
request 进阶 爬虫
1. 处理cookie(解决登录问题) 17k小说
# 1. 登录 -> 得到cookie
# 2. 带着cookie发送请求 -> 获取到书架信息
# 注意: 必须把上面了两步连起来
# 可以使用session进行请求 -> session表示一连串的请求,并且在请求的过程中cookie不会丢失
import requests
# 会话
session = requests.session()
data = {
"loginName": "17341772871",
"password": "WQX5201314"
}
# 1. 登录
url = 'https://passport.17k.com/ck/user/login'
# post 方法
resp = session.post(url, data=data)
resp.encoding = 'utf-8'
# print(resp.text)
# print(resp.cookies)
# 2. 拿数据
data_url = 'https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919'
# 这里是使用 session 发送请求(只有它才有cookie)
data_resp = session.get(data_url)
print(data_resp.json(), '方法一(常用)') # 打印出书架上的信息
resp.close()
data_resp.close()
# 方法二 不推荐使用(但是要知道)
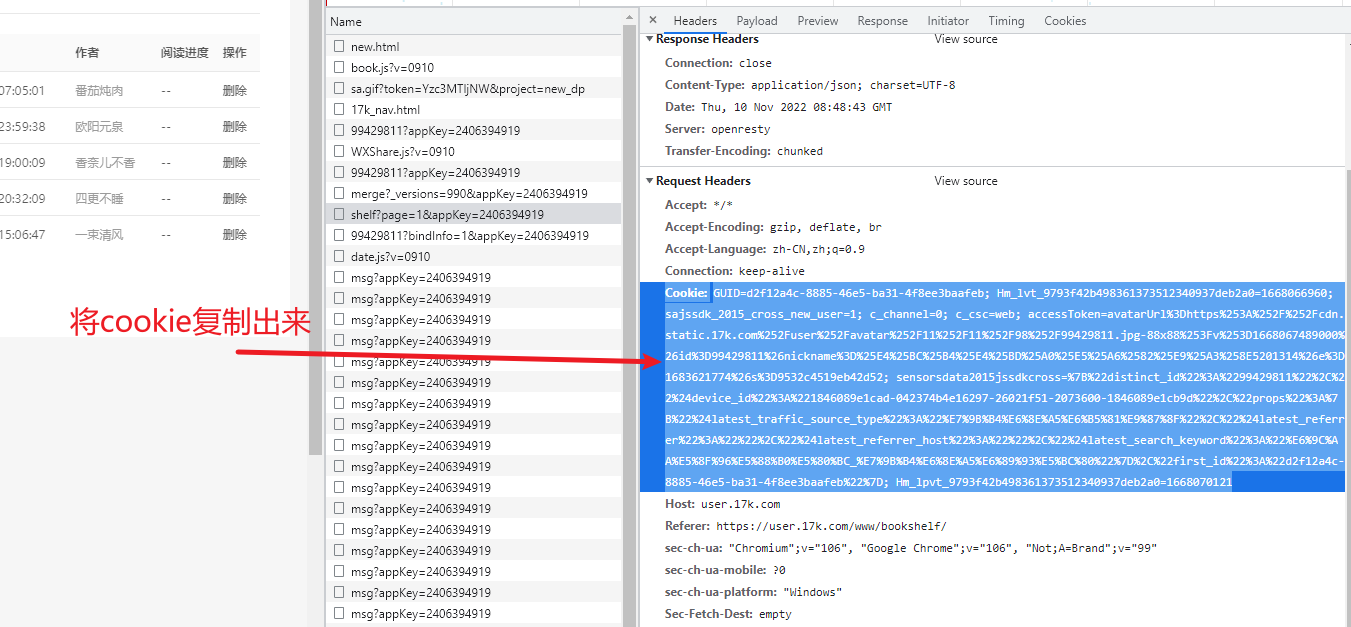
result = requests.get(data_url, headers={
"Cookie": "GUID=d2f12a4c-8885-46e5-ba31-4f8ee3baafeb; Hm_lvt_9793f42b498361373512340937deb2a0=1668066960; sajssdk_2015_cross_new_user=1; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F11%252F11%252F98%252F99429811.jpg-88x88%253Fv%253D1668067489000%26id%3D99429811%26nickname%3D%25E4%25BC%25B4%25E4%25BD%25A0%25E5%25A6%2582%25E9%25A3%258E5201314%26e%3D1683621774%26s%3D9532c4519eb42d52; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2299429811%22%2C%22%24device_id%22%3A%221846089e1cad-042374b4e16297-26021f51-2073600-1846089e1cb9d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22d2f12a4c-8885-46e5-ba31-4f8ee3baafeb%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1668070121"
})
print(result.json(), '方法二')
2. 防盗链 referer
url = 'https://www.pearvideo.com/video_1773623'
# 反反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
# 验证
"Cookie": "aliyungf_tc=ee2b18b9c9d2a17436246c5a1bf43f52fee9b250bdb7508d1efa6acf1dcf2bad; acw_tc=707c9f6e16680762338956689e5f370c24c95078f027837999f40a9859e33b; JSESSIONID=34CFA45C758BC03C6126B1FB04C41B84; PEAR_UUID=304d8a6d-676e-49fe-910e-7117633f5b9f; _uab_collina=166807623429532218996962; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1668076235; p_h5_u=84EEAB5A-F836-439B-82C7-2557CE16063E; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1668076920; SERVERID=a7cc60ddba048546c9441d2558c201d4|1668076924|1668076233",
# 防盗链: 溯源 => 本次请求的上一级是谁 可以返回上一级
"Referer": url
