宋红康MySQL笔记
MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板
https://www.bilibili.com/video/BV1iq4y1u7vj?p=43&vd_source=ecbebcd4db8fad7f74c518d13e78b165
left join:用左表的第一行分别和右表的所有行进行连接,
如果有匹配的行,则一起输出,如果右表有多行匹配,则结果集输出多行,如有没有匹配行,则结果集中只输出一行,该输出行左边为左表第一行内容,右表全部输出null。
GROUP BY
记住这个求部门平均工资的例子。
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id
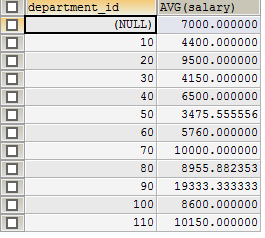
在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中,包含在 GROUP BY 子句中的列不必包含在SELECT 列表中。如何理解这句话?
假设出现了又怎么样呢?
SELECT department_id, job_id, AVG(salary)
FROM employees
GROUP BY department_id ;
那么查询结果该如何显示呢?
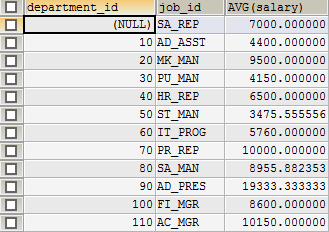
对比来看,job_id列无效,应该有很多个job_id。我觉得这个得结合实际需求来看,单独讨论无聊。
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中,这句话怎么理解?你都按部门分组了,select不写也知道分几组了。
count(*),count(1),count(列名)
用count(*)和count(1)一样,count(列名)效率低,count(*)包含null,count(列名)不包含null。
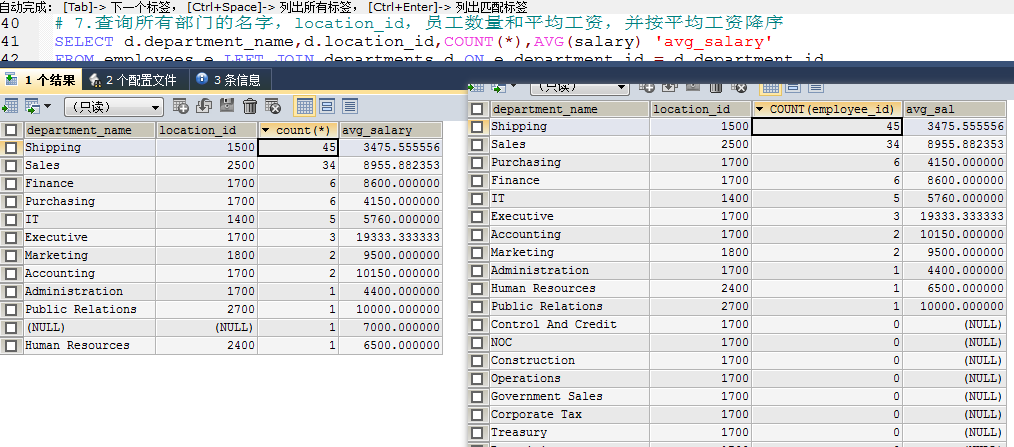
count(*)和count(列名)的对比,这个例子中employee_id为零是应该给展示出来的。
HAVING的使用
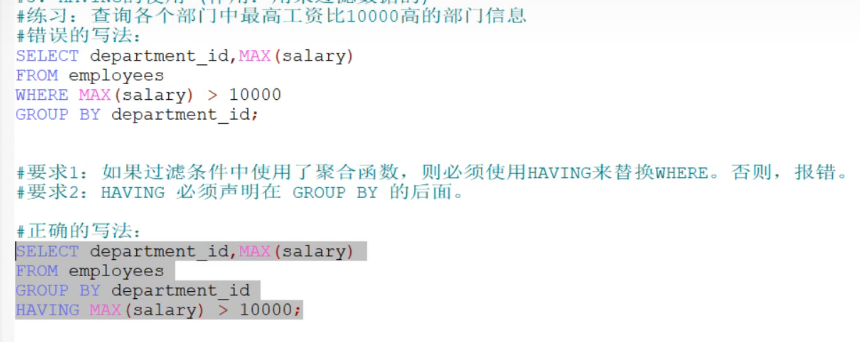
#练习:查询各个部门中最高工资比10000高的部门信息
#错误的写法:
SELECT department_id,MAX(salary)
FROM employees
WHERE MAX(salary) > 10000
GROUP BY department_id;
#要求1:如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则,报错。
#要求2:HAVING 必须声明在 GROUP BY 的后面。
#正确的写法:
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
#要求3:开发中,我们使用HAVING的前提是SQL中使用了GROUP BY。
#练习:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息
#方式1:推荐,执行效率高于方式2.
