
《30天自制操作系统》实现中文显示
《30天自制操作系统》最近一直再看,最近已经看到后面了,看到第28天,里面讲到可以实现对全角字符的支持,而原操作系统代码里面只是支持了日语显示,而中文版的这本书也只是讲了一个思路,具体的实现也是没有的。网上也好像没有人实现过这个吧,我是找不到。(由于书中每一章每一小节都有代码,我看书的时候就懒得去实际写代码,就简单看看。不过这次就可以写一下了,加深对这个系统的了解)反正没事做,就准备实现对这个系统的汉字全角支持。
一、了解HZK编码
在改造之前,我们先了解一下符合GB2312标准的中文点阵字库文件的HZK16。百度搜索HZK16第一个那个百度百科连接就是了。
HZK16字库是符合GB2312标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个。其中一级汉字有3755个,按声序排列,二级汉字有3008个,按偏旁部首排列。我们在一些应用场合根本用不到这么多汉字字模,所以在应用时就可以只提取部分字体作为己用。
HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。
我们知道一个GB2312汉字是由两个字节编码的,范围为A1A1~FEFE。A1-A9为符号区,B0到F7为汉字区。每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域)。下面以汉字“我”为例,介绍如何在HZK16文件中找到它对应的32个字节的字模数据。
前面说到一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的位号。其中,每个区记录94个汉字,位号为该字在该区中的位置。
区码和区号,其实是一个东西
区码:区号(汉字的第一个字节)- 0xa0 (因为汉字编码是从0xa0区开始的,所以文件最前面就是从0xa0区开始,要算出相对区码)
位码:位号(汉字的第二个字节)- 0xa0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:
offset=(94*(区码-1)+(位码-1))*32
注解: 1、区码减1是因为数组是以0为开始而区号位号是以1为开始的
2、(94*(区号-1)+位号-1)是一个汉字字模占用的字节数
3、最后乘以32是因为汉字库文应从该位置起的32字节信息记录该字的字模信息(前面提到一个汉字要有32个字节显示)
二、添加代码
首先查看一下c语言里面的中文编码是否真的跟书上讲的是否一样。我们先修改iroha/iroha.c这个文件,代码如下


1 #include "apilib.h" 2 #include <stdio.h> 3 4 void HariMain(void) 5 { 6 static char s[9] = { 0xb2, 0xdb, 0xca, 0xc6, 0xce, 0xcd, 0xc4, 0x0a, 0x00 }; 7 char ch[10]; 8 char str[100]="我 啊\n"; 9 int i,j; 10 api_putstr0(s); 11 sprintf(ch,"%x %x %x %x\n",s[0],s[1],s[2],s[3]); 12 api_putstr0(ch); 13 sprintf(ch,"%x %x %x %x %x %x\n",str[0],str[1],str[2],str[3],str[4],str[5],str[6],str[7]); 14 api_putstr0(ch); 15 api_putstr0(str); 16 api_putstr0("4"); 17 18 api_end(); 19 }
运行的结果为
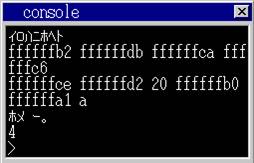
可以看出0xce 0xd2 0x20 0xb0 0xa1 0x0a 分别表示0x20是空格 0x0a是回车,看来我当前系统windows7下的作者默认编译器,编译的结构是符合EUC方式。我们就可以继续了。我们以harib26a这个进行改造。
首先我们下载一个HZK16的字库文件放到nihongo/HZK16.fnt,修改所有makefile文件harib26/Makefile和harib26/app_make.txt.更改这两个文件里面的nihongo.fnt为HZK16.fnt.
接着修改haribote/bootpack.c里面约109行处修改所载入库文件的大小,由于日文的nihongo.fnt比HZK16.fnt小所以要改大一点。至于多大,一般想法是右键属性查看HZK16的文件大小,不过我是写上
nihongo = (unsigned char *) memman_alloc_4k(memman, 0x5d5d*32);
因为0XFEFE-0XA1A1=0X5D5D.
