
python 爬虫
1. 手写第一个 python 爬虫
# 爬虫: 用程序来获取网站上的资源
# 常用 encoding='utf-8' encoding='gbk'
# 1. 导入 urllib.request urlopen
from urllib.request import urlopen
# 2. 设置目标网址,并使用urlopen来访问
# 访问完成是有返回数据的 使用resp来接收
url = 'http://www.baidu.com'
resp = urlopen(url)
# encoding('utf-8') 将字节转换为字符串
# 使用 utf-8 编码格式 还有 gbk 格式
# as 起别名
with open('mybaidu.html', mode='w', encoding='utf-8') as f:
f.write(resp.read().decode('utf-8'))
print('over')
resp.close() # 关闭 resp 不然多了会出现奇奇怪怪的问题
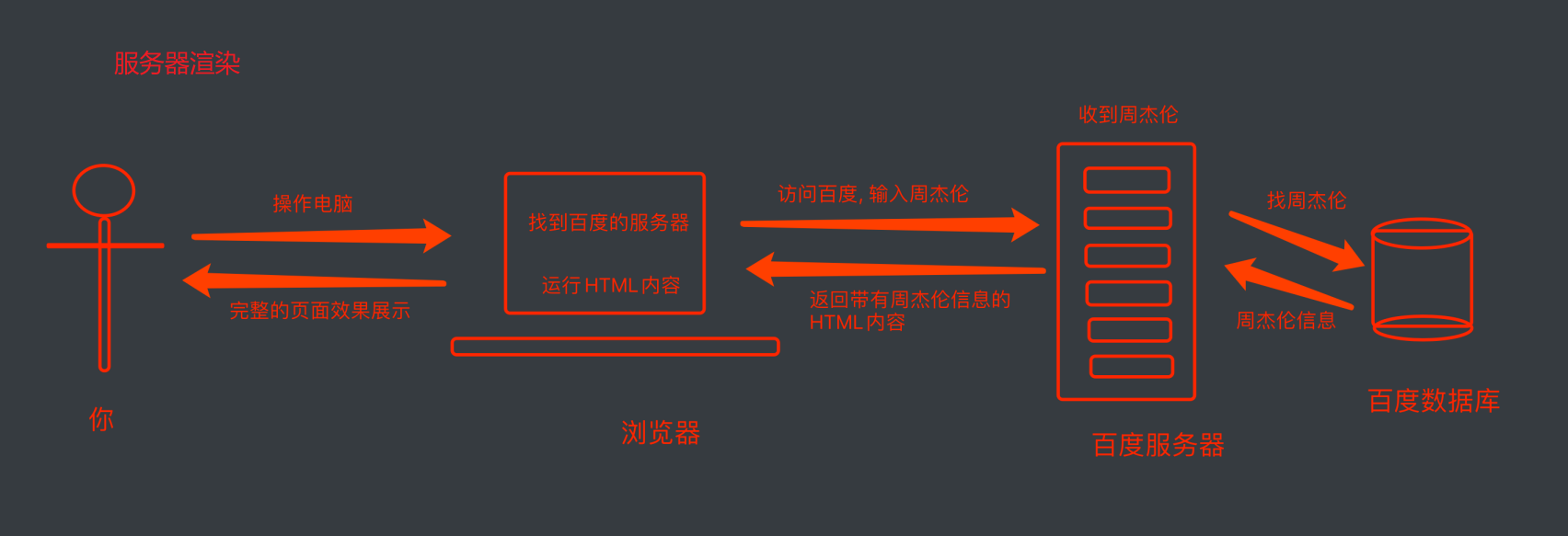