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary) > 10000;
#方式2:
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000 AND department_id IN (10,20,30,40);
#结论:当过滤条件中有聚合函数时,则此过滤条件必须声明在HAVING中。
# 当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以。
# 但是,建议大家声明在WHERE中。
/*
WHERE 与 HAVING 的对比
1. 从适用范围上来讲,HAVING的适用范围更广。
2. 如果过滤条件中没有聚合函数:这种情况下,WHERE的执行效率要高于HAVING
*/
select语句的完整结构

SQL语句的执行顺序

where在group by之前执行,一些行被删选掉了,所以比having效率高。因为还没分组,所以where中用聚合函数错误。

在select中起了别名,可以再order中使用,不能在where中使用。


相关子查询课后练习
#18.查询各部门中工资比本部门平均工资高的员工的员工号, 姓名和工资(相关子查询)
#方式1:使用相关子查询
SELECT last_name,salary,department_id
FROM employees e1
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
WHERE department_id = e1.`department_id`
);
#方式2:在FROM中声明子查询
SELECT e.last_name,e.salary,e.department_id
FROM employees e,(
SELECT department_id,AVG(salary) avg_sal
FROM employees
GROUP BY department_id) t_dept_avg_sal
WHERE e.department_id = t_dept_avg_sal.department_id
AND e.salary > t_dept_avg_sal.avg_sal
MySQL中的“Unknown column in ‘having clause’”问题
在 MySQL SQL中,当使用HAVING子句进行聚合函数查询时,有时会遇到“Unknown column in ‘having clause’”这个错误信息。它的含义是 SQL查询中在HAVING子句中引用的列是未知的或不存在的。https://deepinout.com/mysql/mysql-questions/769_mysql_unknown_column_in_having_clause.html
这种错误通常发生在以下情况:
- 被引用的列名拼写错误或不存在。
- HAVING子句中未使用GROUP BY,而在SELECT语句中使用了聚合函数,因此 MySQL SQL不知道如何分组数据。
- 在HAVING子句中使用别名(alias),但 MySQL SQL可能无法识别别名,因为在执行语句的过程中,HAVING子句的执行是在SELECT语句中的执行之后。
创建表
sqlyog文件名乱码
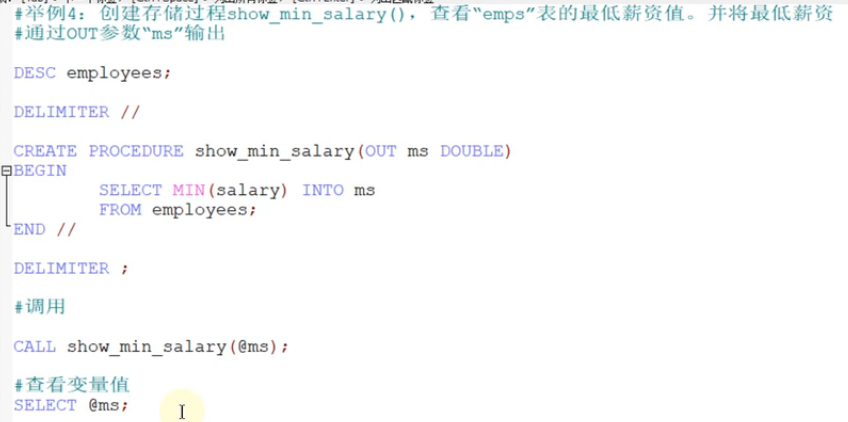