往下三行,修改做载入字库文件的文件名
finfo = file_search("HZK16.fnt", (struct FILEINFO *) (ADR_DISKIMG + 0x002600), 224);
由于我们是增加汉字的支持所以我想定义task->langmode=3为汉字。我们在haribot/console.c约39行处加上一句task->langmode=3表示汉字。使每次都选择汉字。
接下来就是输出了,这次是在haribote/graphic.c约168行处增加下面一段代码
1 if (task->langmode == 3) { 2 for (; *s != 0x00; s++) { 3 if (task->langbyte1 == 0) { 4 if (0xa1 <= *s && *s <= 0xfe) { 5 task->langbyte1 = *s; 6 } else { 7 putfont8(vram, xsize, x, y, c, nihongo + *s * 16); 8 } 9 } else { 10 k = task->langbyte1 - 0xa1; 11 t = *s - 0xa1; 12 task->langbyte1 = 0; 13 font = nihongo + 256 * 16 + (k * 94 + t) * 32; 14 putfont8(vram, xsize, x - 8, y, c, font ); 15 putfont8(vram, xsize, x , y, c, font + 16); 16 } 17 x += 8; 18 } 19 }
增加一个可以查看效果的程序,我们以chklang/chklang.c这个小程序为例吧。
1 #include "apilib.h" 2 3 void HariMain(void) 4 { 5 int langmode = api_getlang(); 6 static char s1[23] = { 7 0x93, 0xfa, 0x96, 0x7b, 0x8c, 0xea, 0x83, 0x56, 0x83, 0x74, 0x83, 0x67, 8 0x4a, 0x49, 0x53, 0x83, 0x82, 0x81, 0x5b, 0x83, 0x68, 0x0a, 0x00 9 }; 10 static char s2[17] = { 11 0xc6, 0xfc, 0xcb, 0xdc, 0xb8, 0xec, 0x45, 0x55, 0x43, 0xa5, 0xe2, 0xa1, 12 0xbc, 0xa5, 0xc9, 0x0a, 0x00 13 }; 14 static char s3[20] = { 15 0xce, 0xd2, 0x20, 0xca, 0xc7, 0xa1, 0xa2, 0xa1, 0xa3, 0x0a, 0x00 16 }; 17 int i;char j; 18 if (langmode == 0) { 19 api_putstr0("English ASCII mode\n"); 20 } 21 if (langmode == 1) { 22 api_putstr0(s1); 23 } 24 if (langmode == 2) { 25 api_putstr0(s2); 26 } 27 if (langmode == 3) {//增加这个表示对汉字的支持 28 api_putstr0("Chinese 中文! 我 !\n"); 29 api_putstr0("博客园 www.cnblogs.com/wunaozai \n"); 30 api_putstr0("无脑仔的小明"); 31 api_putstr0(s3); 32 for(i=0xa1;i<0xcc;i++) 33 { 34 s3[0]=0xa1; 35 j=i; 36 s3[1]=j; 37 s3[2]=0x00; 38 api_putstr0(s3); 39 } 40 } 41 api_end(); 42 }
大概就修改这些了吧,根据书中这样修改,好像也不是很难嘛。好了我们make run一下。结果竟然是?????
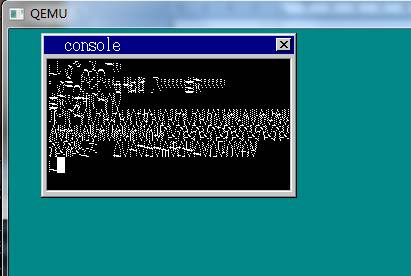
万恶的马赛克?????
