循环神经网络(Recurrent Neural Network,RNN)
为什么使用序列模型(sequence model)?标准的全连接神经网络(fully connected neural network)处理序列会有两个问题:1)全连接神经网络输入层和输出层长度固定,而不同序列的输入、输出可能有不同的长度,选择最大长度并对短序列进行填充(pad)不是一种很好的方式;2)全连接神经网络同一层的节点之间是无连接的,当需要用到序列之前时刻的信息时,全连接神经网络无法办到,一个序列的不同位置之间无法共享特征。而循环神经网络(Recurrent Neural Network,RNN)可以很好地解决问题。
1. 序列数据
在介绍循环神经网络之前,先来了解一些序列数据:

图 1:序列数据
输入 $x$ 和输出 $y$ 可能都是序列,也可能只有一个是序列;输入 $x$ 和输出 $y$ 两个序列的长度可能相等也可能不等。下文介绍循环神经网络结构时,输入 $x$ 和输出 $y$ 两个序列的长度相同。(下文出现的 $h$ 和最终的输出结果 $y$ 在本文中被认为不相同)
2. 循环神经网络的结构
图 2 展示了一个经典的循环神经网络(RNN):(这张图初次看真的让人很懵)
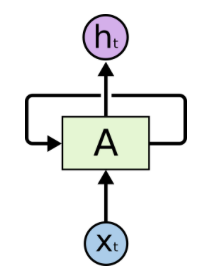
图 2:循环神经网络经典结构示意图
对于 RNN,一个非常重要的概念就是时刻。RNN 会对每一个时刻的输入结合当前模型的状态给出一个输出。图 2 中,$t$ 时刻 RNN 的主体结构 A 的输入除了来自输入层 $X_t$,还有一个循环的边来提供从 $t-1$ 时刻传递来的隐藏状态。(这一段看不懂没关系,看下面)
RNN 可以被看作是同一个神经网络结构按照时间序列复制的结果。图 3 展示了一个展开的 RNN。(展开图相对比较好理解)
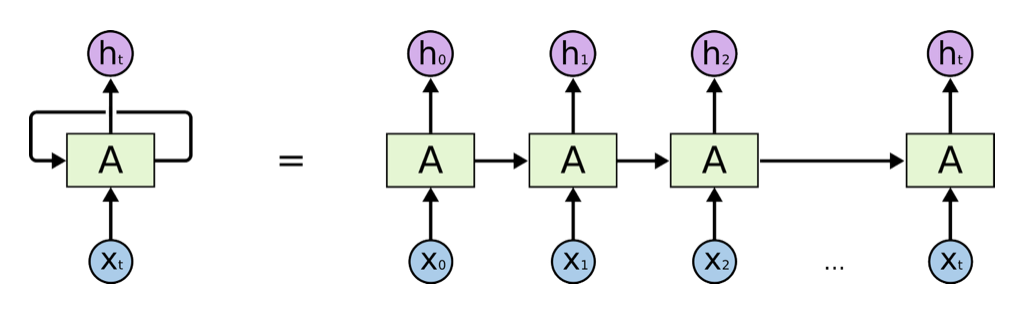
图 3:循环神经网络按时间展开
从 RNN 的展开结构可以很容易得出它最擅长解决的问题是与时间序列相关的。RNN 也是处理这类问题时最自然的神经网络结构。
RNN 的主体结构 A 按照时间序列复制了多次,结构 A 也被称之为循环体。如何设计循环体 A 的网络结构是 RNN 解决实际问题的关键。和卷积神经网络(CNN)过滤器中参数共享类似,在 RNN 中,循环体 A 中的参数在不同时刻也是共享的。
图 4 展示了一个最简单的使用单个全连接层作为循环体 A 的 RNN,图中黄色的 tanh 小方框表示一个使用 tanh 作为激活函数的全连接层。
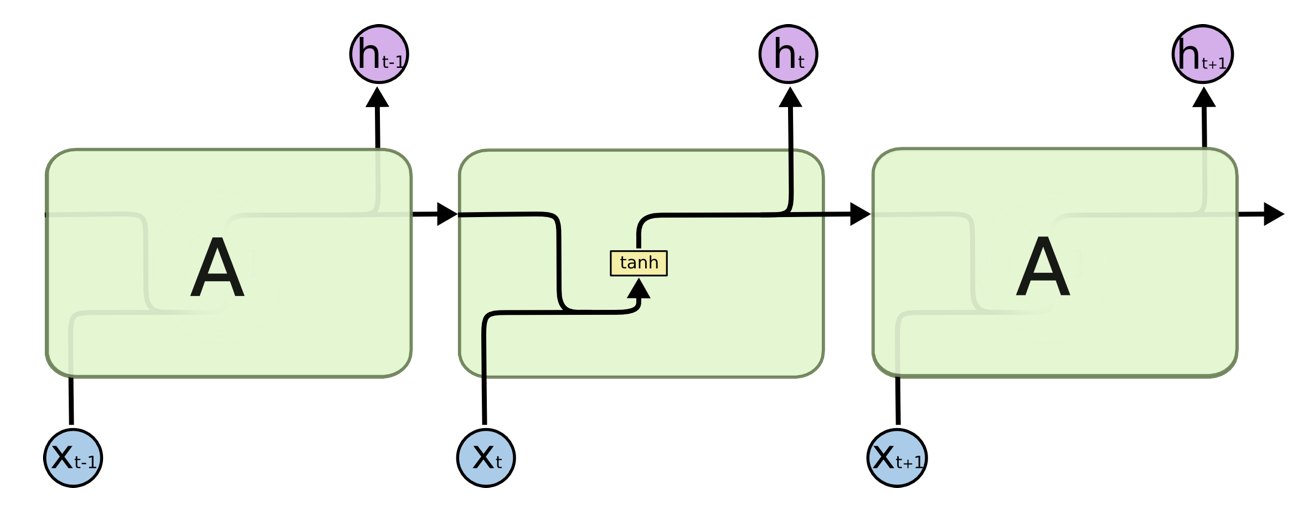
图 4:使用单层全连接神经网络作为循环体的 RNN 结构图

