正则表达式前戏
正则表达式是用来匹配与查找字符串的,从网上爬取数据自然或多或少会用到正则表达式,python的正则表达式要先引入re模块,正则表达式以r引导
案例:手机号校验
基本要求:手机号必须是11位、手机号必须是 13 15 17 18 19开头、必须是纯数字
'''纯python代码实现'''
while True:
phone_num = input('请输入您的手机号>>>:').strip()
if len(phone_num) == 11:
if phone_num.isdigit():
if phone_num.startswith('13') or
phone_num.startswith('15') or
phone_num.startswith('17') or
phone_num.startswith('18') or
phone_num.startswith('19'):
print('手机号输入正确')
else:
print('手机号开头不对')
else:
print('手机号必须是纯数字')
else:
print('手机号必须是11位')
'''python结合正则表达式实现'''
import re
phone_number = input('请输入您手机号')
if re.match('^(13|14|15|18|19)[0-9]{9}$', phone_number):
print('手机号正确')
else:
print('输入错误')
正则表达式是一门独立的技术 所有编程语言都可以使用
它的作用可以简单的概括为:利用一些特殊符号(也可以直接写想要查找的具体字符)的组合产生一些特殊的含义然后去字符中筛选出符合条件的数据
>>>:筛选数据(匹配数据)
字符组
'''字符组默认匹配方式是挨个挨个匹配'''
[0123456789] 匹配0到9意义一个数(全写)
[0-9] 匹配0到9任意一个数(缩写)
[a-z] 匹配26个小写英文字母
[A-Z] 匹配26个大写英文字母
[0-9a-zA-Z] 匹配数字或者小写字母或者大写字母
ps:字符组内所有的数据默认都是或的关系
特殊符号
'''特殊符号默认匹配方式是挨个挨个匹配'''
. 匹配除换行符以外的任意字符
\w 匹配数字、字母、下划线
\W 匹配非数字、非字母、非下划线
\d 匹配数字
^ 匹配字符串的开头
$ 匹配字符串的结尾
两者组合使用可以非常精确的限制匹配的内容
a|b 匹配a或者b(管道符的意思是或)
() 给正则表达式分组 不影响表达式的匹配功能
[] 字符组 内部填写的内容默认都是或的关系
[^] 取反操作 匹配除了字符组里面的其他所有字符
注意上尖号在中括号内和中括号意思完全不同
量词
'''正则表达式默认情况下都是贪婪匹配>>>:尽可能多的匹'''
* 匹配零次或多次 默认是多次(无穷次)
+ 匹配一次或多次 默认是多次(无穷次)
? 匹配零次或一次 作为量词意义不大主要用于非贪婪匹配
{n} 重复n次
{n,} 重复n次或更多次 默认是多次(无穷次)
{n,m} 重复n到m次 默认是m次
ps:量词必须结合表达式一起使用 不能单独出现 并且只影响左边第一个表达式
jason\d{3} 只影响\d
贪婪匹配与非贪婪匹配
'''所有的量词都是贪婪匹配如果想要变为非贪婪匹配只需要在量词后面加问号'''
待匹配的文本
<script>alert(123)</script>
带使用的正则(贪婪匹配)
<.*>
请问匹配的内容
<script>alert(123)</script>一条
待使用的正则(非贪婪匹配)
<.*?>
转义符
'''斜杠与字母的组合有时候有特殊含义'''
\n 匹配的是换行符
\\n 匹配的是文本\n
\\\\n 匹配的是文本\\n
ps:如果是在python中使用 还可以在字符串前面加r取消转义
正则表达式实战建议
1.编写校验用户身份证号的正则
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{14}(\d{2}[0-9x])?$
^([1-9]\d{16}[0-9x]|[1- 9]\d{14})$
2.编写校验邮箱的正则
/^[a-zA-Z0-9_.-]+@[a-zA-Z0- 9-]+(\\.[a-zA-Z0-9-]+)*\.[a- zA-Z0-9]{2,6}$/
3.编写校验用户手机号的正则(座机、移动)
^1[3|4|5|7|8][0-9]{9}$
4.编写校验用户qq号的正则
[1-9]([0-9]{5,11})
re模块
在python中如果想要使用正则 可以考虑re模块
findall方法

finditer方法
search方法
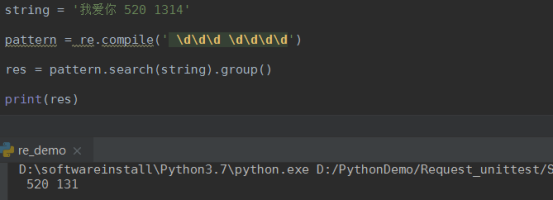
group方法
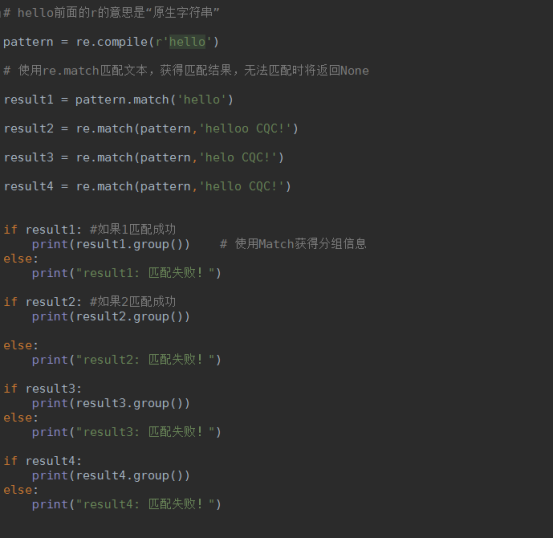
match方法
compile方法

split方法

sub方法
re模块补充说明
1.分组优先
2.分组别名
2.分组别名
res = re.search('www.(?P<content>baidu|oldboy)(?P<hei>.com)', 'www.oldboy.com')
print(res.group())
print(res.group('content'))
print(res.group(0))
print(res.group(1))
print(res.group(2))
print(res.group('hei'))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本