三、再次了解HZK这个编码
果然还是功夫不到家。没有仔细的看代码。我们先了解一下字库,我下载了一个软件用于字库的生成和查看,
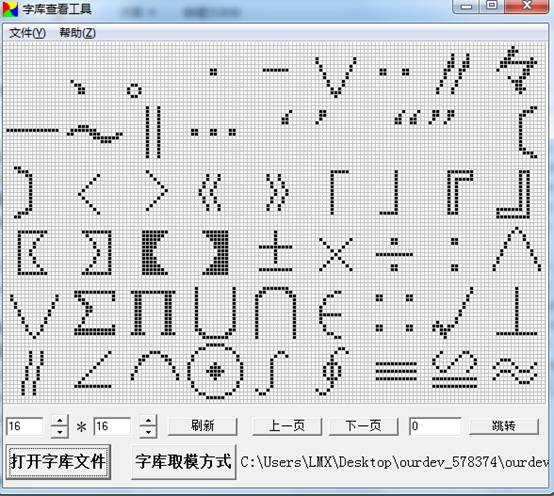
可以正常的显示,用这个软件打开系统自带的日文字库,是显示乱码的。我但是就在想我们系统显示乱码是不是编码方式不同还是因为压缩的原因,试着好多种办法。
这时想到了一个问题,自带的日文字库,好像是前半部分是半角,后半部分是全角。也就是做一个字库里面已经有了ASCII 256个半角在字库开头,而我们的HZK16,看上面我们也知道,HZK开头没有ascii的半角,直接就是全角的字符了。所以我们要修改haribote/graphic.c文件里面的task->langmode==3这里面的代码:
putfont8(vram, xsize, x, y, c, hankaku + *s * 16);//只要是半角就使用hankaku里面的字符
后果又是失败的,不过有了一点成功的迹象了。
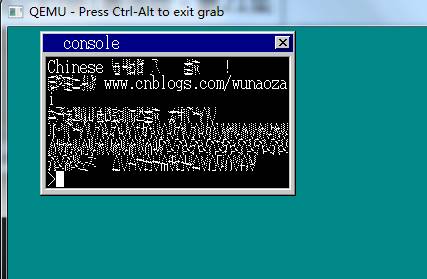
这次再改一下task->langmode==3,改font = nihongo + (k * 94 + t) * 32; 由于没有256个ascii所以这里也要该。再次make run。
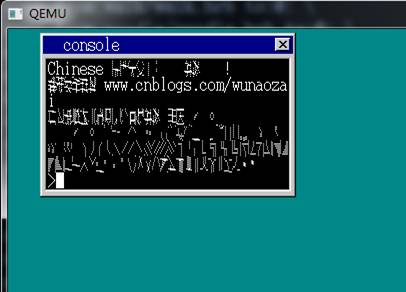
对了就是这个界面,昨天困扰我好久好久啊,由于上面的逗号和句号又可以显示,而其他的又显示不了。这是为什么呢?
四、书上是不是讲错,或是讲的不清楚
网上找了一个能显示HZK编码的C程序。
1 #include <stdio.h> 2 3 int main() 4 { 5 int i,j,k; 6 unsigned char incode[3]="中"; 7 unsigned char qh,wh; 8 unsigned long offset; 9 FILE * HZK; 10 char mat[16][2]; 11 char mat32[16]; 12 char mat64[16]; 13 qh = incode[0] - 0xa0; 14 wh = incode[1] - 0xa0; 15 //qh=18; 16 //wh=51; 17 printf("%d %d\n",qh,wh); 18 offset = (94*(qh-1)+(wh-1))*32; 19 20 if((HZK=fopen("HZK16","rb")) == NULL) 21 { 22 printf("Can't Open hzk16\n"); 23 return 0; 24 } 25 fseek(HZK, offset, SEEK_SET); 26 fread(mat, 32, 1, HZK); 27 fseek(HZK, offset, SEEK_SET); 28 fread(mat32, 16, 1, HZK); 29 fread(mat64, 16, 1, HZK); 30 for(j=0;j<16;j++) 31 { 32 for(i=0;i<2;i++) 33 { 34 for(k=0;k<8;k++) 35 { 36 if(mat[j][i]&(0x80>>k)) 37 { 38 printf("%c",'#'); 39 }else{ 40 printf("%c",'-'); 41 } 42 } 43 } 44 printf("\n"); 45 } 46 printf("\n"); 47 for(i=0;i<16;i++) 48 { 49 for(k=0;k<8;k++) 50 { 51 if(mat32[i]&(0x80>>k)) 52 { 53 printf("%c",'#'); 54 }else{ 55 printf("%c",'-'); 56 } 57 } 58 if(i%2) 59 printf("\n"); 60 } 61 for(i=0;i<16;i++) 62 { 63 for(k=0;k<8;k++) 64 { 65 if(mat64[i]&(0x80>>k)) 66 { 67 printf("%c",'#'); 68 }else{ 69 printf("%c",'-'); 70 } 71 } 72 if(i%2) 73 printf("\n"); 74 } 75 76 fclose(HZK); 77 78 return 0; 79 }
