MHA实现MySQL的高可用
MHA实现MySQL的高可用
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA里有两个角色一个是MHA Node(数据节点)另一个是MHA Manager(管理节点)。 MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
MHA的工作原理
相较于其它HA软件,MHA的目的在于维持MySQL Replication中Master库的高可用性,其最大特点是可以修复多个Slave之间的差异日志,最终使所有Slave保持数据一致,然后从中选择一个充当新的Master,并将其它Slave指向它。
-
从宕机崩溃的master保存二进制日志事件(binlogevents)。
-
识别含有最新更新的slave。
-
应用差异的中继日志(relay log)到其它slave。
-
应用从master保存的二进制日志事件(binlogevents)。
-
提升一个slave为新master。 -使其它的slave连接新的master进行复制。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器。
MHA的优点总结
-
自动的故障检测与转移,通常在10-30秒以内
-
MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概0.5-2秒内即可完成。
-
很好地解决了主库崩溃数据的一致性问题。
-
不需要对当前的mysql环境做重大修改。
-
不需要在现有的复制框架中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量。
-
性能优秀,可以工作在半同步和异步复制框架,支持gtid,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
-
只要replication支持的存储引擎都支持MHA,不会局限于innodb。
-
对于一般的keepalived高可用,当vip在一台机器上的时候,另一台机器是闲置的,而MHA中并无闲置主机。
GTID主从复制
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用自MySQL 5.5开始引入的半同步复制,可以大大降低数据丢失的风险。
MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性,或者采用GTID。
首先搞清楚GTID
从MySQL 5.6.2 开始新增了一种基于 GTID 的复制方式,用以替代以前传统的复制方式,到MySQL5.6.10后逐渐完善。通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的ID。这种方式强化了数据库的主备一致性,故障恢复以及容错能力,那么它如何做到的呢?
要想在分布式集群环境中不丢失事务,就必须为每个事务定制一个全局唯一的ID号,并且该ID是趋势递增的,以此我们便可以方便地顺序读取、不丢事务,其实GTID就是一种很好的分布式ID实践方案,它满足分布ID的两个基本要求
-
- 全局唯一性
- 趋势递增
GTID (Global Transaction ID全局事务ID)是如何做到全局唯一且趋势递增的呢,它是由UUID+TID两部分组成。
-
- UUID是数据库实例的标识符
- TID表示事务提交的数量,会随着事务的提交递增
因此他与主库上提交的每个事务相关联,GTID不仅对其发起的服务器是唯一的,而且在给定复制设置中的所有服务器都是唯一的,即所有的事务和所有的GTID都是1对1的映射。
当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务,对DBA来说意义就很大了,我们可以适当的解放出来,不用手工去可以找偏移量的值了,而是通过CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION=1的即可方便的搭建从库,在故障修复中也可以采用MASTER_AUTO_POSITION= 'X' 的方式。
5.7版本GTID做了增强,不手工开启也自动维护匿名的GTID信息。
GTID主从的原理
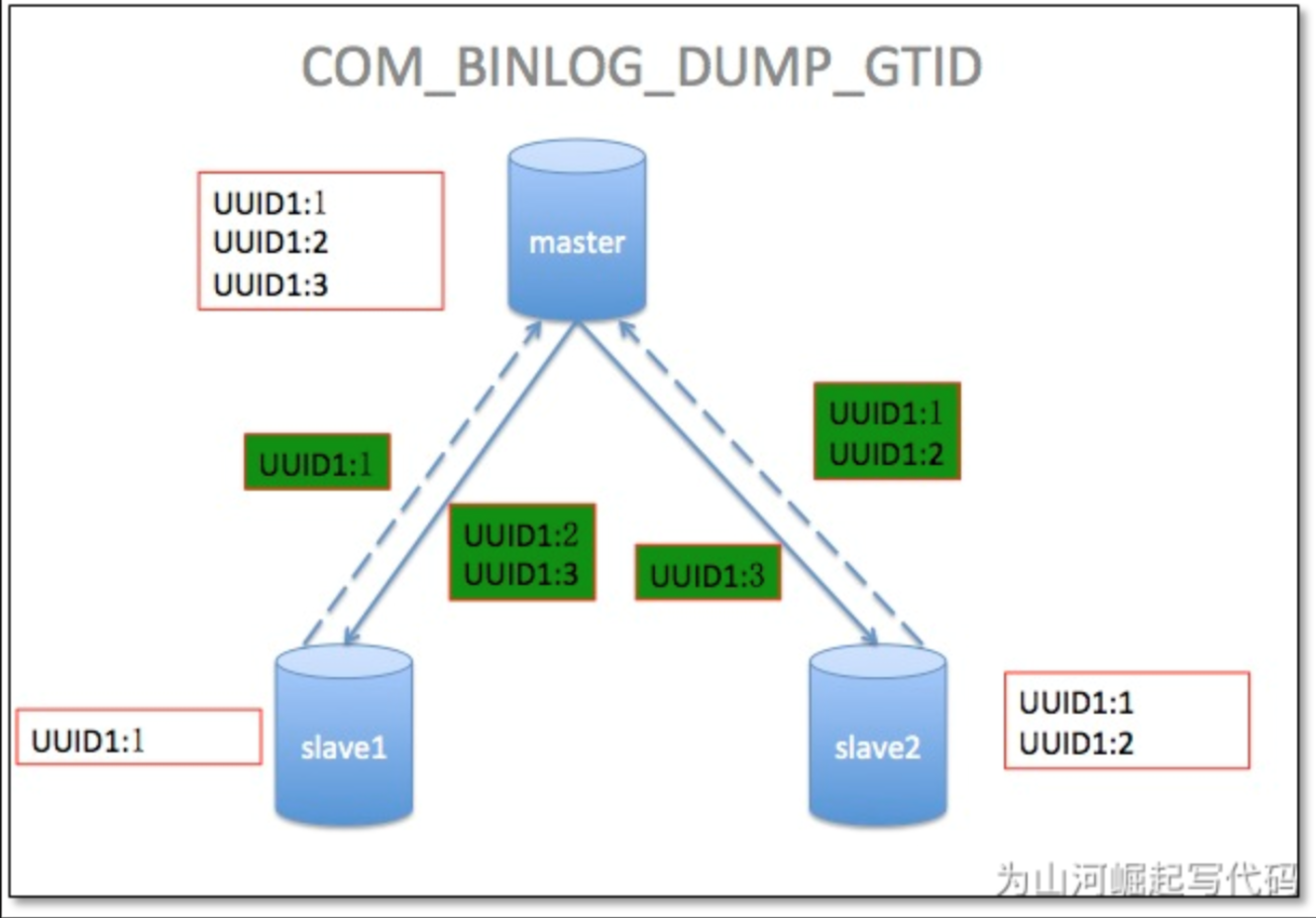
从服务器连接到主服务器之后,把自己执行过的GTID、获取到的GTID发给主服务器,主服务器把从服务器缺少的GTID及对应的transactions发过去补全即可。当主服务器挂掉的时候,找出同步最成功的那台从服务器,直接把它提升为主即可。如果硬要指定某一台不是最新的从服务器提升为主, 先change到同步最成功的那台从服务器, 等把GTID全部补全了,就可以把它提升为主了。
GTID是MySQL 5.6的新特性,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
简而言之,GTID的工作流程为:
-
master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
-
slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
-
sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
-