}
# 下载视频
with open('a.mp4', mode='wb') as f:
# 将视频写入到文件中(保存)
f.write(requests.get(srcUrl).content)
# coding=utf-8
# 1. 拿到contid
# 2. 拿到videoStatus返回的json -> srcUrl
# 3. srcUrl 拿到的数据进行修整
# 4. 下载视频
import requests
# 拉取视频的网址
url = 'https://www.pearvideo.com/video_1773623'
contid = url.split('_')[1] # 1773623
# print(contid)
videoStatusUrl = f'https://www.pearvideo.com/videoStatus.jsp?contId={contid}&mrd=0.4192834167387307'
# 反反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36",
# 验证
"Cookie": "aliyungf_tc=ee2b18b9c9d2a17436246c5a1bf43f52fee9b250bdb7508d1efa6acf1dcf2bad; acw_tc=707c9f6e16680762338956689e5f370c24c95078f027837999f40a9859e33b; JSESSIONID=34CFA45C758BC03C6126B1FB04C41B84; PEAR_UUID=304d8a6d-676e-49fe-910e-7117633f5b9f; _uab_collina=166807623429532218996962; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1668076235; p_h5_u=84EEAB5A-F836-439B-82C7-2557CE16063E; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1668076920; SERVERID=a7cc60ddba048546c9441d2558c201d4|1668076924|1668076233",
# 防盗链: 溯源 => 本次请求的上一级是谁 可以返回上一级
"Referer": url
}
resp = requests.get(videoStatusUrl, headers=headers)
# print(resp.json())
dic = resp.json()
# 编号(有问题的)
systemTime = dic['systemTime']
# 视频的地址(有问题的)
srcUrl = dic['videoInfo']['videos']['srcUrl']
# print(systemTime, srcUrl)
# replace() 替换 用第二个参数替换第一个参数
srcUrl = srcUrl.replace(systemTime, f'cont-{contid}')
print(srcUrl)
# https://video.pearvideo.com/mp4/third/20221028/cont-1773623-11852754-144851-hd.mp4 正常的
# https://video.pearvideo.com/mp4/third/20221028/1668080492072-11852754-144851-hd.mp4 有问题的
# 下载视频
with open('a.mp4', mode='wb') as f:
# 将视频写入到文件中(保存)
f.write(requests.get(srcUrl).content)
resp.close()
3. 代理: 被封了IP才用(少用)
直接在 浏览器搜索 免费代理IP 找到ip和端口号使用即可
透明的比较好用, 高匿名不行
# 原理: 通过第三方的机器发送请求
import requests
url = 'https://www.baidu.com/'
# 指定代理 IP :冒号后面是端口号
# 112.5.56.2:9091
proxies = {
# 这里是那个就选择那个(看链接决定)
# "http": "http://113.31.118.22:80",
"https": "https://113.31.118.22:80"
}
# 添加代理 只有能拿到数据则表示添加代理成功
resp = requests.get(url, proxies=proxies)
# 指定字符集
resp.encoding = 'utf-8'
print(resp.text)
resp.close()
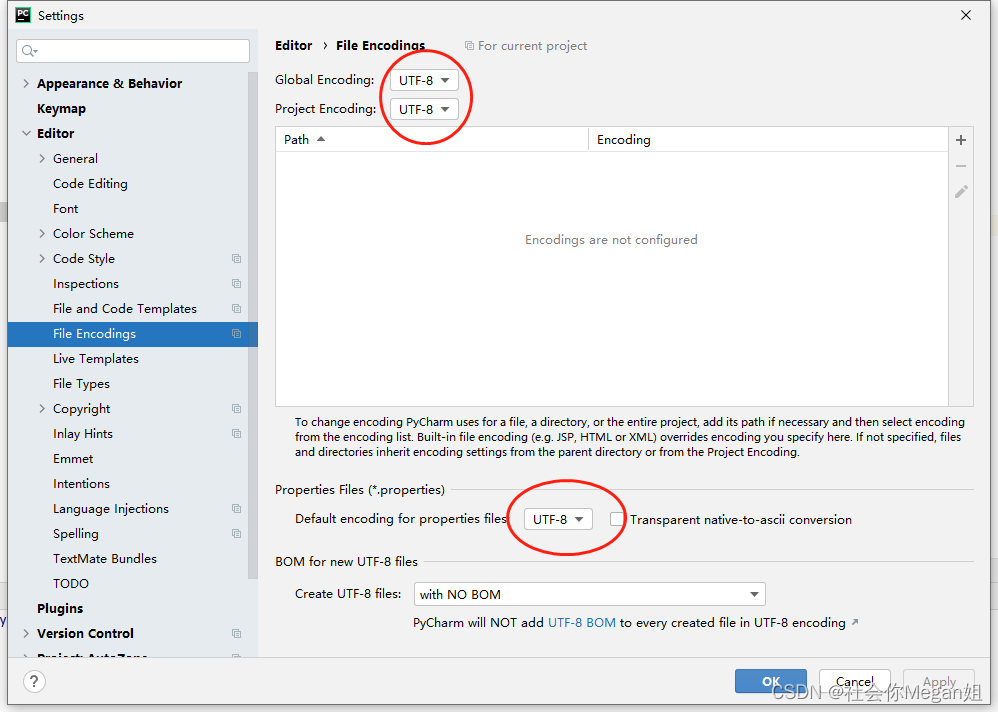
4. 指定字符集


 浙公网安备 33010602011771号
浙公网安备 33010602011771号