
面试常考基本算法
- 决策树
https://zhuanlan.zhihu.com/p/26703300 - 随机森林
http://www.cnblogs.com/maybe2030/p/4585705.html - 朴素贝叶斯分类
https://blog.csdn.net/amds123/article/details/70173402 - 协同过滤
https://blog.csdn.net/xiaokang123456kao/article/details/74735992
1. 决策树笔记
决策树的基本思想是这样的:一个样本有多个特征,我们判断一个样本的类别,不能只通过一个特征进行判断,而是要通过多个特征进行综合判断。我们可以先对一个特征进行判断,缩小判断结果范围,然后再对下一个特征进行判断。经过足够多的特征判断后,我们就可以得到比较正确的分类结果。
决策树举例如下图所示,每个非叶子节点表示一个特征,每条边对应特征的一个属性,叶子节点表示分类的一个类别。
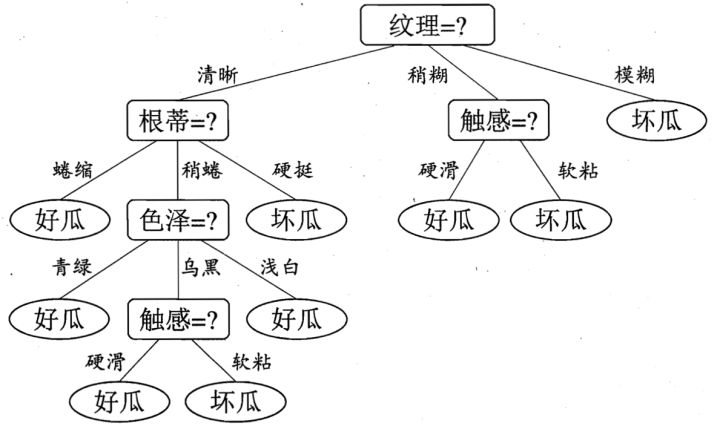
摘自周志华老师西瓜书
2. 随机森林笔记
1. 随机森林的应用
随机森林可以用于统计客户的来源、保留、流失,预测疾病的风险等。
2. 随机森林的主要思想
随机森林是将多个决策树通过集成学习(Ensemble learning)的思想融合在一起,也就是每个决策树输出一个分类结果,然后以投票的方式,得到票数最多的那一类作为最终分类结果输出。
3. 随机森林的优点
- 具有很好的准确性;
- 能够运用在大数据集上;
- 能够处理高维数据;
- 能够对数据的每个特征对于分类问题的重要性进行评估。
4. 随机森林的生成
- 假设训练样本为N,那么对于每个决策树分类器,每次从样本库中“随机”有放回地抽取N个样本作为训练集来训练该决策树分类器。
“随机”是为了训练出不同的分类器,从而增加分类结果的可靠性;“有放回”是为了避免训练出的每个分类器的投票结果都不一样。 - 设每个样本有M个特征,指定一个数m<<M,从样本的M个特种中"随机"地选取m个特征,每次进行树的分裂时,从这个m个特征中选择最优的。
- 前面2点中的“随机”能使得随机森林有效地避免过拟合的问题,并且使其算法鲁棒性更强。
不当之处,敬请批评指正。
