list = []
for i in range(100):
p = Process(target=work)
p.start()
for p in p_list:
p.join()
print('总耗时:%s' % (time.time() - start_time))
-
多线程:0.0149583816528320
-
多进程:0.6402878761291504
什么是计算密集型和IO密集型:
- CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。简单说就是CPU的执行时间占程序运行的大部分时间,小部分时间进行磁盘读写.
信号量
- 在python并发编程中信号量相当于多把互斥锁(设置多少信号量,同一时间最多可以运行多少把互斥锁)
概念
- 信号量(英语:semaphore)又称为信号标,是一个同步对象,用于保持在0至指定最大值之间的一个计数值。
- 当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;
- 当线程完成一次对semaphore对象的释放(release)时,计数值加一。
- 当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态
- semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态.
代码操作
from threading import Thread, Lock, Semaphore
import time
import random
sp = Semaphore(5) # 一次性产生五把锁
class MyThread(Thread):
def run(self):
sp.acquire()
print(self.name)
time.sleep(random.randint(1, 3))
sp.release()
for i in range(20):
t = MyThread()
t.start()
event事件
- 在初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
event的几种方法
1.event.isSet(): 返回event的状态值
2.event.wait(): 如果event.isSet()==False将阻塞线程
3.event.set(): 设置ecent的状态值为True,所有阻塞池的线程激活进入就绪态,等待操作系统调度
4.event.clear(): 恢复event的状态值为False
代码操作
from threading import Thread, Event
import time
event = Event() # 类似于造了一个红绿灯
def light():
print('红灯亮着的 所有人都不能动')
time.sleep(3)
print('绿灯亮了 油门踩到底 给我冲!!!')
event.set()
def car(name):
print('%s正在等红灯' % name)
event.wait()
print('%s加油门 飙车了' % name)
t = Thread(target=light)
t.start()
for i in range(20):
t = Thread(target=car, args=('熊猫PRO%s' % i,))
t.start()
进程池与线程池
概念介绍
-
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
-
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果
进程和线程是否能无限制创建?
答:不可以
- 因为硬件的发展赶不上软件,有物理极限。如果我们在编写代码的过程中无限制的创建进程或者线程可能会导致计算机崩溃
作用
-
池:降低程序的执行效率 但是保证了计算机硬件的安全
-
进程池:提前创建好固定数量的进程供后续程序的调用 超出则等待
-
线程池:提前创建好固定数量的线程供后续程序的调用 超出则等待
进程池
1、引入原因:
-
① 动态创建进程(或线程)比较耗费时间,这将导致较慢的客户响应
-
② 动态创建的子进程通常只用来为一个客户服务,这样导致了系统上产生大量的细微进程(或线程)。进程和线程间的切换将消耗大量CPU时间
-
③ 动态创建的子进程是当前进程的完整映像,当前进程必须谨慎的管理其分配的文件描述符和堆内存等系统资源,否则子进程可能复制这些资源,从而使系统的可用资源急剧下降,进而影响服务器的性能。
-
④池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务
2、子进程选择方法有二:
-
① 主进程使用某种算法来主动选择子进程。最简单、最常用的算法是随机算法和 Round Robin (轮流算法)
-
② 主进程和所有子进程通过一个共享的工作队列来同步,子进程都睡眠在该工作队列上。当有新的任务到来时,主进程将任务添加到工作队列中。这将唤醒正在等待任务的子进程,不过只有一个子进程将获得新任务的“接管权”,它可以从工作队列中取出任务并执行之,而其他子进程将继续睡眠在工作队列上
线程池
为什么创建线程池
- 创建线程要花费昂贵的资源和时间,如果任务来了才创建线程那么响应时间会变长,而且一个进程能创建的线程数有限。为了避免这些问题,在初始化一个多线程应用程序过程中创建一个线程集合,然后在需要执行新的任务时重用这些线程而不是新建一个线程,它们被称为线程池,里面的线程叫工作线程
提交任务的两种方式:
同步:提交了一个任务,必须等任务执行完了(拿到返回值),才能执行下一行代码
异步:提交了一个任务,不要等执行完了,可以直接执行下一行代码
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import time
#ThreadPoolExecutor:线程池,提供异步调用
#ProcessPoolExecutor: 进程池,提供异步调用
def task(i):
print(f'{currentThread().name} 在执行任务 {i}')
# print(f'进程 {current_process().name} 在执行任务 {i}')
time.sleep(1)
return i**2
if __name__ == '__main__':
pool = ThreadPoolExecutor(4) # 池子里只有4个线程
# pool = ProcessPoolExecutor(4) # 池子里只有4个线程
fu_list = []
for i in range(20):
# pool.submit(task,i) # task任务要做20次,4个线程负责做这个事
future = pool.submit(task,i) # task任务要做20次,4个进程负责做这个事
# print(future.result()) # 如果没有结果一直等待拿到结果,导致了所有的任务都在串行
fu_list.append(future)
pool.shutdown() # 关闭了池的入口,会等待所有的任务执行完,结束阻塞.
for fu in fu_list:
print(fu.result())
#回调函数
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import time
def task(i):
print(f'{currentThread().name} 在执行任务 {i}')
# print(f'进程 {current_process().name} 在执行任务 {i}')
time.sleep(1)
return i**2
def parse(future):
# 处理拿到的结果
print(future.result())
if __name__ == '__main__':
pool = ThreadPoolExecutor(4) # 池子里只有4个线程
# pool = ProcessPoolExecutor(4) # 池子里只有4个线程
fu_list = []
for i in range(20):
# pool.submit(task,i) # task任务要做20次,4个线程负责做这个事
future = pool.submit(task,i) # task任务要做20次,4个进程负责做这个事
future.add_done_callback(parse)
# 为当前任务绑定了一个函数,在当前任务执行结束的时候会触发这个函数,
# 会把future对象作为参数传给函数
# 这个称之为回调函数,处理完了回来就调用这个函数.
# print(future.result()) # 如果没有结果一直等待拿到结果,导致了所有的任务都在串行
# pool.shutdown() # 关闭了池的入口,会等待所有的任务执行完,结束阻塞.
# for fu in fu_list:
# print(fu.result())
协程
-
进程:资源单位
-
线程:执行单位
-
协程:单线程下实现并发(效率极高)
在代码层面欺骗CPU 让CPU觉得我们的代码里面没有IO操作
实际上IO操作被我们自己写的代码检测 一旦有 立刻让代码执行别的
(该技术完全是程序员自己弄出来的 名字也是程序员自己起的)
核心:自己写代码完成切换+保存状态
import time
from gevent import monkey;
monkey.patch_all() # 固定编写 用于检测所有的IO操作(猴子补丁)
from gevent import spawn
def func1():
print('func1 running')
time.sleep(3)
print('func1 over')
def func2():
print('func2 running')
time.sleep(5)
print('func2 over')
if __name__ == '__main__':
start_time = time.time()
# func1()
# func2()
s1 = spawn(func1) # 检测代码 一旦有IO自动切换(执行没有io的操作 变向的等待io结束)
s2 = spawn(func2)
s1.join()
s2.join()
print(time.time() - start_time) # 8.01237154006958 协程 5.015487432479858
协程实现并发
import socket
from gevent import monkey;monkey.patch_all() # 固定编写 用于检测所有的IO操作(猴子补丁)
from gevent import spawn
def communication(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
def get_server():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept() # IO操作
spawn(communication, sock)
s1 = spawn(get_server)
s1.join()
如何不断的提升程序的运行效率
多进程下开多线程 多线程下开协程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)