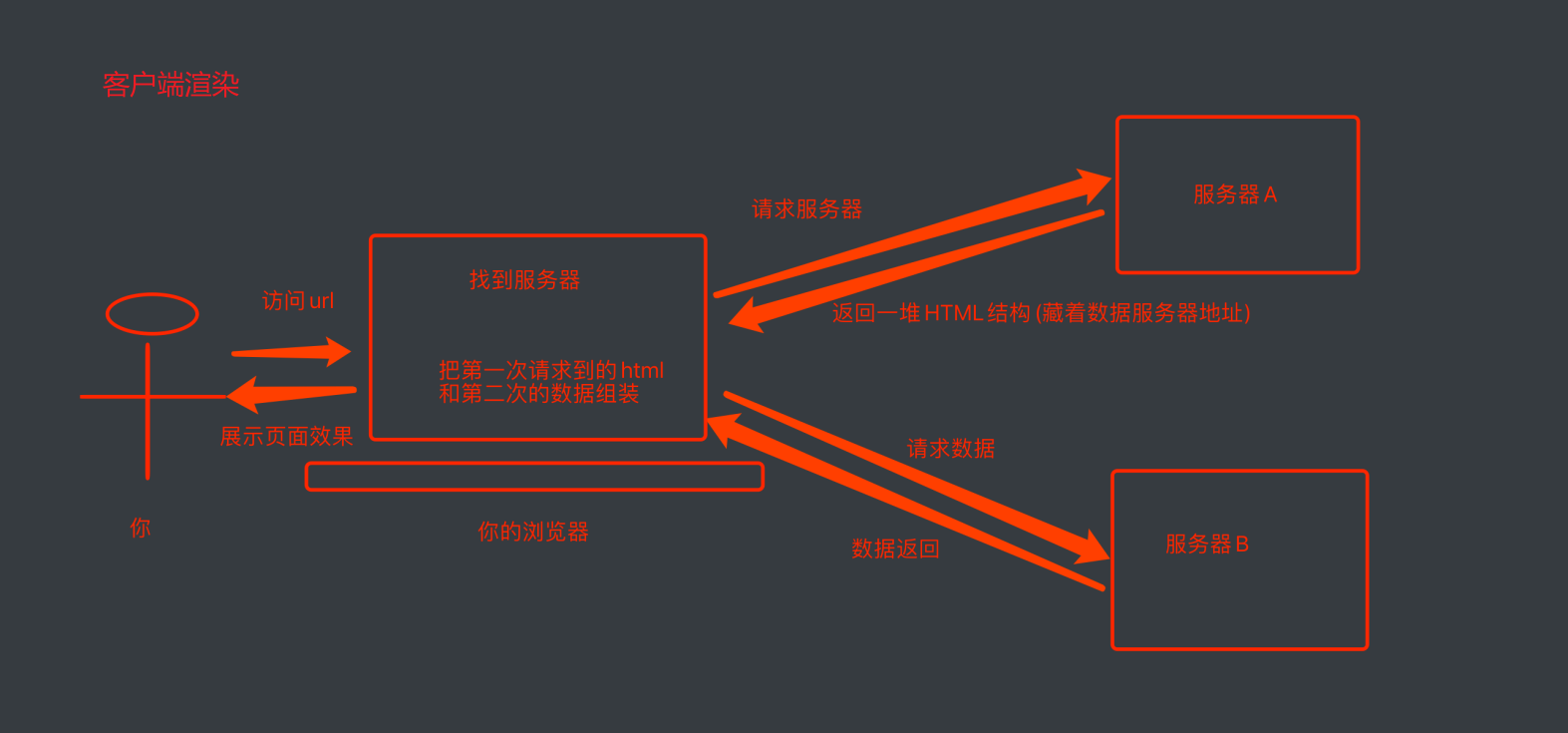
2. web请求过程剖析
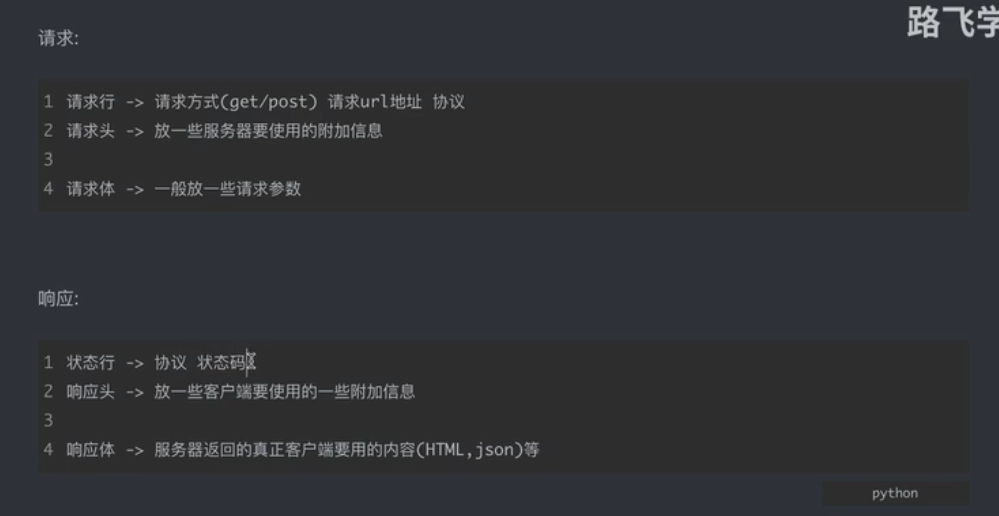
3. HTTP协议
4. requests 第三方库 清华源
# 先下载 requests 第三方包
# pip install requests
# 国内源 清华源
# 临时使用一次
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
# 导入 requests 包
import requests
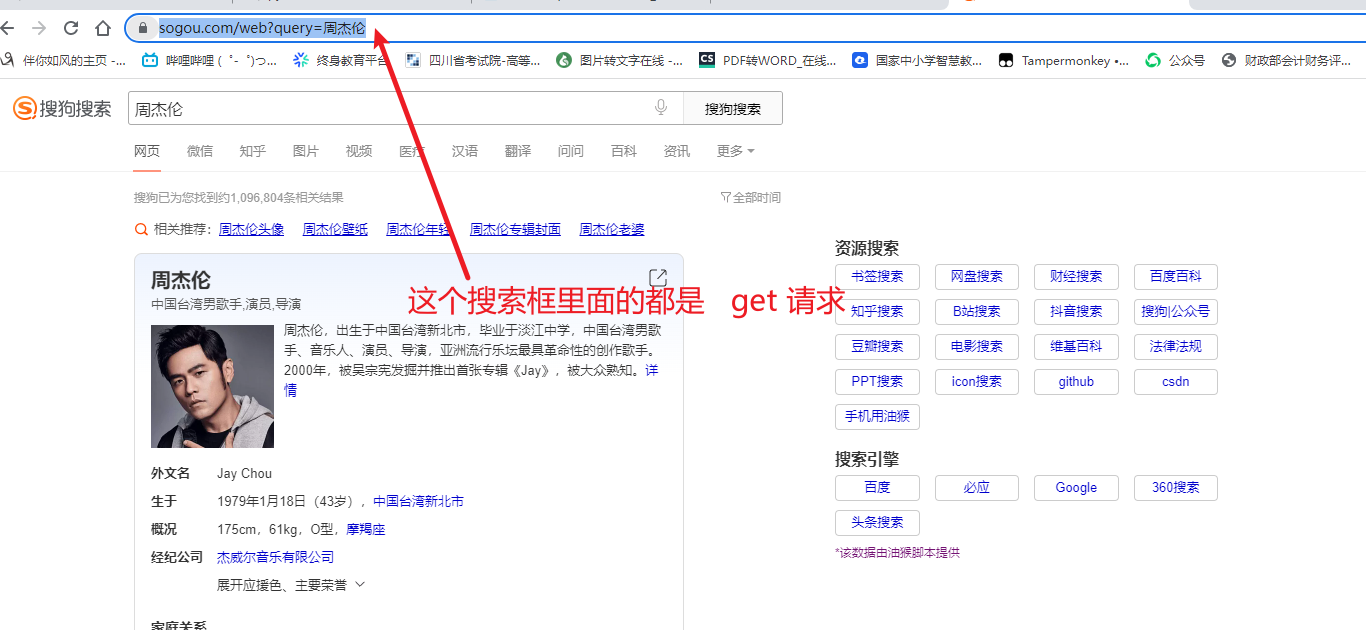
query = input('输入一个你要搜索的明星:')
url = f'https://www.sogou.com/web?query={query}'
# 在搜索框里面的 url 的请求方式都是 get 方式
# 请求完成都会有返回的数据
# 处理了一个小小的反爬问题
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
print(resp)
print(resp.text) # 获取页面源代码
resp.close() # 关闭 resp 不然多了会出现奇奇怪怪的问题
5. pip 切换为清华源(国内镜像源)
# 临时使用一次 将 some-package 切换为包的名字
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
# 设为默认
python -m pip install --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 如果您到 pip 默认源的网络连接较差,临时使用本镜像站来升级 pip:
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
6. 两个爬虫小文件
传参数使用的变量名
get params
post data
# request 入门
import requests
url = 'https://fanyi.baidu.com/sug'
s = input('请输入你要翻译的单词!')
