

Cache性能分析与改进
平均访存时间与程序执行时间
Cache不命中对于一个 CPI较小而时钟频率较高 的CPU来说,影响是双重的
-
每条指令执行所耗周期数越小,周期数固定的不命中开销的相对影响就越大
-
时钟频率较高的CPU的不命中开销较大,其CPI中存储器停顿这部分也就较大
Cache 性能改进
三种类型的不命中 :
-
强制性不命中 : 当第一次访问一个块时,该块不在Cache中。
-
容量不命中 : 如果程序执行时所需的块不能全部调入Cache中,则当某些块被替换后,若又重新被访问
-
冲突不命中 : 在组相联或直接映像Cache中,若太多的块映像到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。
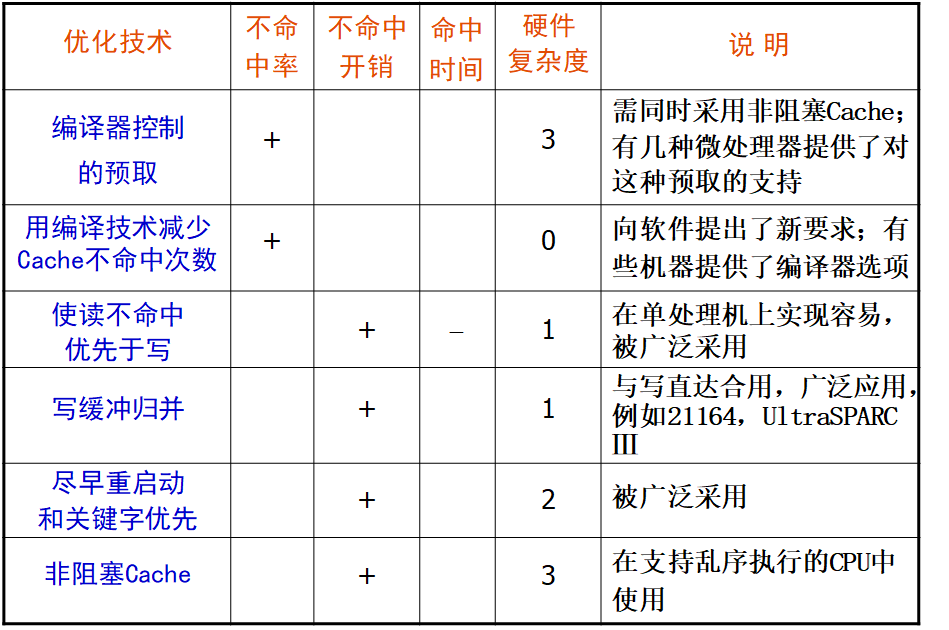
降低不命中率的方法
- 增加块的大小(针对强制不命中)
在增加块大小的过程中,不命中率先下降后上升,下降是因为强制不命中降低(所需要的东西尽量都拿到块里),上升是因为冲突不命中增加(会减小Cache中块的数目)。 此外增加块的大小还会导致不命中开销增加。
- 增加Cache的容量 (针对容量不命中)
会增加成本,并且可能增加命中时间
- 提高相联度 (针对冲突不命中)
提高相联度是以增加命中时间为代价。
- 伪相联 Cache
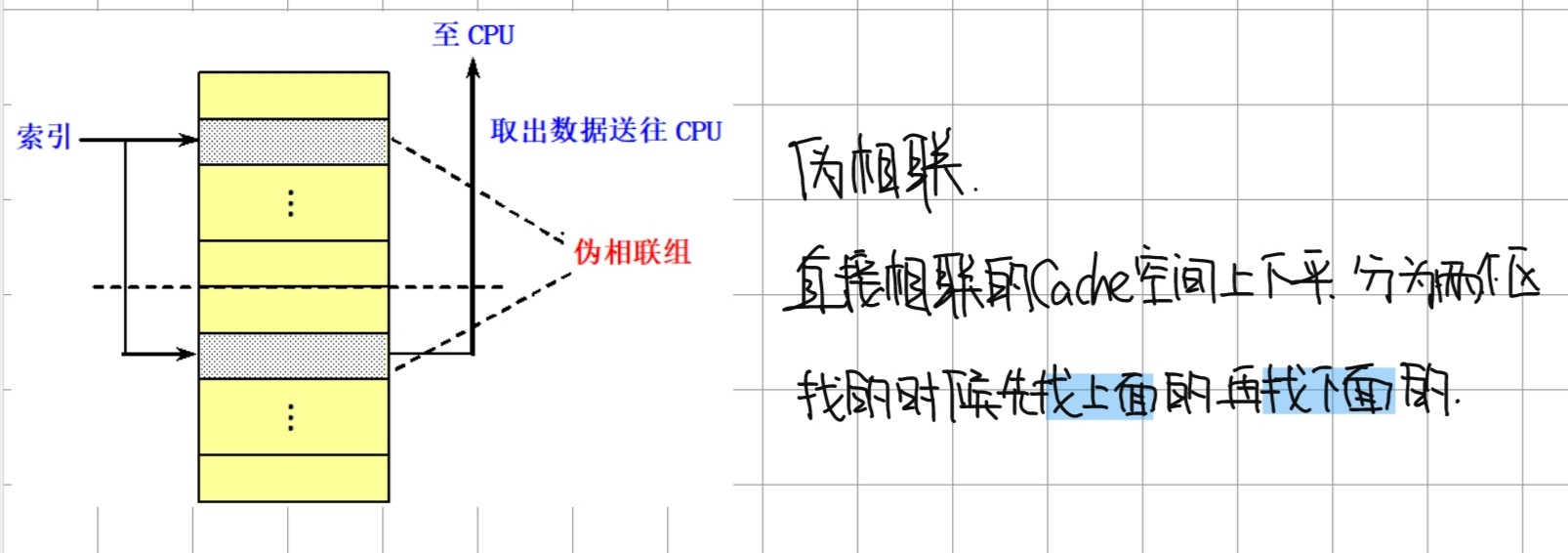
伪相联访存时间的计算公式 :
伪命中率的定义 : 在伪相联中 第一次没有命中但是第二次命中了
-
硬件预取
-
编译器控制的预取
-
编译器优化
基本思想 : 通过对硬件来进行优化,进而降低不命中率,无需对硬件做任何改动
技术包括 :
1) 数组合并 : 将经常一起访问的多个数组合并为一个,以提高访问它们的局部性。
例 : int x[100]; int y[100] => struct merge {int x; int y} Merge[100];
2)内外循环交换 : 提高访问的局部性,数据尽量横向访问,避免纵向访问。
//修改前
for ( j = 0 ; j < 100 ; j = j+1 )
for ( i = 0 ; i < 5000 ; i = i+1 )