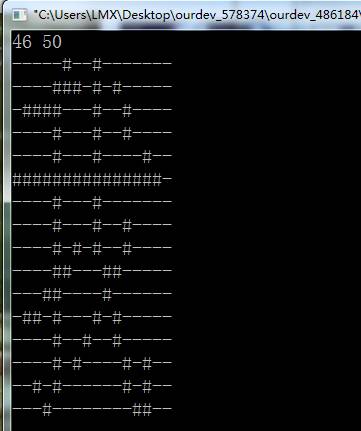
经过分析这个代码才知道,原来日文的编码是分左半部分和右半部分。而我们使用的HZK16是分上半部分和下半部分的。这一点坑了好久。
修改haribote/graphic.c
增加一个函数putfont32用于显示汉字(这个函数写的有点丑,能用就行了)
1 void putfont32(char *vram, int xsize, int x, int y, char c, char *font1, char *font2) 2 { 3 int i,k,j,f; 4 char *p, d ; 5 j=0; 6 p=vram+(y+j)*xsize+x; 7 j++; 8 //上半部分 9 for(i=0;i<16;i++) 10 { 11 for(k=0;k<8;k++) 12 { 13 if(font1[i]&(0x80>>k)) 14 { 15 p[k+(i%2)*8]=c; 16 } 17 } 18 for(k=0;k<8/2;k++) 19 { 20 f=p[k+(i%2)*8]; 21 p[k+(i%2)*8]=p[8-1-k+(i%2)*8]; 22 p[8-1-k+(i%2)*8]=f; 23 } 24 if(i%2) 25 { 26 p=vram+(y+j)*xsize+x; 27 j++; 28 } 29 } 30 //下半部分 31 for(i=0;i<16;i++) 32 { 33 for(k=0;k<8;k++) 34 { 35 if(font2[i]&(0x80>>k)) 36 { 37 p[k+(i%2)*8]=c; 38 } 39 } 40 for(k=0;k<8/2;k++) 41 { 42 f=p[k+(i%2)*8]; 43 p[k+(i%2)*8]=p[8-1-k+(i%2)*8]; 44 p[8-1-k+(i%2)*8]=f; 45 } 46 if(i%2) 47 { 48 p=vram+(y+j)*xsize+x; 49 j++; 50 } 51 } 52 return; 53 }
修改putfonts8_asc函数里if (task->langmode == 3)语句块里这两句
putfont8(vram, xsize, x - 8, y, c, font ); putfont8(vram, xsize, x , y, c, font + 16);
为
putfont32(vram,xsize,x-8,y,c,font,font+16);
终于改完了,应该可以了,有点小激动了,赶快make run一下
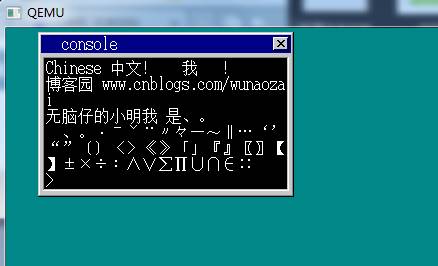
艾玛总算可以实现中文了。
参考资料
HZK编码 链接
所用到的工具和可以显示中文的代码:https://files.cnblogs.com/wunaozai/OS-in-30-days.zip
本文地址:http://www.cnblogs.com/wunaozai/p/3858473.html
|
作者:无脑仔的小明 出处:http://www.cnblogs.com/wunaozai/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。有需要沟通的,可以站内私信,文章留言,或者关注“无脑仔的小明”公众号私信我。一定尽力回答。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号