如果有记录,说明该GTID的事务已经执行,slave会忽略。
-
如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
-
在解析过程中会判断是否有主键,如果没有就用二级索引,如果二级索引没有就用全部扫描。
GTID架构
同样的GTID不能被执行两次,如果有同样的GTID,会自动被skip掉。
GTID的优缺点
GTID的优点
-
一个事务对应一个唯一ID,一个GTID在一个服务器上只会执行一次。
-
GTID是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置。
-
减少手工干预和降低服务故障时间,当主机挂了之后通过软件从众多的备机中提升一台备机为主机。
GTID的缺点(限制)
-
不支持非事务引擎。
-
不支持create table ... select 语句复制(主库直接报错);(原理: 会生成两个sql, 一个是DDL创建表SQL, 一个是insert into 插入数据的sql; 由于DDL会导致自动提交, 所以这个sql至少需要两个GTID, 但是GTID模式下, 只能给这个sql生成一个GTID)。
-
不允许一个SQL同时更新一个事务引擎表和非事务引擎表。
-
在一个复制组中,必须要求统一开启GTID或者是关闭GTID。
-
开启GTID需要重启 (mysql5.7除外)。
-
开启GTID后,就不再使用原来的传统复制方式。
-
对于create temporary table(创建临时表) 和 drop temporary table (删除临时表)语句不支持。
-
不支持sql_slave_skip_counter(跳过错误)。
搭建实验环境
接下来部署MHA,具体的搭建环境如下:
| 机器名称 | IP地址 | 角色 | 备注 |
|---|---|---|---|
| manager | 172.16.16.16 | Manager控制器 | 用于监控管理 |
| master | 172.16.16.9 | 主数据库服务器 | 开启binlog、relay-log,关闭relay_log_purge |
| slave1 | 172.16.16.11 | 从1数据库服务器 | 开启binlog、relay-log,关闭relay_log_purge、设置read_only=1 |
| slave2 | 172.16.16.2 | 从2数据库服务器 | 开启binlog、relay-log,关闭relay_log_purge、设置read_only=1 |
其中master对外提供写服务,备选master提供读服务,slave也提供相关的读服务,一旦master宕机,将会把备选master提升为新的master,slave指向新的master,manager作为管理服务器。
部署基于GTID的主从复制
主库配置
[root@master ~]# cat /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/mysql_data
port=3306
socket=/usr/local/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/tmp/mysqld.pid
# 节点ID,确保唯一
server-id=1
binlog_format=row
log-bin=mysql-bin
skip-name-resolve
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
relay_log_purge=0
sync_binlog=1
expire_logs_days=7
#binlog每个日志文件大小
max_binlog_size=100m
#binlog缓存大小
binlog_cache_size=4m
#最大binlog缓存大小
max_binlog_cache_size=512m
[mysql]
socket=/usr/local/mysql/mysql.sock
[client]
socket=/usr/local/mysql/mysql.sock
从库配置
[mysqld]
basedir=/usr/local/mysql
datadir=/mysql_data
port=3306
socket=/usr/local/mysql/mysql.sock
character-set-server=utf8
log-error=/var/log/mysqld.log
pid-file=/tmp/mysqld.pid
# 中继日志
relay-log=mysql-relay-bin
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%
# 节点ID,确保唯一
server-id=2
binlog_format=row
log-bin=mysql-bin
skip-name-resolve
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
relay_log_purge=0
sync_binlog=1
expire_logs_days=7
#binlog每个日志文件大小
max_binlog_size=100m
#binlog缓存大小
binlog_cache_size=4m
#最大binlog缓存大小
max_binlog_cache_size=512m
[mysql]
