0. 可以将图片、文本、视频在Pycharm中设置(避免卡顿)
1. 将爬取的数据写入到 文件中
安装 bs4
# pip install bs4
# 1. 获取页面源代码
# 2. 使用bs4解析获取需要的数据
# 导入 csv
import csv
f = open('data.csv', mode='w', encoding='utf-8')
csvwrite = csv.writer(f)
# 注意 位置(在Python文件中的位置)
# 把数据存放在文件中 txt 是需要保存的数据
csvwrite.writerow(txt)
print('over!!!', '数据提取完毕')
# 写入文件方法二
# 将图片写入到文件中(保存到本地) img_name 这里是图片文件名
with open("img/"+img_name, mode="wb") as f:
f.write(img_resp.content) # 将内容写入到文件中
print('over!!!', img_name)
2. 使用 bs4 爬取数据
1. find(标签, 属性=值) 找一个
2. find_all(标签, 属性=值) 找所有的
# 先安装 bs4
# pip install bs4
# 1. 获取页面源代码
# 2. 使用bs4解析获取需要的数据
import requests
# 导入 bs4
from bs4 import BeautifulSoup
# 导入 csv
import csv
f = open('img.csv', mode='w')
csvwriter = csv.writer(f)
url = "https://movie.douban.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
# print(resp.text)
# 解析数据
# 1. 把页面源代码交给BeautifulSoup,生成bs对象
# 2. 从bs中查找对象 find(标签, 属性=值) 找一个 find_all(标签, 属性=值) 找所有的
# 会出现一个警告 需要加上 "html.parser"
page = BeautifulSoup(resp.text, "html.parser") # 指定 html 的解析器
# 注意: class="btn" 会报错
# 因为class是python 的关键字,所以写属性需要这样写 class_="btn"
# 写法一
# ul = page.find('ul', class_="ui-slide-content")
# 写法二
ul = page.find('ul', attrs={"class": "ui-slide-content"})
# print(ul)
li = ul.find_all('li')[1:2]
# print(li)
for x in li:
img = x.find('img', alt="我的遗憾和你有关")
# print(img)
csvwriter.writerow([img])
f.close()
print('over!!!')
resp.close()
3. 获取 优美图库 的可爱壁纸
# coding=utf-8
# 1. 获取到主页面的源代码,并提取子页面的链接 href
# 2. 通过href获取到子页面的源代码, 再从子页面提取到图片的下载地址 img -> src
# 3. 下载图片
import time
import requests
from bs4 import BeautifulSoup
url = 'https://www.umei.cc/bizhitupian/keaibizhi/'
base1 = 'https://www.umei.cc/'
resp = requests.get(url)
resp.encoding = 'utf-8' # 处理乱码
# print(resp.text)
# 将源码给bs html.parser 解决控制台警告问题
main_page = BeautifulSoup(resp.text, "html.parser")
# 找到图片区域的源代码,将所有的 a 标签找到
# find_all() 返回的是列表
alist = main_page.find('div', id="infinite_scroll").find_all('a')
# print(alist)
for x in alist:
# print(x.get('href'), 123) # 测试(没有拼接域名)
# 获取属性使用 get 方法 拼接成为一个完整的url地址
href = base1 + x.get('href').strip("/")
# 获取子页面的源代码
child_page_resp = requests.get(href)
child_page_resp.encoding = 'utf-8' # 指定字符集
child_page_text = child_page_resp.text
# 从子页面拿到图片的下载路径
child_page = BeautifulSoup(child_page_text, "html.parser")
div = child_page.find('div', class_="big-pic")
img = div.find('img')
# 获取到图片的下载链接
src = img.get('src')
# 下载图片
img_resp = requests.get(src)
# img_resp.content # 这里返回的是字节
img_name = src.split('/')[-1] # 获取到链接/后面的字符给img当名字
# img_name 就是这样的 fmnx1geb01.jpg
# 将图片写入到文件中(保存到本地)
with open("img/"+img_name, mode="wb") as f:
f.write(img_resp.content) # 将内容写入到文件中
print('over!!!', img_name)
# 加上等待时间(避免被封杀)
time.sleep(1)
print('all_over!!!')