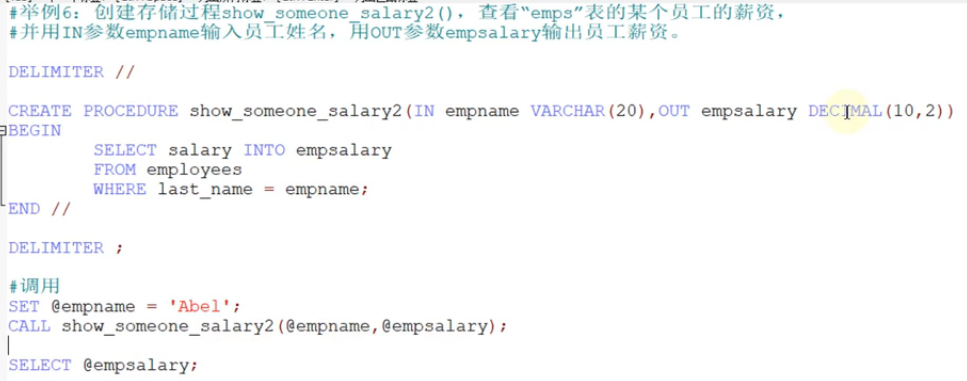
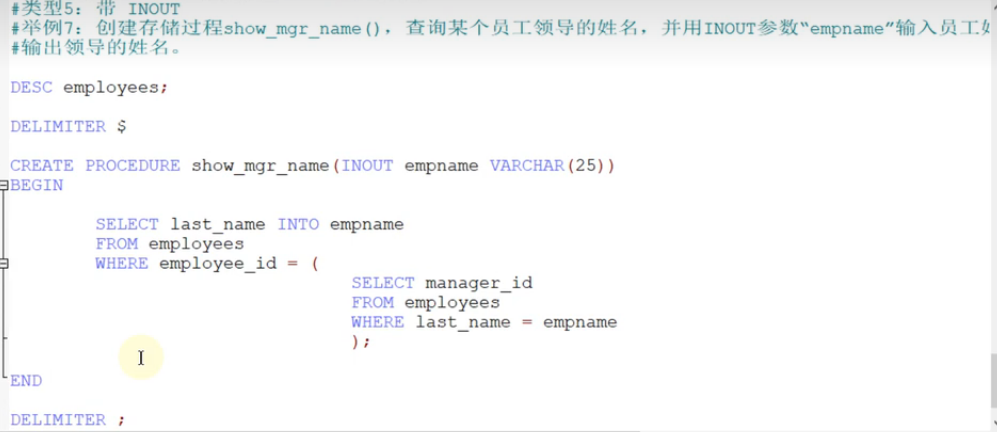
存储过程



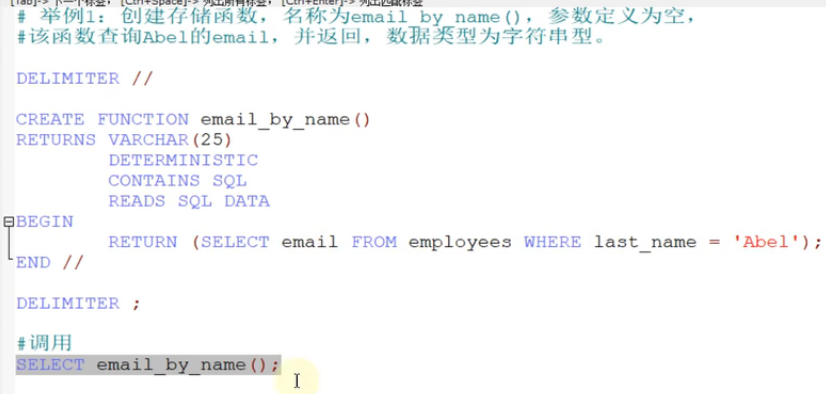
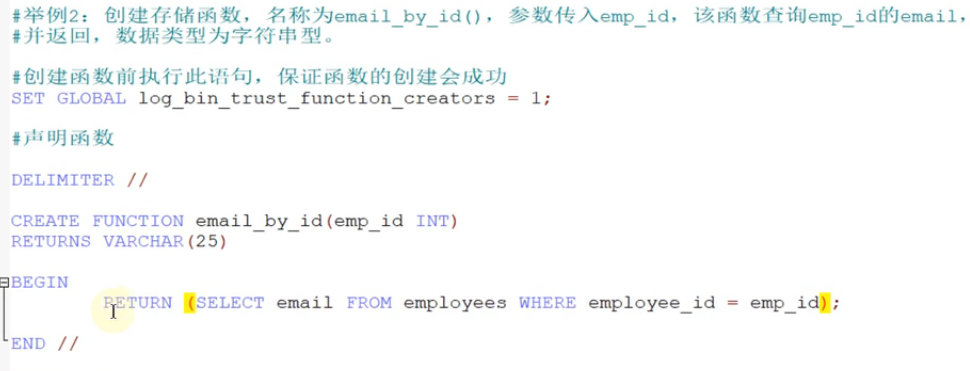
存储函数
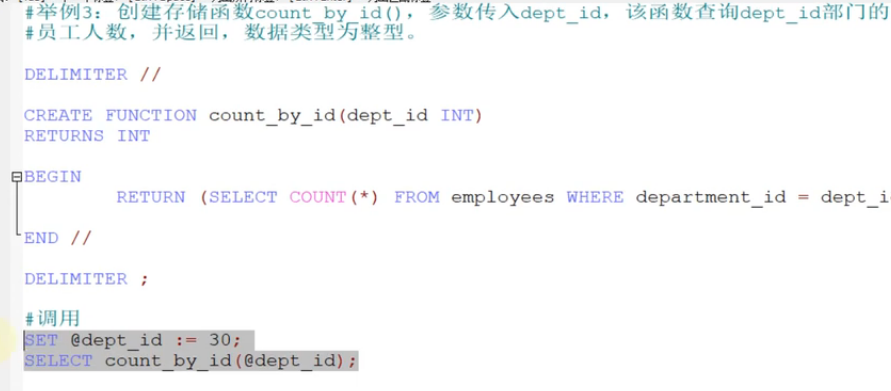

修改系统变量

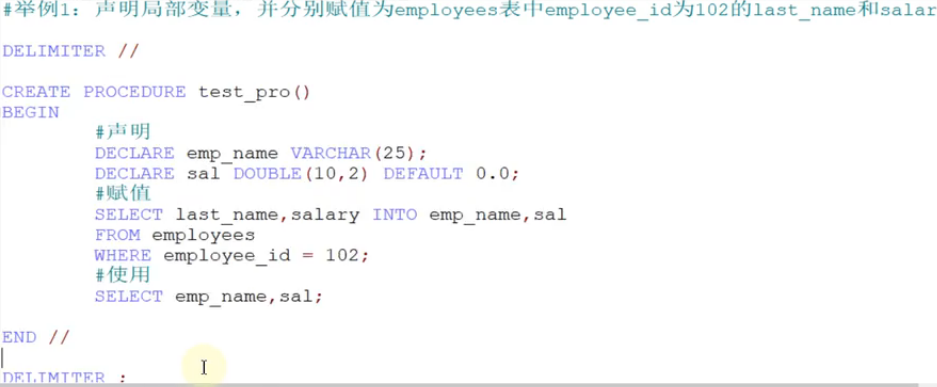
局部变量举例
#举例: DELIMITER // CREATE PROCEDURE test_var() BEGIN #1、声明局部变量 DECLARE a INT DEFAULT 0; DECLARE b INT ; #DECLARE a,b INT DEFAULT 0; DECLARE emp_name VARCHAR(25); #2、赋值 SET a = 1; SET b := 2; SELECT last_name INTO emp_name FROM employees WHERE employee_id = 101; #3、使用 SELECT a,b,emp_name; END // DELIMITER ; #调用存储过程 CALL test_var();
局部变量举例2
#举例2:声明两个变量,求和并打印 (分别使用会话用户变量、局部变量的方式实现) #方式1:使用会话用户变量 SET @v1 = 10; SET @v2 := 20; SET @result := @v1 + @v2; #查看 SELECT @result; #方式2:使用局部变量 DELIMITER // CREATE PROCEDURE add_value() BEGIN #声明 DECLARE value1,value2,sum_val INT; #赋值 SET value1 = 10; SET value2 := 100; SET sum_val = value1 + value2; #使用 SELECT sum_val; END // DELIMITER ; #调用存储过程 CALL add_value();
局部变量举例3
#举例3:创建存储过程“different_salary”查询某员工和他领导的薪资差距,并用IN参数emp_id接收员工id, #用OUT参数dif_salary输出薪资差距结果。 DELIMITER // CREATE PROCEDURE different_salary(IN emp_id INT,OUT dif_salary DOUBLE) BEGIN #分析:查询出emp_id员工的工资;查询出emp_id员工的管理者的id;查询管理者id的工资;计算两个工资的差值 #声明变量 DECLARE emp_sal DOUBLE DEFAULT 0.0; #记录员工的工资 DECLARE mgr_sal DOUBLE DEFAULT 0.0; #记录管理者的工资 DECLARE mgr_id INT DEFAULT 0; #记录管理者的id #赋值 SELECT salary INTO emp_sal FROM employees WHERE employee_id = emp_id; SELECT manager_id