
Presto 安装部署
1.版本选型
hadoop-3.1.3
hive-3.1.2
presto-0.233.1
2.Presto 简介
详细参考:https://prestodb.github.io/docs/current/connector.html
2.1 Presto 优势
多数据源,支持SQL,自定义扩展Connector
混合计算(同一种数据源的不同库 or表;将多个数据源的数据进行合并)
低延迟,高并发,纯内存计算引擎,高性能
2.2 Presto 架构
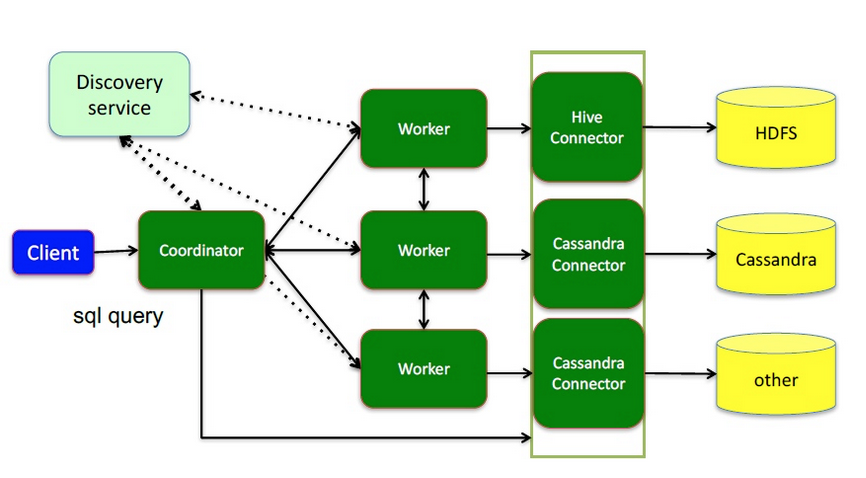
# presto提供插件化的connector来支持外部数据查询,原生支持hive、cassandra、elasticsearch、kafka、kudu、mongodb、mysql、redis等众多外部数据源;
1.coordinator(master):负责meta管理,worker管理;接收查询请求,解析SQL生成执行计划
2.worker:执行任务的节点,负责计算和读写
3.connector:连接器(Hadoop相关组件的连接器,RDBMS连接器)
4.discovery service:内嵌在coordinator节点中,也可以单独部署,用于节点心跳;worker节点启动后向discovery service服务注册,coordinator通过discovery service获取注册的worker节点
2.3 Presto数据模型
presto采取三层表结构:
catalog 对应某一类数据源,例如hive的数据,或mysql的数据
schema 对应mysql中的数据库
table 对应mysql中的表
2.4 Presto 执行过程
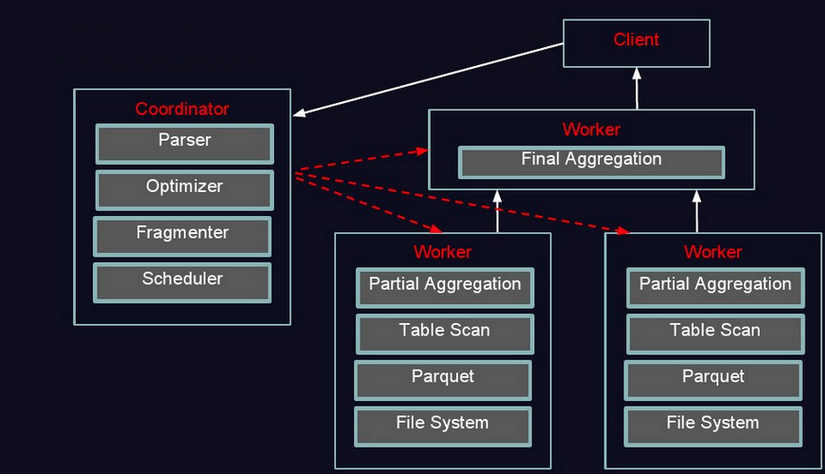
1、coordinator接到SQL后,通过SQL语法解析器把SQL语法解析变成一个抽象的语法树AST(描述最原始的用户需求),只是进行语法解析如果有错误此环节暴露
2、语法符合SQL语法,会经过一个逻辑查询计划器组件,通过connector 查询metadata中schema 列名 列类型等,将之与抽象语法数对应起来,生成一个物理的语法树节点 如果有类型错误会在此步报错
3、如果通过,会得到一个逻辑的查询计划,将其分发到分布式的逻辑计划器里,进行分布式解析,最后转化为一个个task
4、在每个task里面,会将位置信息解析出来,交给执行的plan,由plan将task分给worker执行
3.Presto 安装
client:https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223.1/presto-cli-0.223.1.jar
3.1 安装
#server
tar -zxvf /opt/software/presto/presto-server-0.233.1.tar.gz -C /opt/module/presto-0.233.1/
#1.把 presto-cli-0.223.1.jar 复制到 /opt/module/presto-0.233.1/presto-server-0.233.1/bin 目录下