x [ i ][ j ] = 2 * x [ i ][ j ];
//修改后
for ( i = 0 ; i < 5000 ; i = i+1 )
for ( j = 0 ; j < 100 ; j = j+1 )
x [ i ][ j ] = 2 * x [ i ][ j ];
3) 循环融合 : 能一个循环解决的尽量不要多些一个
/* 修改前 */
for(j = 0; j < 100; j = j+1 )
x[i][j] = a[i][j] + b[i][j];
for(j = 0; j < 100; j = j+1 )
y[i][j] = a[i][j] - b[i][j];
/* 修改后 */
for(j = 0; j < 100; j = j+1 ){
x[i][j] = a[i][j] + b[i][j];
y[i][j] = a[i][j] - b[i][j];
}
4)分块 : 把对数组的整行或整列访问改为按块进行,尽量集中访问,减少替换,提高访问的局部性
- 牺牲 Cache :
在Cache和它从下一级存储器调数据的通路之间设置一个全相联的小Cache,称为“牺牲”Cache(Victim Cache)。用于存放被替换出去的块(称为牺牲者),以备重用。
降低不命中开销的方法
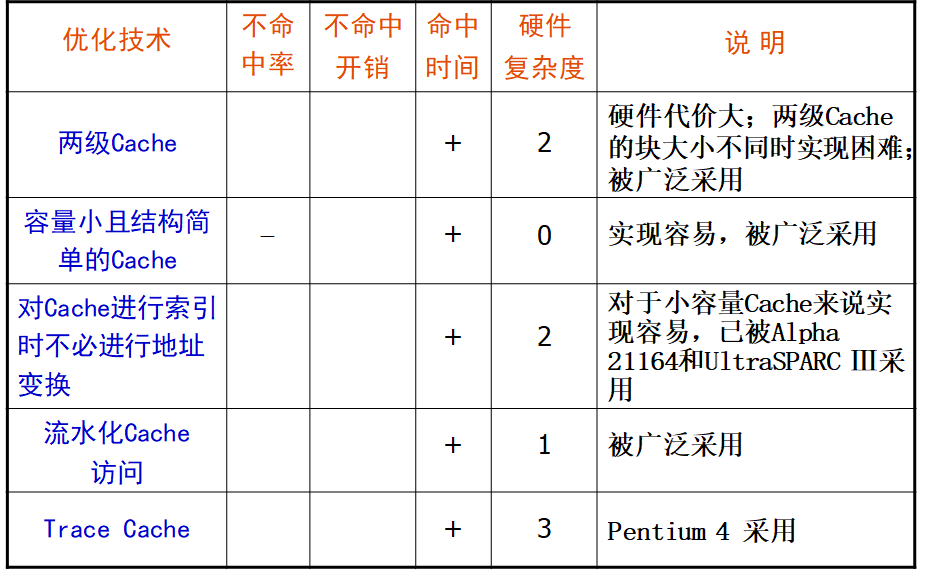
- 二级 Cache : 第一级Cache ( L1 ) 小而快 ; 第二级Cache (L2) 容量大
二级 Cache 计算方法 :
多级包容性 : 第一级Cache中的数据是否总是同时存在于第二级Cache中。如果是,就说第二级Cache是具有多级包容性的。
- 让读不命中优先于写
出现的原因: 在读不命中时,所读单元的最新值有可能还在写缓冲器中,尚未写入主存
解决问题的方法 :
1)推迟对读不命中的处理,直到写缓存器清空。(缺点: 开销增加)
2)检查写缓冲器中的内容,若无相同,且存储器可用,继续处理不命中
- 写缓冲合并:
操作方法:
如果写缓冲器为空,就把数据和相应地址写入该缓冲器。
如果写缓冲器中已经有了待写入的数据,就要把这次的写入地址与写缓冲器中已有的所有地址进行比较,看是否有匹配的项。如果有地址匹配而对应的位置又是空闲的,就把这次要写入的数据与该项合并。(这就是写缓冲合并)