INTO mgr_id FROM employees WHERE employee_id = emp_id; SELECT salary INTO mgr_sal FROM employees WHERE employee_id = mgr_id; SET dif_salary = mgr_sal - emp_sal; END // DELIMITER ; #调用存储过程 SET @emp_id := 103; SET @dif_sal := 0; CALL different_salary(@emp_id,@dif_sal); SELECT @dif_sal; SELECT * FROM employees;
定义条件与处理程序
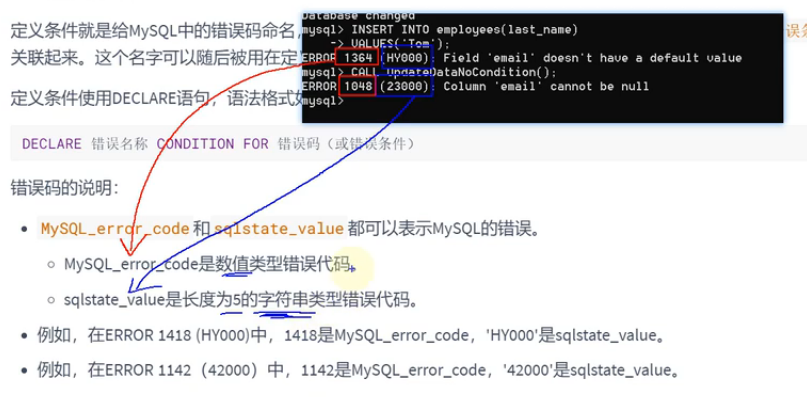
处理程序案例
#2.4 案例的处理 DROP PROCEDURE UpdateDataNoCondition; #重新定义存储过程,体现错误的处理程序 DELIMITER // CREATE PROCEDURE UpdateDataNoCondition() BEGIN #声明处理程序 #处理方式1: DECLARE CONTINUE HANDLER FOR 1048 SET @prc_value = -1; #处理方式2: #DECLARE CONTINUE HANDLER FOR sqlstate '23000' SET @prc_value = -1; SET @x = 1; UPDATE employees SET email = NULL WHERE last_name = 'Abel'; SET @x = 2; UPDATE employees SET email = 'aabbel' WHERE last_name = 'Abel'; SET @x = 3; END // DELIMITER ; #调用存储过程: CALL UpdateDataNoCondition(); #查看变量: SELECT @x,@prc_value;
#2.5 再举一个例子: #创建一个名称为“InsertDataWithCondition”的存储过程 #① 准备工作 CREATE TABLE departments AS SELECT * FROM atguigudb.`departments`; DESC departments; ALTER TABLE departments ADD CONSTRAINT uk_dept_name UNIQUE(department_id); #② 定义存储过程: DELIMITER // CREATE PROCEDURE InsertDataWithCondition() BEGIN SET @x = 1; INSERT INTO departments(department_name) VALUES('测试'); SET @x = 2; INSERT INTO departments(department_name) VALUES('测试'); SET @x = 3; END // DELIMITER ; #③ 调用 CALL InsertDataWithCondition(); SELECT @x; #2 #④ 删除此存储过程 DROP PROCEDURE IF EXISTS InsertDataWithCondition; #⑤ 