

[转] 大数据实时数据分析引擎介绍---Dremel、Tenzing和Imapla
对于数据分析师来说,SQL是主要的语言。 Hive为Hadoop提供了支持SQL运行的能力,可是目前Hive运行速度达不到实时要求。这是因为Hive将SQL翻译成一个或多个MapReduce任务,而MapReduce原本是大数据批处理计算框架,并不适应实时数据分析的速度要求。
现在有两种思路去提高SQL在大数据平台上的执行速度:
1. 用一种更快的SQL执行引擎取代MapReduce。
2. 优化MapReduce,使其更适合OLAP查询。
谷歌在这两种思路上都做出了先驱性工作。2010年,谷歌发表了Dremel论文。Dremel是取代MapReduce的SQL执行引擎,其速度要快于MapReduce100倍,基本上可以保证大多数SQL执行在一秒内完成。 2011年,谷歌发表了Tenzing论文, Tenzing是一种经过优化的MapReduce系统,大多数SQL查询能在5--10秒钟之内完成。
本文将首先讨论Dremel和Tenzing的技术特点,然后展示Youtube的BI构架,最后将讨论最新开源SQL执行引擎Impala。
Dremel—一个更快的SQL执行引擎
据谷歌的技术人员自己宣称,Dremel的SQL执行速度不仅比MapReduce快,也要比MySQL块。例如一个大的Fact table, 有130 million行数据,在上面做Avg()计算,MySQL需要2分钟,而用类似价位硬件的Dremel只需要几秒钟。
Dremel之所以快,主要有两点原因
1. Dremel的服务器节点按照一个递归树形状组织在一起。图1显示了Dremel服务器节点组织构架。
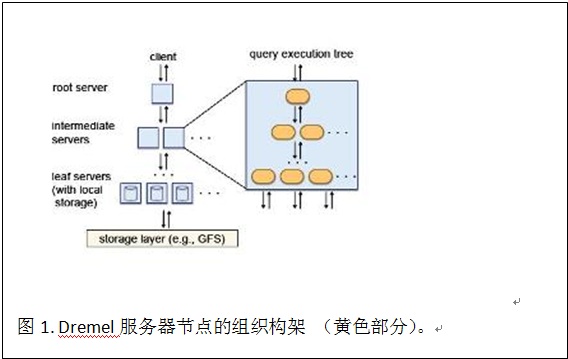
设想我们在Dremel上执行一个简单的SQL查询:
Select A, Sum(B) From T GroupBy A;
其中A和B是Table T 中的两个列。当Root Server(图1 最上层节点)从Client收到这样的查询时,它首先会确定在树的第一层节点中有哪些节点负责管理Table T的数据块(Tablets),然后对于这些第一层节点重写查询为:
Select A, Sum(C)From Union (R[1,i], …,R[1,N]) Group By A; --Query 1
和
R[1,i] = Select A, Sum(B) as C From T[1, i] Group By A; --Query2
其中i从1到N,N是第一层节点的数量。R[1,i] 是第一层节点中第i个节点的中间结果集,T[1,i]是第i个节点上的TableT的数据块。Root Server 首先向第一层节点发出Query 2,然后收集中间结果集,在本地执行Query 1.
这样的查询重写会在各层节点上递归继续下去,直到达到叶子节点为止。
这样的服务器的构架有一个重要的局限,就是中间结果集和最后结果集要足够的小,(起码要小于一个节点的内存容量,)如果结果集过大,Dremel将不得不让整个的查询失败。和Dremel相比,MapReduce是一个更加Scalable的技术平台,因为它对结果集的大小没有限制,所以MapReduce能处理更大规模的数据。但在实际的使用中,数据分析(OLAP)的结果集绝大多数时候要远小于源数据集,所以Dremel的这个局限对于实际OLAP查询并不构成重大问题。
1. 第二个使Dremel加速的原因是Dremel使用列式存储格式(columnar storage)。谷歌在GFS上开发了一个列式存储器叫Column I/O。 Dremel使用Column I/O存储源数据。当做OLAP查询时,列式存储器要比行式存储器(row storage, 如MySQL)加载更少的数据,所以性能也就更好。
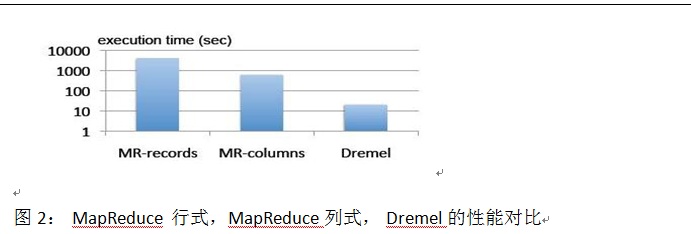
图2展示了Dremel在某个Benchmark下的性能提高幅度。 MR-Records是MapReduce在行式存储器上的速度,MR-Columns是MapReduce在Column I/O上的执行速度。我们可以看到:列式存储要比行式存储快十倍(从小时到分钟),而Dremel的服务器节点树构架要比MapReduce再快10倍(从分钟到秒)。
还有一点要提到的是Dremel本身对于Table-join的支持很有限,它只支持小Table和大table 之间的Join,而两个大Table之间的Join则不被支持。从逻辑上,Dremel的源数据就是一个大的数据表, 而在这个数据表中的每一个数据单元(data cell)本身又可以是一个嵌套的数据结构(nested data record)(在这一点上,它类似于MongoDB的数据结构)。图3显示了一个Dremel数据表中的两个数据单元样本和它们的结构定义。一个document单元必须有一个DocID, 可能有多个Forward和Backward Links, 还有一个或多个Name,每个Name还可能有多个Language 和 Url。我们可以看到,这是一个相当复杂的数据单元,为了有效查询数据单元,Dremel对SQL进行了扩展,这样即便没有Table Join, Dremel一样可以支持复杂的数据查询。

基于Dremel的后台支持,谷歌推出了一款新的收费服务叫BigQuery。用户可以上载大量数据到BigQuery上,然后用SQL对其上载的数据进行分析。服务根据处理的数据量来定价,每1TB数据被触动,收费35美元。BigQuery是简化了的Dremel,它不能处理嵌套数据结构,而只是处理二维平面Table.