cp /opt/software/presto/presto-cli-0.223.1.jar /opt/module/presto-0.233.1/presto-server-0.233.1/bin
#2.presto-cli-0.223.1.jar 重命名 presto
mv /opt/module/presto-0.233.1/presto-server-0.233.1/bin/presto-cli-0.223.1.jar /opt/module/presto-0.233.1/presto-server-0.233.1/bin/presto
#3.增加 presto 的执行权限
chmod +x /opt/module/presto-0.233.1/presto-server-0.233.1/bin/presto
3.2 配置 Presto
1.配置数据目录
#最好安装在 presto server 安装目录外
mkdir /opt/module/presto-0.233.1/data
2.创建配置文件
#1.在 presto server 安装目录 /opt/module/presto-0.233.1/presto-server-0.233.1 创建 etc 文件夹
mkdir /opt/module/presto-0.233.1/presto-server-0.233.1/etc
#2.在 /opt/module/presto-0.233.1/presto-server-0.233.1/etc 下创建 config.properties,jvm.properties,node.properties,log.properties 文件
vim config.properties
coordinator=true #work节点需要填写false
node-scheduler.include-coordinator=false #是否允许在coordinator上调度节点只负责调度时node-scheduler.include-coordinator设置为false,调度节点也作为worker时node-scheduler.include-coordinator设置为true
http-server.http.port=8085
query.max-memory=1GB
query.max-memory-per-node=512MB
query.max-total-memory-per-node=512MB
discovery-server.enabled=true #Presto 通过Discovery 服务来找到集群中所有的节点,每一个Presto实例都会在启动的时候将自己注册到discovery服务; 注意:worker 节点不需要配 discovery-server.enabled
discovery.uri=http://hadoop101:8085 #Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery 服务,因此这个uri就是Presto coordinator的uri
vim jvm.config (Presto集群coordinator和worker的JVM配置是一致的)
-server
-Xmx2G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff01 #每个节点需要不同