dat = {
'kw': s
}
# 发送数据和参数,会有返回值用 resp 来接收
# 发送 post 请求, 发送的数据必须在字典中,使用data来传递数据
resp = requests.post(url, data=dat)
# 1. 这里不能使用 text 因为会出现乱码的情况
# 2. 直接将数据转换为 JSON 文件 => dict(字典)
print(resp.json())
resp.close() # 关闭 resp 不然多了会出现奇奇怪怪的问题
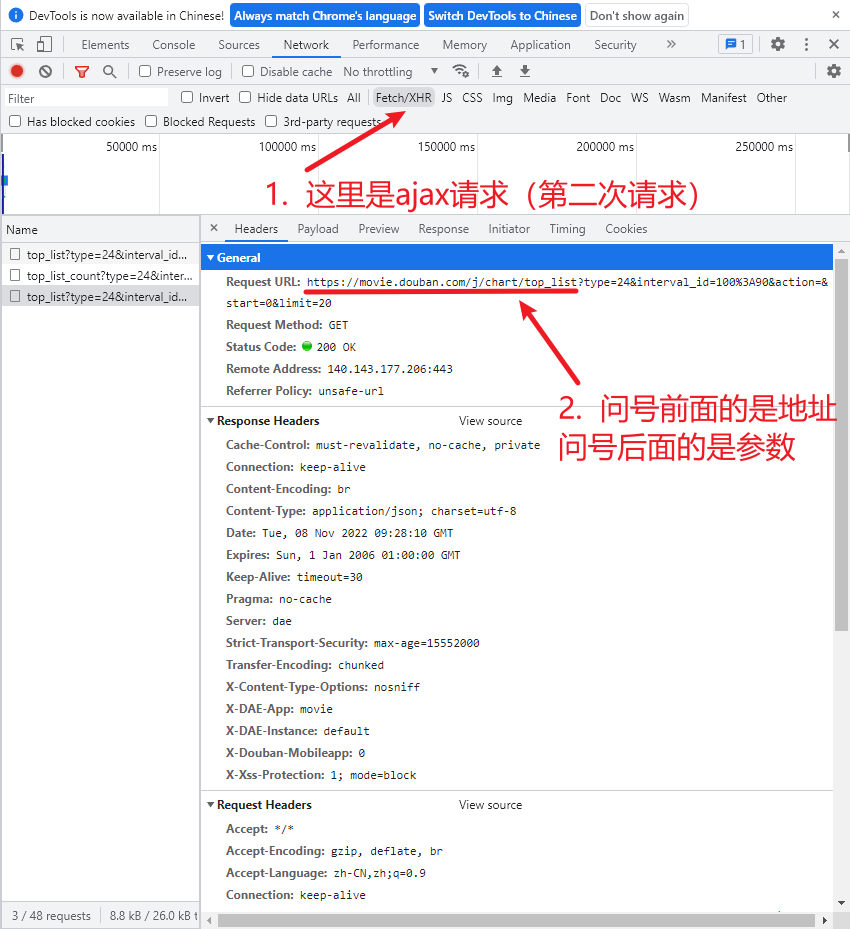
# request豆瓣
import requests
url = "https://movie.douban.com/j/chart/top_list"
# 优化参数 参数里面有空格(恶心的坑)会获取到一个空列表 []
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
# 防止反爬 设置请求头 User-Agent
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
# url 和 params 名字一样可以省略(只写一个即可)
# 注意: get 请求 参数是 params 而 post 请求参数是 data
resp = requests.get(url=url, params=param, headers=headers)
# 被反爬了 需要设置 User-Agent
# print(resp.request.headers)
# 查看爬取到的数据
print(resp.json())
resp.close() # 关闭 resp 不然多了会出现奇奇怪怪的问题
第二章 数据解析概述
1. re解析
2. bs4解析
3. xpath解析
7. re解析 使用 正则表达式
元字符: 具有固定含义的特殊符号 常⽤元字符
. 匹配除换⾏符以外的任意字符
\w 匹配字⺟或数字或下划线
\s 匹配任意的空⽩符
\d 匹配数字
^ 匹配字符串的开始
$ 匹配字符串的结尾
[a-zA-Z0-9] 匹配字符组中的字
量词: 控制前⾯的元字符出现的次数
* 重复零次或更多次
+ 重复⼀次或更多次
? 重复零次或⼀次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
贪婪匹配和惰性匹配 (很重要)
.* 贪婪匹配 竟可能多的去匹配
.*? 惰性匹配 竟可能少的去匹配
8. re模块
# 导入 re 模块, 常用的 finditer方法 返回的是迭代器
import re
# findall 返回符合正则表达式的所有内容
list = re.findall(r'\d+', "我的手机号:1008611, 还有一个是10000")
print(list)
# finditer 常用
# finditer 返回符合正则表达式的所有内容 (返回的是迭代器)
# 要拿到内容 需要使用 .group函数来获取返回的内容
iter = re.finditer(r'\d+', "我的手机号:1008611, 还有一个是10000")
print(iter)
# 只有 finditer 才有 group 方法
for x in iter:
print(x.group())
# search返回的是Match数据,那数据需要使用.group()
# 只获取第一个数据,获取到后立马返回(不会再找下一个)
s = re.search(r'\d+', "我的手机号:1008611, 还有一个是10000")
print(s.group()) # 1008611
# match 是从头开始匹配,若开头与正则表达式不匹配,则会报错
z = re.match(r'\d+', "1008611, 还有一个是10000")
