
基于MaxWell 实时同步 MySQL 日志 binlog 到 Kafka
1.项目背景
1.1 MaxWell 介绍
Maxwell是一个守护进程,它能监听并读取MySQL的binlog,然后解析输出为json,支持将数据输出到Kafka、Kinesis或其他流媒体平台,支持库和表的过滤。
地址:https://github.com/zendesk/maxwell
1.2 版本选型
maxwell-1.25.0
2.配置MySql
需要打开MySql的 binlog(默认是关闭),采用 row-based replication(RBR) 日志格式
binlog有三种格式:Statement、Row以及Mixed
–基于SQL语句的复制(statement-based replication,SBR)
–基于行的复制(row-based replication,RBR)
–混合模式复制(mixed-based replication,MBR)
STATMENT模式:每一条会修改数据的sql语句会记录到binlog中
ROW模式:不记录sql语句上下文相关信息,仅保存哪条记录被修改
Mixed模式:从5.1.8版本开始,MySQL提供了Mixed格式,实际上就是Statement与Row的结合
2.1 创建my.cnf
cp /usr/share/mysql/my-default.cnf /etc/my.cnf
#my.cnf
[mysqld]
server_id=1 # 随机指定
log-bin=master
binlog_format=row #选择 Row 模式
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
2.2 启动Mysql
mysql> set global binlog_format=ROW;
mysql> set global binlog_row_image=FULL;
2.3 配置 Maxwell库 及 相关权限
Maxwell需要连接MySQL,并创建一个名称为maxwell的数据库存储元数据,且需要能访问需要同步的数据库,新创建一个MySQL用户专门用来给Maxwell使用
注意:MaxWell 在启启动时会自动创建 maxwell 库
添加权限:
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
mysql> flush privileges;
2.4 重启Mysql
service mysql restart
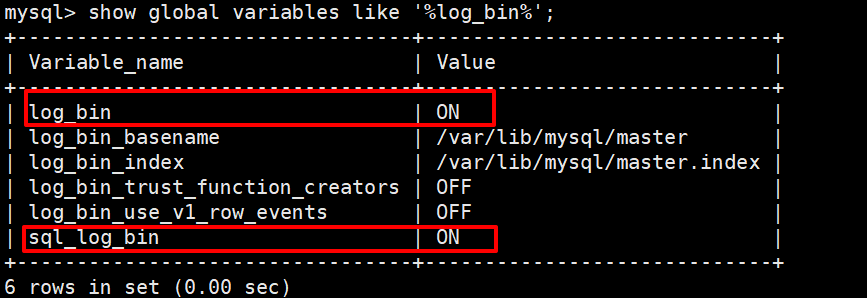
#查看 binlog 相关配置
show global variables like '%log_bin%'
#查看详细的日志配置信息SHOW GLOBAL VARIABLES LIKE '%log%';
#mysql数据存储目录 show variables like '%dir%';
3.安装MaxWell
tar /opt/software/maxwell-1.25.0.tar.gz -C /opt/module
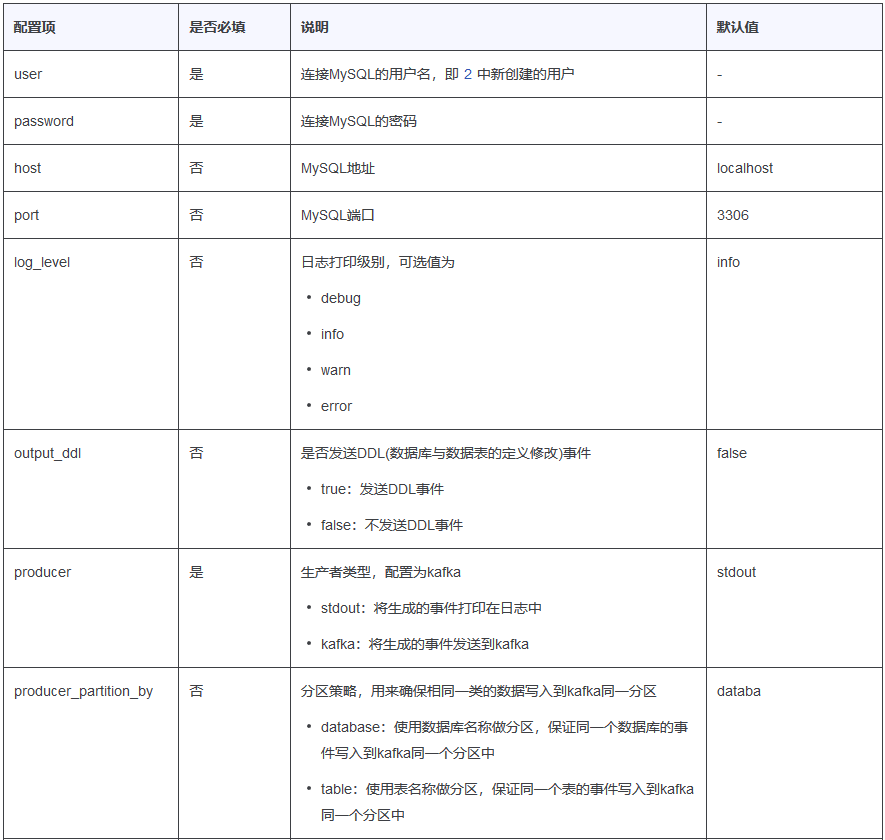
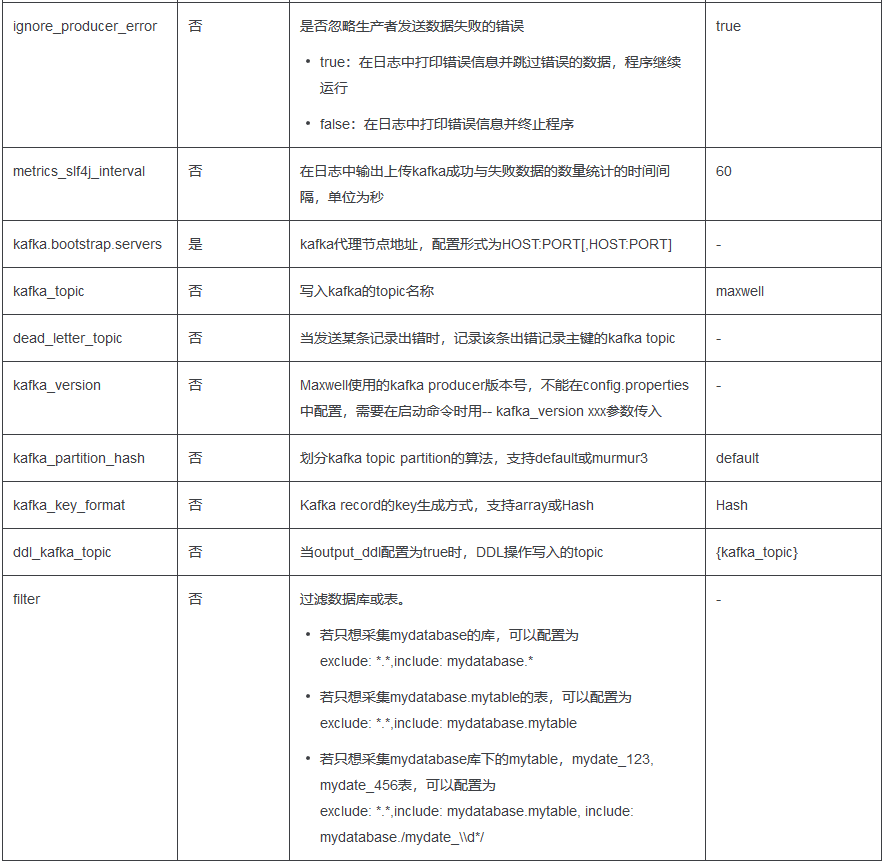
3.1 MaxWell 配置参数
3.2 启动MaxWell(kafka 方式)
#创建 kafka topic maxwell
kafka-topics.sh --zookeeper hadoop101:2181/kafka --create --replication-factor 1 --partitions 1 --topic maxwell
#启动MaxWell
/opt/module/maxwell-1.25.0/bin/maxwell --user='maxwell' --password='123456' --host='hadoop101' --producer=kafka --kafka.bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092 --kafka_topic=maxwell