socket=/usr/local/mysql/mysql.sock
[client]
socket=/usr/local/mysql/mysql.sock
重新初始化
[root@slave01 ~]# mkdir /mysql_data
[root@slave01 ~]# chmod o+w /var/log
[root@slave01 ~]# mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/mysql_data
[root@slave01 ~]# vim /usr/lib/systemd/system/mysqld.service
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=https://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
[root@slave01 ~]# chown -R mysql.mysql /usr/local/mysql
[root@slave01 ~]# chown -R mysql.mysql /usr/local/mysql-5.7.35-linux-glibc2.12-x86_64/
[root@slave01 ~]# systemctl daemon-reload
[root@slave01 ~]# systemctl start mysqld
[root@slave01 ~]# mysql -uroot -p123456
# 修改密码
mysql> alter user root@localhost identified by 'Test123!';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
增加主从复制用户
-- 主库执行
GRANT REPLICATION SLAVE ON *.* TO shanhe@'%' IDENTIFIED BY '123456';
flush privileges;
-- 从库执行
change master to
master_host='172.16.0.11',
master_user='shanhe',
master_password='123456',
MASTER_AUTO_POSITION=1;
创建MHA管理用户
grant all on *.* to 'mhaadmin'@'%' identified by '123456';
flush privileges;
设置从库可读
#1、在从库上进行操作
#设置只读,不要添加配置文件,因为从库以后可能变成主库
mysql> set global read_only=1;
# 2、查看可读状态
mysql> show global variables like "%read_only%";
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_read_only | OFF |
| read_only | ON |
| super_read_only | OFF |
| transaction_read_only | OFF |
| tx_read_only | OFF |
+-----------------------+-------+
5 rows in set (0.00 sec)
关闭MySQL自动清除relaylog的功能
#2、在所有库上都进行操作(这一步我们在5.3小节已经做过了,此处忽略即可)
#关闭MySQL自动清除relaylog的功能
mysql> set global relay_log_purge = 0;
#编辑配置文件
[root@mysql-db02 ~]# vim /etc/my.cnf
[mysqld]
#禁用自动删除relay log永久生效
relay_log_purge = 0
部署MHA
配置免密登录(所有主机之间互做)
ssh-copy-id
安装依赖包(所有机器执行)
# 安装yum源
wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
rpm -ivh epel-release-latest-7.noarch.rpm
# 安装MHA依赖的perl包
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager
wget https://qiniu.wsfnk.com/mha4mysql-node-0.58-0.el7.centos.noarch.rpm --no-check-certificate
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
然后再去manager主机安装manager包
wget https://qiniu.wsfnk.com/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm --no-check-certificate
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
配置MHA Manager
# 创建工作目录
mkdir -p /service/mha/
mkdir /service/mha/app1
修改配置
vim /service/mha/app1.cnf
[server default]