print(z.group())
# 预加载正则表达式 compile 表示预加载 (可以重复使用)
obj = re.compile(r'\d+')
it = obj.finditer("我的手机号:1008611, 还有一个是10000")
print(it)
for y in it:
print(y.group())
result = obj.findall('呵呵, 你要还我一个100000000')
print(result)
9. 在 html 中提取所需要的数据
s = """
<div class='jar'><span id='1'>中国联通</span></div>
<div class='jj'><span id='2'>中国电信</span></div>
<div class='aa'><span id='3'>中国移动</span></div>
"""
obj1 = re.compile(r"<div class='(?P<id>.*?)'><span id='.*?'>(?P<xinming>.*?)</span></div>", re.S) # re.S 匹配到换行符
result1 = obj1.finditer(s)
for xx in result1:
print(xx.group('id'))
print(xx.group('xinming'))
# (?P<xinming>.*?) (?P<里面写名字>) 后续通过属性名字来获取我们所需要的数据
10. 获取豆瓣top250前面的几条数据
# 1. 获取页面源代码 requests
# 2. 提取页面的有效信息 re模块
import requests
import re
# 创造 csv 文件 方便分析数据
import csv
url = 'https://movie.douban.com/top250'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers)
# 获取到页面的内容
page_content = resp.text
# 解析数据 (到豆瓣top250源码 分析得来) re.S 匹配到换行符
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)'
r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?<span '
r'class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'
r'<span>(?P<num>.*?)</span>', re.S)
# 开始匹配
result = obj.finditer(page_content)
# 创建data.csv文件
f = open('data.csv', mode='w')
# 写入文件
csvwriter = csv.writer(f)
# strip 去除数据前面的空白
for it in result:
# print(it.group('name'))
# print(it.group('year').strip())
# print(it.group('score'))
# print(it.group('num'))
# 将数据写入带字典中 groupdict() 返回字典
dic = it.groupdict()
# 处理年数据的空白符 strip() 去除头尾的空格
dic['year'] = dic['year'].strip()
# 将 数据写入到dat.csv 文件中
# 注意: writerow()将一个列表全部写入csv的同一行。
csvwriter.writerow(dic.values())
resp.close()
f.close()
print('over!')