resp.close()
注意: 修改文件主要修改 find()后面的 就可以了
4. xpath 入门
text() 拿到文本
// 找后代
* 通配符(啥都行)
@href 获取到 href属性的值
# 安装 xml 模块
pip install lxml
# xpath 是在 XML 文档中搜索内容的一门语言
# html 是 XML 的一个子集
# 安装 xml 模块
# pip install lxml
# xpath解析
from lxml import etree
xml = """
<book>
<id>1</id>
<name>野花遍地香</name>
<price>1.23</price>
<nick>臭豆腐</nick>
<author>
<nick id="10086">周大强</nick>
<nick id="10010">周芷若</nick>
<nick class="joy">周杰伦</nick>
<nick class="jolin">蔡依林</nick>
<div>
<nick>热热热热热1</nick>
</div>
<span>
<nick>热热热热热2</nick>
</span>
</author>
<partner>
<nick id="ppc">胖胖陈</nick>
<nick id="ppbc">胖胖不陈</nick>
</partner>
</book>
"""
tree = etree.XML(xml)
# / 表示层级关系,第一个/表示根节点
# result = tree.xpath("/book")
# result = tree.xpath("/book/name/text()") # text() 拿到文本
# result = tree.xpath("/book/author/nick/text()")
# result = tree.xpath("/book/author//nick/text()") # // 找后代
# result = tree.xpath("/book/author/*/nick/text()") # // * 通配符(啥都行)
result = tree.xpath("/book/author//nick/text()")
print(result)
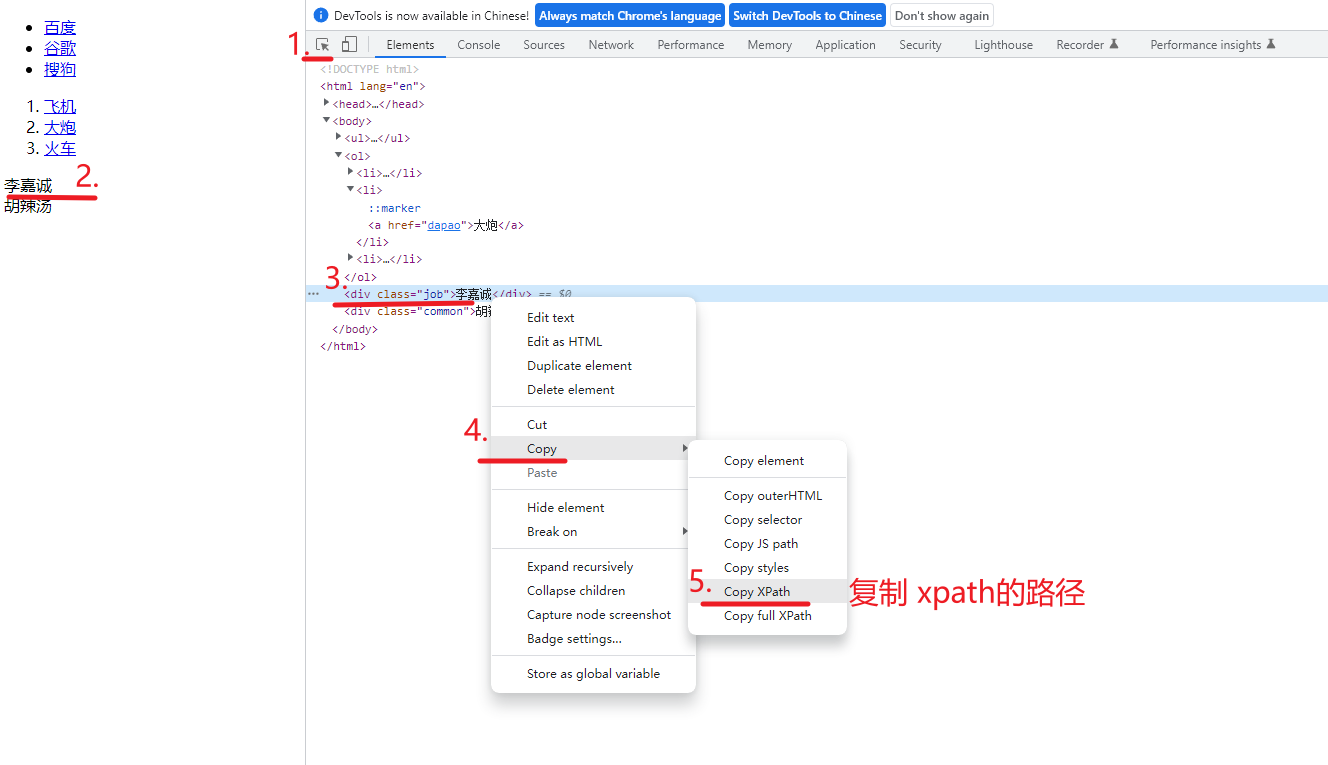
5. xpath 使用(小技巧)
from lxml import etree
# parse("b.html") 将本地b.html文件提取出来使用
tree = etree.parse("b.html")
xpath是从第1个开始数的
@href='dapao' 只获取href属性时dapao的值
# result = tree.xpath("/html/body/ol/li/a[@href='dapao']/text()")
# 获取到子节点的数据
./ 表示相对路径查找(从li这个位置开始查找)
# 获取到 a 标签中href的值
print(tree.xpath("/html/body/ol/li/a/@href"))
注意: 这个代码不完整(不能直接运行)
# coding=utf-8
# 1. 拿到页面源代码
# 2. 使用 xpath解析数据
import requests
from lxml import etree
# 猪八戒网站
url = 'https://nanchong.zbj.com/search/service/?kw=saas&r=2'
resp = requests.get(url)
resp.encoding = 'utf-8'
print(resp.text)
# etree.HTML 将html的源码 给一个变量
html = etree.HTML(resp.text)
resp.close()
6. 使用xpath获取图片
# coding=utf-8
# 1. 拿到页面源代码
# 2. 使用 xpath解析数据
import requests
from lxml import etree
import time
# 猪八戒网站
url = 'http://meirenxuan.cc/xiezhen/2652.html'
resp = requests.get(url)
resp.encoding = 'utf-8'
# print(resp.text)
# etree.HTML 将html的源码 给一个变量
html = etree.HTML(resp.text)
# 获取到Element元素(再提取需要的信息)
divs = html.xpath('//*[@id="gallery-2"]')
# 获取到每一项的 图片
for div in divs:
href = div.xpath('./div/a/@href')
# href 是列表(所以需要循环)
for image_url in href:
print(image_url, '图片地址')
# 下载图片
img_resp = requests.get(image_url)
# 给文件起名字 split 只能给字符串使用
img_name = image_url.split("/")[-1] # 拿到url中的最后一个/以后的内容
# 将图片写入到文件中(保存到本地) img_name 这里是图片文件名
with open("img/" + '美女妹妹' + img_name, mode="wb") as f:
# img_resp.content # 这里拿到的是字节 (图片)
f.write(img_resp.content) # 将内容写入到文件中
print('over!!!', img_name)
time.sleep(1)
resp.close()
f.close()
print('all_over!!!')