#日志存放路径
manager_log=/service/mha/manager.log
#定义工作目录位置
manager_workdir=/service/mha/app1
#binlog存放目录(如果三台数据库机器部署的路径不一样,可以将配置写到相应的server下面)
#master_binlog_dir=/usr/local/mysql/data
#设置ssh的登录用户名
ssh_user=root
#如果端口修改不是22的话,需要加参数,不建议改ssh端口
#否则后续如负责VIP漂移的perl脚本也都得改,很麻烦
ssh_port=22
#管理用户
user=mhaadmin
password=123456
#复制用户
repl_user=shanhe
repl_password=123456
#检测主库心跳的间隔时间
ping_interval=1
[server1]
# 指定自己的binlog日志存放目录
master_binlog_dir=/mysql_data/mysql-bin
hostname=172.16.16.9
port=3306
[server2]
#暂时注释掉,先不使用
#candidate_master=1
#check_repl_delay=0
master_binlog_dir=/mysql_data/mysql-bin
hostname=172.16.16.11
port=3306
[server3]
master_binlog_dir=/mysql_data/mysql-bin
hostname=172.16.16.2
port=3306
# 1、设置了以下两个参数,则该从库成为候选主库,优先级最高
# 不管怎样都切到优先级高的主机,一般在主机性能差异的时候用
candidate_master=1
# 不管优先级高的备选库,数据延时多久都要往那切
check_repl_delay=0
# 2、上述两个参数详解如下:
# 设置参数candidate_master=1后,则判断该主机为为候选master,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
# 默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
# 3、应该为什么节点设置这俩参数,从而把该节点的优先级调高
# (1)、多地多中心,设置本地节点为高权重
# (2)、在有半同步复制的环境中,设置半同步复制节点为高权重
# (3)、你觉着哪个机器适合做主节点,配置较高的 、性能较好的
检测mha配置状态
#测试免密连接
1.使用mha命令检测ssh免密登录
masterha_check_ssh --conf=/service/mha/app1.cnf
ALL SSH ... successfilly 表示ok了
2.使用mha命令检测主从状态
masterha_check_repl --conf=/service/mha/app1.cnf
... Health is OK
#如果出现问题,可能是反向解析问题,配置文件加上
skip-name-resolve
#还有可能是主从状态,mha用户密码的情况
启动MHA
nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
命令参数:
--remove_dead_master_conf 该参数代表当发生主从切换后,宕机库的配置信息将会从配置文件中移除。
--manger_log 日志存放位置
--ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录,也就是上面设置的manager_workdir目录中产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为--ignore_last_failover。
#MHA的安全机制:
1.完成一次切换后,会生成一个锁文件在工作目录中
2.下次切换之前,会检测锁文件是否存在
3.如果锁文件存在,8个小时之内不允许第二次切换
主库切换优先级
1.做好主从
2.在主库上创建表
create database if not exists test;
create table test.t1(id int);
3.在主库运行下述脚本
for i in `seq 1 1000000`
do
mysql -e "insert into test.t1 values($i);"
sleep 1
done
4.将某一台从库的IO线程停止,该从库的数据必然落后了
stop slave io_thread;
5.停止主库查看切换情况
肯定不会选择那个停掉io先从的从库当新主库,但是该从库的io线程会
启动起来,然后指向新主库,并且数据更新到了最新
为自动切换主库配置vip漂移脚本
VIP漂移的两种方式
1)通过keepalived的方式,管理虚拟IP的漂移
2)通过MHA自带脚本方式,管理虚拟IP的漂移(推荐)
为了防止脑裂发生,推荐生产环境采用脚本的方式来管理虚拟vip,而不是使用 keepalived来完成。
配置文件中指定脚本路径
[root@mysql-db03 ~]# vim /etc/mha/app1.cnf
[server default]
#指定自动化切换主库后,执行的vip迁移脚本路径
master_ip_failover_script=/service/mha/master_ip_failover

