RocketMQ存储机制与确认重传机制
引子
消息队列之前就听说过,但一直没有学习和接触,直到最近的工作流引擎项目用到,需要了解学习一下。本文主要从一个初学者的角度针对RocketMQ的存储机制和确认重传机制做一个浅显的总结。
存储机制
我们知道,Broker(消息服务器)是消息存储中心,主要作用是接收来自 Producer 的消息并存储, Consumer 从这里取得消息。因此,RocketMQ的所有消息数据都是存放在Broker上的,我们先看看RocketMQ官方文档中的Broker消息存储架构图,然后再来详细讲解。

CommitLog、ConsumeQueue、IndexFile
CommitLog:消息存放的物理文件,是消息主体以及元数据的存储主体。每台broker上的commitlog被本机所有的queue共享,不做任何区分。用于存储Producer端写入的消息主体内容,消息内容不是定长的,文件顺序写,随机读。单个文件大小默认1G ,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件;如下为Commit Log存储单元结构图

ConsumeQueue:ConsumeQueue是消息的逻辑消费队列,相当于字典的目录引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的,Consumer即可根据ConsumeQueue来查找待消费的消息。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构,每个topic下的每个queue都有一个对应的consumequeue文件,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。
consumequeue文件存储单元格式:
- CommitLogOffset:是指这条消息在Commit Log文件中的起始物理偏移量。
- msgSize:存储中消息的大小。
- tagsCode:消息Tag的HashCode值。主要用于订阅时消息过滤(订阅时如果指定了Tag,会根据HashCode来快速查找到订阅的消息)。
同样consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M;
我们来看一看具体的存储文件是怎么样的