作用:
加速了写操作的速度;提高了写缓冲器的空间利用率,减少因写缓冲器满而要进行的等待时间。
- 请求字处理技术
请求字定义 : 从下一级存储器调入Cache的块中,只有一个字是立即需要的。这个字称为请求字。
具体操作 :
1) 一旦请求字到达,立即送给CPU,让等待的CPU尽早重启动,继续执行。
2)存储器首先提供CPU所要的请求字使CPU启动,同时从存储器调入该块的其余部分。
当Cache块较小 或 下一条指令正好访问同一Cache块的另一部分的时候,是否使用差别不大
- 非阻塞Cache技术
采用记分牌或者Tomasulo类控制方式,允许指令乱序执行,CPU无需在Cache不命中时停顿
减少命中时间的方法
-
使用小容量、结构简单的Cache
-
虚拟Cache
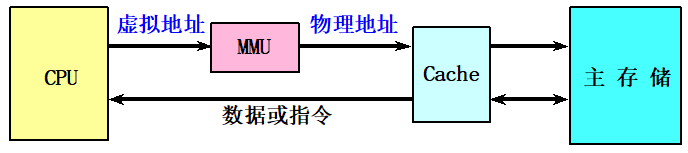
传统的物理Cache :
物理地址进行访问 、 标识存储器中存放的是物理地址,进行地址检测也是用物理地址
缺点 : 地址转换和访问Cache串行进行,访问速度很慢
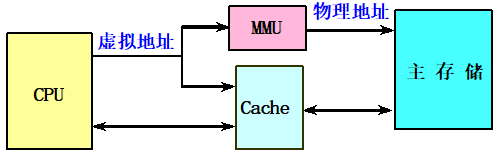
牛逼的虚拟Cache :
直接用虚拟地址进行访问、标识存储器中存放的是虚拟地址,进行地址检测用的也是虚拟地址
优点: 在命中时不需要地址转换、即使不命中,地址转换和访问Cache也是并行进行的,其速度比物理Cache快很多。
但是,采用虚拟Cache也有着如下的缺点:
1)新的进程的虚拟地址可能与原进程相同,故Cache需要清空。
解决方法: 在地址标识中增加PID(进程标识符)字段
2)添加 PID 后的问题 : PID可能被重复使用,所以 Cache 还是会有需要清空的问题。
虚实结合的Cache :
虚拟索引 + 物理标识
- 原理 : 使用虚地址中的页内位移生成Cache索引;虚实转换后的实页地址作为标志tag
2)优点 : 兼得虚拟Cache和物理Cache的好处
3)局限性 : Cache容量受到限制 => Cache容量 ≤ 页大小 × 相联度
- Cache访问流水化
对第一级Cache的访问按流水方式组织
- 踪迹Cache
总结



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具