Cloudera的Impala和MapR的Drill都是模仿Dremel的SQL执行引擎。Cloudera在2012年11月已经公开发布了Impala的Beta版本,而MapR的Drill则还在起始阶段。
Tenzing—一个更好的MapReduce平台
2011年,谷歌发表了Tenzing论文。Tenzing和Dremel类似,也支持SQL查询,但和Dremel不同,Tenzing仍然是将SQL翻译成一系列MapReduce任务来执行,这和Hive所做的事情是一样的, 只是Tenzing要比Hive快很多,一般的分析查询将在5—10秒内完成。
为了加快MapReduce的执行速度,Tenzing做了如下优化:
1. 创立工作进程池(Pooling of the Worker Processes),以节省初始化Mapper/Reducer工作进程的开销。
2. 回避在Map和Reduce阶段做没有必要的排序。对于一些SQL操作来说,比如Group-by, 数据的排序并不重要,它们可以通过HashMap来实现,而HashMap要比排序更省时间。
3. 中间结果集的数据重排(data shuffling)以数据块为单位而不是以数据行为单位。如果数据行之间没有必要排序,那么数据重排可以用1MB为单位的数据块进行。
4. 数据流(Streaming)。中间结果集可以从上一个MR任务通过网络直接流到下一个MR任务,而不需要先写入一个临时文件。
5. 客户端本地执行。对于小于128M的数据集的查询,可直接在客户端本地执行,而不是一定要通过MapReduce来执行。
6. 元数据(Meta-data)存取的优化。
Tenzing的执行速度要慢于Dremel,但是和Dremel相比,Tenzing有如下优点:
1. Tenzing支持所有的SQL92的操作,包括Tablejoin, Nested Query, 而Dremel只能支持在一个Table上的查询(还有小的Table join)。
2. Tenzing支持各种各样类型的数据源,包括GFS,BigTable,Column I/O,而Dremel只能支持column I/O。
3. Tenzing比Dremel有更好的可扩展性,可以支持更加大规模的数据集。
YouTubeBI构架
YouTube是谷歌的子公司。它原来使用第三方的RMDB和BI工具作为BI的技术构架。现在改成使用GFS/Column IO作为数据仓库平台,Dremel作为主要的SQL执行引擎,自己开发的ABI作为报表工具,Tenzing作为辅助的SQL查询工具。这样形成了一个完整的BI体系结构。图4展示了YouTube现在使用的BI技术框架。
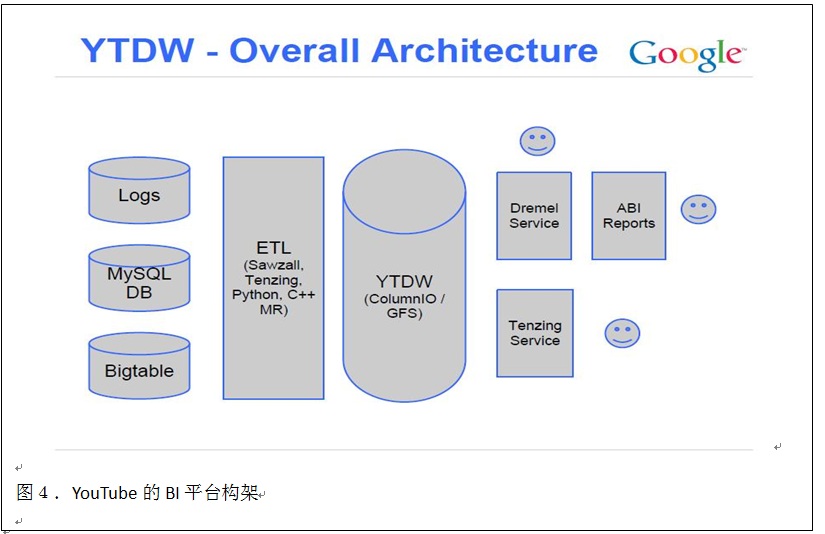
从图4我们可以看到,原始数据首先从不同的数据源被ETL到基于GFS/Column IO搭建的数据仓库。ABI是谷歌内部开发的报表工具,它能很好地和Dremel还有Column IO整合在一起。ABI使用Memcached作为报表的Cache。
ABI和Dremel可以满足Youtube绝大多数的分析需求。对于某些复杂的分析,分析师可以在Tenzing上手工执行SQL完成。
根据Youtube BI团队的预期,在未来,Tenzing的功能将被更多地推入Dremel,最终Dremel将取代Tenzing成为统一的查询引擎。
Impala
Impala是Dremel在Hadoop上的复制品,它由Cloudera开发,2012年11月Beta,2013年第一季度GA。 Impala 支持Hive的界面,数据存放在HDFS上。 它号称性能要好于MapReduce—Hive30倍,但这还有待于核实。到目前为止,Impala对于列式存储的支持还不完善。 Impala的内核用C++开发,外面包裹一层Java和Hive Java源代码交互。 这款产品是这几年来Hadoop数据分析师最为期待的产品。如果Impala发布获得成功,我们有理由相信Cloudera将会成为大数据BI领域里一个巨人。
本文转载自http://blog.csdn.net/xhanfriend/article/details/8434896