如上图所示:
- 根据topic和queueId来组织文件,图中TopicA有两个队列0,1,那么TopicA和QueueId=0组成一个ConsumeQueue,TopicA和QueueId=1组成另一个ConsumeQueue。
- 按照消费端的GroupName来分组重试队列,如果消费端消费失败,消息将被发往重试队列中,比如图中的%RETRY%ConsumerGroupA。
- 按照消费端的GroupName来分组死信队列,如果消费端消费失败,并重试指定次数后,仍然失败,则发往死信队列,比如图中的%DLQ%ConsumerGroupA。(死信队列(Dead Letter Queue)一般用于存放由于某种原因无法传递的消息,比如处理失败或者已经过期的消息。)
IndexFile:IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法,如果一个消息包含key值的话,会使用IndexFile存储消息索引。Index文件的存储位置是:$HOME \store\index${fileName},文件名fileName是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引,IndexFile的底层存储设计为在文件系统中实现HashMap结构,故rocketmq的索引文件其底层实现为hash索引。如下图所示为IndexFile文件结构:
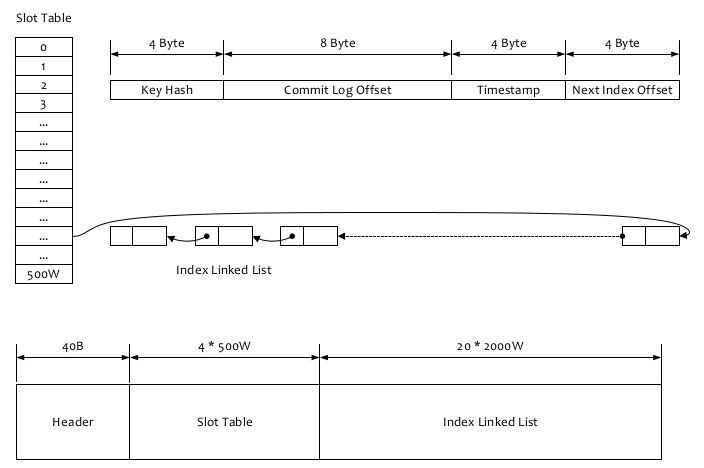
索引文件根据key查找对应消息主要流程:
- 根据查询的 key 的 hashcode%slotNum 得到具体的槽的位置(slotNum 是一个索引文件里面包含的最大槽的数目,例如图中所示 slotNum=5000000)
- 根据 slotValue(slot 位置对应的值)查找到索引项列表的最后一项(倒序排列,slotValue 总是指向最新的一个索引项)
- 遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的 32 条记录)
混合型存储结构
在上面的RocketMQ的消息存储整体架构图中可以看出,RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储。RocketMQ的混合型存储结构(多个Topic的消息实体内容都存储于一个CommitLog中)针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构,Producer发送消息至Broker端,然后Broker端使用同步或者异步的方式对消息刷盘持久化,保存至CommitLog中。只要消息被刷盘持久化至磁盘文件CommitLog中,那么Producer发送的消息就不会丢失。正因为如此,Consumer也就肯定有机会去消费这条消息。当无法拉取到消息后,可以等下一次消息拉取,同时服务端也支持长轮询模式,如果一个消息拉取请求未拉取到消息,Broker允许等待30s的时间,只要这段时间内有新消息到达,将直接返回给消费端。这里,RocketMQ的具体做法是,使用Broker端的后台服务线程—ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据。(引自RocketMQ官方文档)
以上便是RocketMQ的存储机制,看到这,有的读者可能会问到,架构图中的ConsumeOffset,minOffSet这些参数是干什么的你还没有说呢?别急,我们今天要讨论的不光是存储机制,还有确认重传机制。
消息ACK机制及消费进度管理
关于ACK和确保消费成功相关内容,我们只讨论RocketMQ中的PushConsumer即Java客户端中的DefaultPushConsumer,因为若要使用PullConsumer模式,类似的工作如何ack,如何保证消费等均需要使用方自己实现。
如何确保消费成功
PushConsumer为了保证消息肯定消费成功,只有使用方明确表示消费成功,RocketMQ才会认为消息消费成功。中途断电,抛出异常等都不会认为成功——即都会重新投递。首先,消费的时候,我们需要注入一个消费回调,具体sample代码如下:
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);
doMyJob();//执行真正消费
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;//返回消费成功
}
});
业务实现消费回调的时候,当且仅当此回调函数返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS,RocketMQ才会认为这批消息(默认是1条)是消费完成的。(具体如何ACK见后)
如果这时候消息消费失败,例如数据库异常,余额不足扣款失败等一切业务认为消息需要重试的场景,只要返回ConsumeConcurrentlyStatus.RECONSUME_LATER,RocketMQ就会认为这批消息消费失败了。
为了保证消息是肯定被至少消费成功一次,RocketMQ会把这批消费失败的消息重发回Broker(topic不是原topic而是这个消费租的RETRY topic),在延迟的某个时间点(默认是10秒,业务可设置)后,再次投递到这个ConsumerGroup。而如果一直这样重复消费都持续失败到一定次数(默认16次),就会投递到DLQ死信队列。应用可以监控死信队列来做人工干预。
启动的时候从哪里消费
当新实例启动的时候,PushConsumer会拿到本消费组broker已经记录好的消费进度(consumer offset,见存储架构图),按照这个进度发起自己的第一次Pull请求。
如果这个消费进度在Broker并没有存储起来,证明这个是一个全新的消费组,这时候客户端有几个策略可以选择:
CONSUME_FROM_LAST_OFFSET //默认策略,从该队列最尾开始消费,即跳过历史消息
CONSUME_FROM_FIRST_OFFSET //从队列最开始开始消费,即历史消息(还储存在broker的)全部消费一遍
CONSUME_FROM_TIMESTAMP//从某个时间点开始消费,和setConsumeTimestamp()配合使用,默认是半个小时以前
消息ACK机制
RocketMQ是以consumer group+queue为单位是管理消费进度的,以一个consumer offset标记这个这个消费组在这条queue上的消费进度。如果某已存在的消费组出现了新消费实例的时候,依靠这个组的消费进度,就可以判断第一次是从哪里开始拉取的。
每次消息成功后,本地的消费进度会被更新,然后由定时器定时同步到broker,以此持久化消费进度。但是每次记录消费进度的时候,只会把一批消息中最小的offset值为消费进度值,如下图:
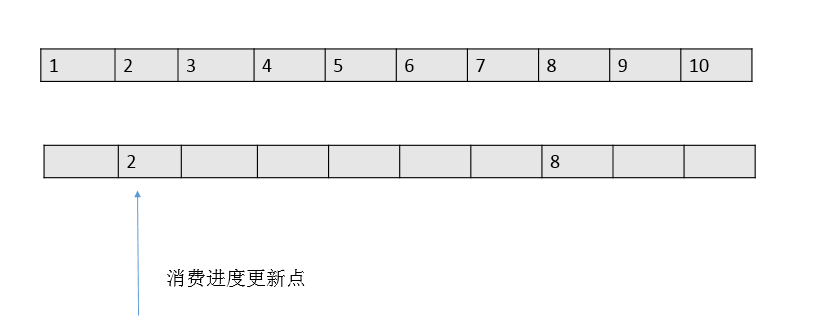
这钟方式和传统的一条message单独ack的方式有本质的区别。性能上提升的同时,会带来一个潜在的重复问题——由于消费进度只是记录了一个下标,就可能出现拉取了100条消息如 2101-2200的消息,后面99条都消费结束了,只有2101消费一直没有结束的情况。
在这种情况下,RocketMQ为了保证消息肯定被消费成功,消费进度职能维持在2101,直到2101也消费结束了,本地的消费进度才能标记2200消费结束了(注:consumerOffset=2201)。
在这种设计下,就有消费大量重复的风险。如2101在还没有消费完成的时候消费实例突然退出(机器断电,或者被kill)。这条queue的消费进度还是维持在2101,当queue重新分配给新的实例的时候,新的实例从broker上拿到的消费进度还是维持在2101,这时候就会又从2101开始消费,2102-2200这批消息实际上已经被消费过还是会投递一次。
对于这个场景,RocketMQ暂时无能为力,所以业务必须要保证消息消费的幂等性,这也是RocketMQ官方多次强调的态度。
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号