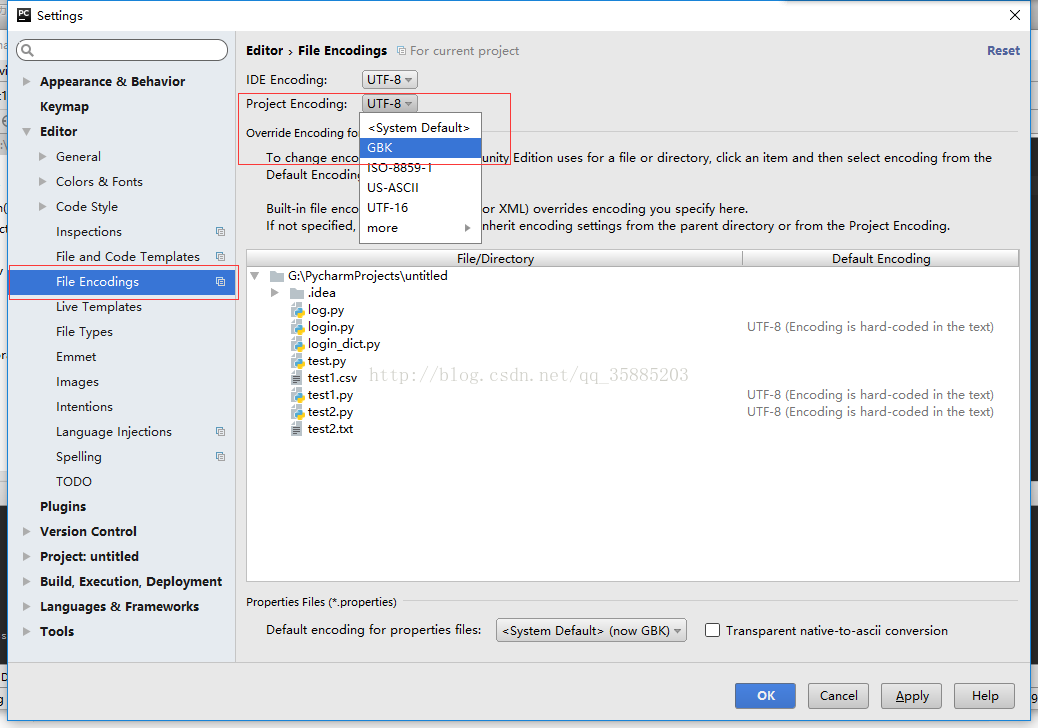
pycharm打开csv文件,csv文件中的中文出现乱码的解决方案
这是因为pycharm中默认设置是以utf-8的编码方式打开文件,而csv的文件正确读取方式是GBK,使用 UTF-8 自然会造成乱码
解决方法为:修改pycharm的默认设置为 GBK 即可。
11. pycharm 安装插件
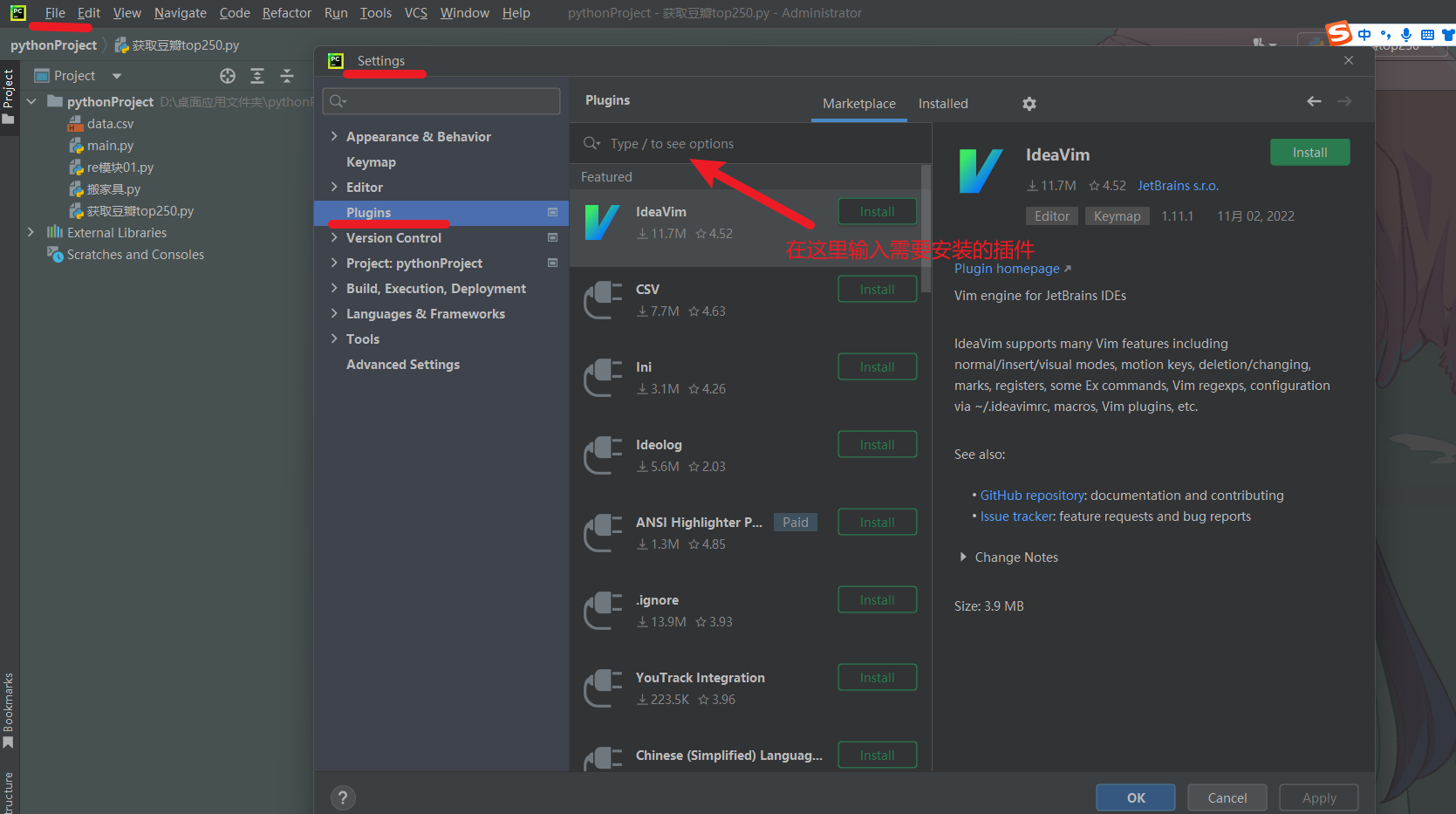
1. csv
2. Translation
12. 获取 电影天堂 的部分下载链接
注意: SyntaxError:Non-UTF-8 code starting with '\xb6' in file E:/.../....py on line 16, but no encoding declared;
解决方法
# coding=utf-8
在第一行加上上面的代码(带 # 号)
# charset 表示使用什么字符集
charset = gbk 或者 utf-8
# coding=utf-8
# 1. 定位到2022年电影热片
# 2. 获取子页面的链接信息
# 3. 请求子页面获取我们需要的下载链接
import requests
import re
domain = "https://www.dytt89.com/"
# verify=False 去掉安全验证
resp = requests.get(domain, verify=False)
# 指定字符集
resp.encoding = 'gbk'
# print(resp.text)
# 设置re模块 预加载
# 获取到 ul 中的 li
obj1 = re.compile(r"2022必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S)
# 获取子页面中href的内容
obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S)