node.data-dir=/opt/module/presto-0.233.1/data
vim log.properties
com.facebook.presto=DEBUG
3.3 配置 connector
#1.在 /opt/module/presto-0.233.1/presto-server-0.233.1/etc 创建 catalog 目录
mkdir /opt/module/presto-0.233.1/presto-server-0.233.1/etc/catalog
#2.在 catalog 目录下 创建 hive connector
vim hive.properties
connector.name=hive-hadoop2 #注意 connector.name 只能是 hive-hadoop2
hive.metastore.uri=thrift://hadoop101:9083
hive.config.resources=/etc/hadoop/core-site.xml,/etc/hadoop/hdfs-site.xml
#3.在 catalog 目录下 创建 mysql connector
vim mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://hadoop101:3306
connection-user=root
connection-password=123456
4.启动 presto
注意:Presto requires Java 8u151+,需要jdk 1.8.151 以上,否则 PrestoServer 进程会自动死亡
#后台启动 (日志在 数据目录 /opt/module/presto-0.233.1/data/var/log)
/opt/module/presto-0.233.1/presto-server-0.233.1/bin/launcher start
#调试启动
/opt/module/presto-0.233.1/presto-server-0.233.1/bin/launcher --verbose run
4。1 访问 presto webui http://hadoop101:8085
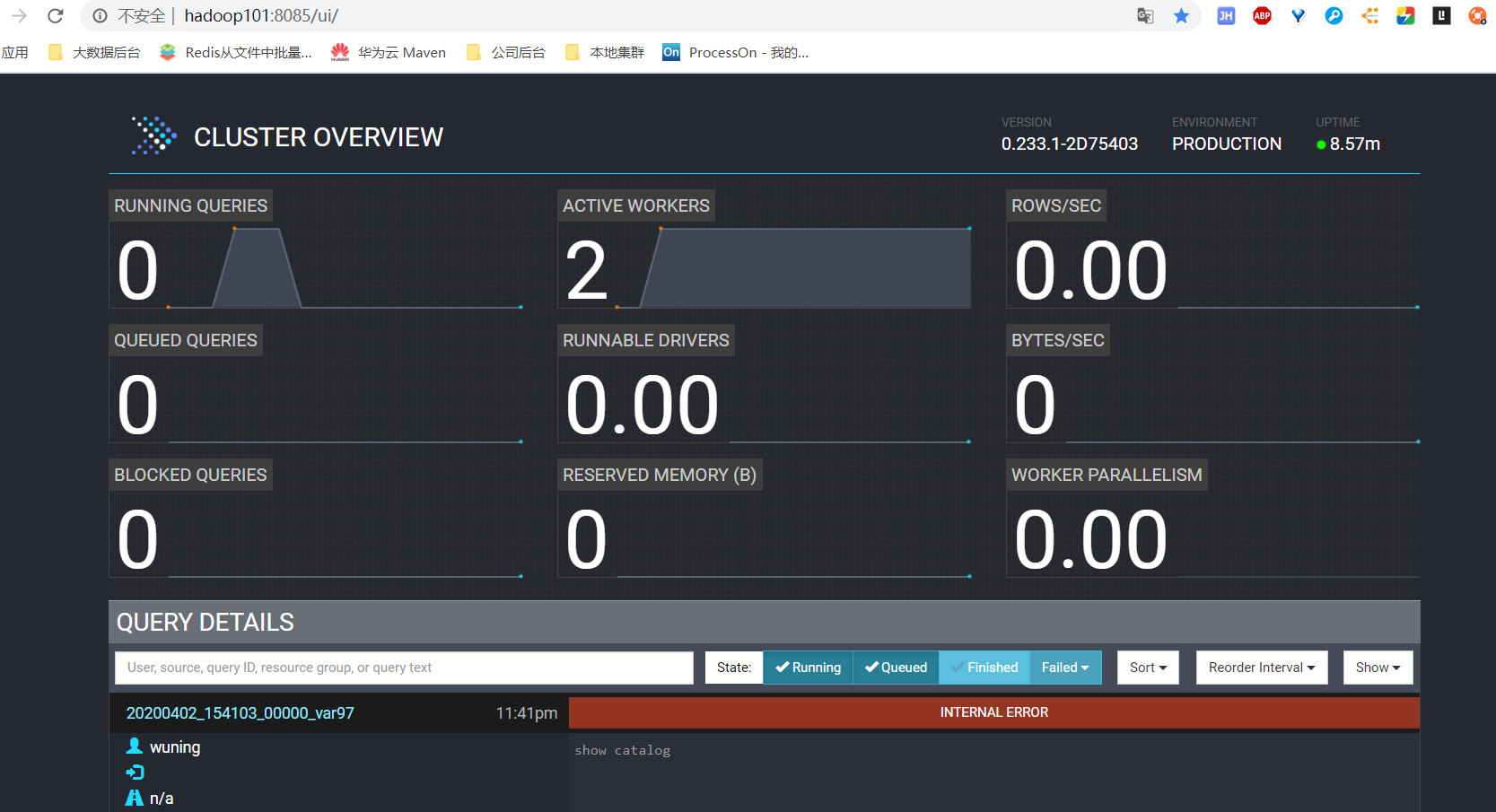
5.测试
5.1 启动 presto cli
#在 presto server 安装目录下执行
./bin/presto --server hadoop101:8085
# 查看连接的数据源
show catalogs;
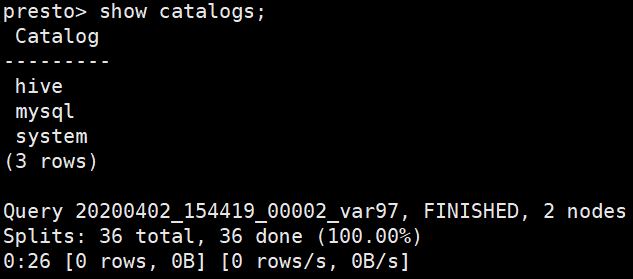
#查看 mysql 中的库
show schemas from mysql;
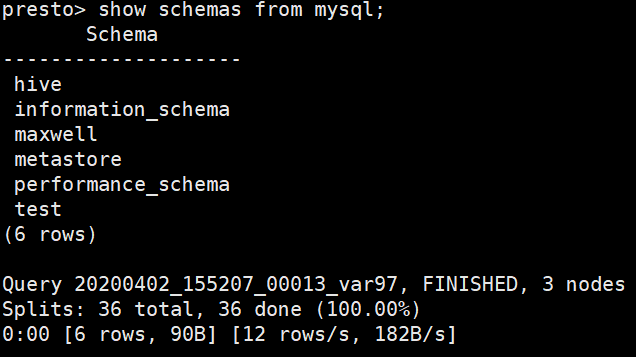
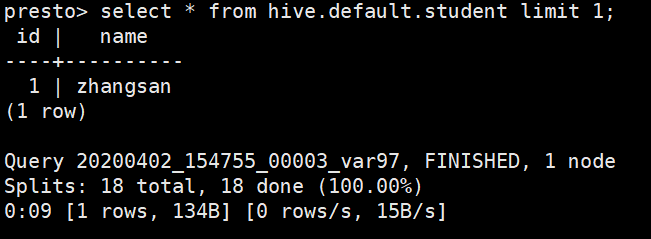
#查询 Hive
select * from hive.default.student limit 1;
#查询 mysql
select * from mysql.test.maxwell_test limit 1;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号