4.测试
4.1 创建测试数据
#mysql中创建测试表
create table test.maxwell_test(id int,name varchar(100));
#向maxwell_test插入数据
INSERT into maxwell_test values(1,'aa');
INSERT into maxwell_test values(2,'bb');
INSERT into maxwell_test values(3,'cc');
INSERT into maxwell_test values(4,'dd');
INSERT into maxwell_test values(5,'ee');
4.2 消费kafka中数据
package com.monk.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Collections;
import java.util.Properties;
/**
* @ClassName KafkaConsumerMaxWell
* @Author wuning
* @Date: 2020/4/02 21:46
* @Description:
*/
public class KafkaConsumerMaxWell implements Runnable {
private String topic;
private KafkaConsumer<Integer,String> kafkaConsumer;
public KafkaConsumerMaxWell(String topic, String bootstrap, String groupId) {
this.topic = topic;
Properties props = new Properties();
props.put("bootstrap.servers", bootstrap);
//消费者组ID
props.put("group.id", groupId);
//设置自动提交offset
props.put("enable.auto.commit", "true");
//设置自动提交offset的延时(可能会造成重复消费的情况)
props.put("auto.commit.interval.ms", "1000");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//key-value的反序列化
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaConsumer = new KafkaConsumer<Integer, String>(props);
}
@Override
public void run() {
kafkaConsumer.subscribe((Collections.singletonList(topic)));
while(true){
ConsumerRecords<Integer,String> records = kafkaConsumer.poll(100);
for (ConsumerRecord record:records) {
System.out.println(record.value());
}
}
}
public static void main(String[] args) {
KafkaConsumerMaxWell kafkaConsumerMaxWell =
new KafkaConsumerMaxWell("maxwell", "hadoop101:9092,hadoop102:9092,hadoop103:9092", "g1");
new Thread(kafkaConsumerMaxWell).start();
}
}

Maxwell生成的数据格式为JSON,常见字段含义如下:
type:操作类型,包含database-create,database-drop,table-create,table-drop,table-alter,insert,update,delete
database:操作的数据库名称
ts:操作时间,13位时间戳
table:操作的表名
data:数据增加/删除/修改之后的内容
old:数据修改前的内容或者表修改前的结构定义
sql:DDL操作的SQL语句
def:表创建与表修改的结构定义
xid:事物唯一ID
commit:数据增加/删除/修改操作是否已提交

 浙公网安备 33010602011771号
浙公网安备 33010602011771号