# 定义第三个正则表达式
obj3 = re.compile(r'◎片 名 (?P<movie>.*?)<br />.*?<td '
r'style="WORD-WRAP: break-word" bgcolor="#fdfddf">'
r'<a href="(?P<download>.*?)">', re.S)
result1 = obj1.finditer(resp.text)
# 创建一个装 子页面链接的列表
child_href_list = []
for it in result1:
ul = it.group('ul')
# print(ul)
result2 = obj2.finditer(ul)
for itt in result2:
# 拼接子页面链接 域名 + 子页面地址
# 干掉子页面链接的第一个/(右斜杠)
child_href = domain + itt.group('href').strip("/")
# print(itt.group('href'))
# 打印子页面的链接
# print(child_href)
# 将子页面的链接全部添加到列表中
child_href_list.append(child_href)
# 3. 获取子页面的内容
for href in child_href_list:
child_resp = requests.get(href)
# 设置字符集
child_resp.encoding = 'gbk'
# 打印子页面的信息
# print(child_resp.text)
# 子页面中使用obj3的正则来匹配所需要的内容
result3 = obj3.search(child_resp.text)
# 打印从子页面提取的信息
print(result3.group("movie"))
print(result3.group("download"))
# 终止循环(这里只获取第一条信息)
# break
resp.close()