重新定义存储过程(考虑到错误的处理程序) DELIMITER // CREATE PROCEDURE InsertDataWithCondition() BEGIN #处理程序 #方式1: #declare exit handler for 1062 set @pro_value = -1; #方式2: #declare exit handler for sqlstate '23000' set @pro_value = -1; #方式3: #定义条件 DECLARE duplicate_entry CONDITION FOR 1062; DECLARE EXIT HANDLER FOR duplicate_entry SET @pro_value = -1; SET @x = 1; INSERT INTO departments(department_name) VALUES('测试'); SET @x = 2; INSERT INTO departments(department_name) VALUES('测试'); SET @x = 3; END // DELIMITER ; #调用 CALL InsertDataWithCondition(); SELECT @x,@pro_value;
游标的使用
#举例:创建存储过程“get_count_by_limit_total_salary()”,声明IN参数 limit_total_salary, #DOUBLE类型;声明OUT参数total_count,INT类型。函数的功能可以实现累加薪资最高的几个员工的薪资值, #直到薪资总和达到limit_total_salary参数的值,返回累加的人数给total_count。 DELIMITER // CREATE PROCEDURE get_count_by_limit_total_salary(IN limit_total_salary DOUBLE,OUT total_count INT) BEGIN #声明局部变量 DECLARE sum_sal DOUBLE DEFAULT 0.0; #记录累加的工资总额 DECLARE emp_sal DOUBLE; #记录每一个员工的工资 DECLARE emp_count INT DEFAULT 0;#记录累加的人数 #1.声明游标 DECLARE emp_cursor CURSOR FOR SELECT salary FROM employees ORDER BY salary DESC; #2.打开游标 OPEN emp_cursor; REPEAT #3.使用游标 FETCH emp_cursor INTO emp_sal; SET sum_sal = sum_sal + emp_sal; SET emp_count = emp_count + 1; UNTIL sum_sal >= limit_total_salary END REPEAT; SET total_count = emp_count; #4.关闭游标 CLOSE emp_cursor; END // DELIMITER ; #调用 CALL get_count_by_limit_total_salary(200000,@total_count); SELECT @total_count;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号