图 5:图 4 中各种符号代表的含义
(注:Pointwise Operation在图 4 中没有出现)
$t$ 时刻循环体 A 的输入包括 $X_t$ 和从 $t-1$ 时刻传递来的隐藏状态 $h_{t-1}$(依据图 5 copy 标志,$t-1$ 和 $t$ 时刻循环体 A 之间连接的箭头即表示隐藏状态 $h_{t-1}$ 的传递)。循环体 A 的两部分输入如何处理呢?依据图 5 ,将 $X_t$ 和 $h_{t-1}$ 直接拼接起来,成为一个更大的矩阵/向量 $[X_t, h_{t-1}]$。假设 $X_t$ 和 $h_{t-1}$ 的形状分别为 [1, 3] 和 [1, 4],则最后循环体 A 中全连接层输入向量的形状为 [1, 7]。拼接完后按照全连接层的方式进行处理即可。
为了将当前时刻的隐含状态 $h_t$ 转化为最终的输出 $y_t$,循环神经网络还需要另一个全连接层来完成这个过程。这和卷积神经网络中最后的全连接层意义是一样的。(如果不考虑 RNN 的输出还需要一个全连接层的情况,那么 $h_t$ 和 $y_t$ 的值是一样的)
RNN 的前向传播计算过程如下图所示:
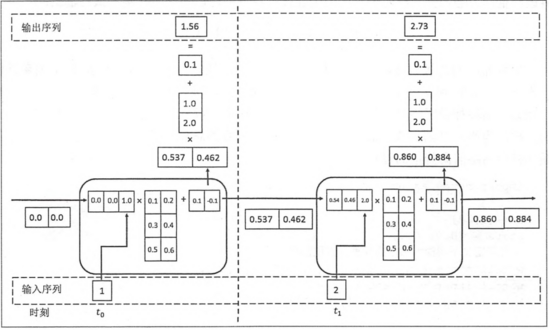
图 6:RNN的前向传播计算过程示意图
图 6 很清晰地向我们展示了 RNN 循环体 A 中具体的计算流程,以及当前隐藏状态 $h_t$ 转化为最终输出 $y_t$ 的过程。
3. 循环神经网络的类型

图 7:RNN 的类型
(1)one to one:其实和全连接神经网络并没有什么区别,这一类别算不得是 RNN。
(2)one to many:输入不是序列,输出是序列。
(3)many to one:输入是序列,输出不是序列。
(4)many to many:输入和输出都是序列,但两者长度可以不一样。
(5)many to many:输出和输出都是序列,两者长度一样。
4. 基础循环神经网络的局限
上述图片中展示的都是单向的 RNN,单向 RNN 有个缺点是在 $t$ 时刻,无法使用 $t+1$ 及之后时刻的序列信息,所以就有了双向循环神经网络(bidirectional RNN)。
“需要特别指出,理论上循环神经网络可以支持任意长度的序列,然而在实际中,如果序列过长会导致优化时出现梯度消散的问题(the vanishing gradient problem),所以实际中一般会规定一个最大长度,当序列长度超过规定长度之后会对序列进行截断。”
RNN 面临的一个技术挑战是长期依赖(long-term dependencies)问题,即当前时刻无法从序列中间隔较大的那个时刻获得需要的信息。在理论上,RNN 完全可以处理长期依赖问题,但实际处理过程中,RNN 表现得并不好。
但是 GRU 和 LSTM 可以处理梯度消散问题和长期依赖问题。
5. 门控循环单元(Gated Recurrent Unit,GRU)和 长短时记忆网络(Long Short Term Memory,LSTM)
相比于基础的RNN,GRU 和 LSTM 与之不同的地方在于循环体 A 的网络结构。
GRU 和 LSTM 都引入了一个的概念,门(gate)。GRU 有两个“门”(“更新门”和“重置门”),而 LSTM 有三个“门”(“遗忘门”、“输入门”和“输出门”)。
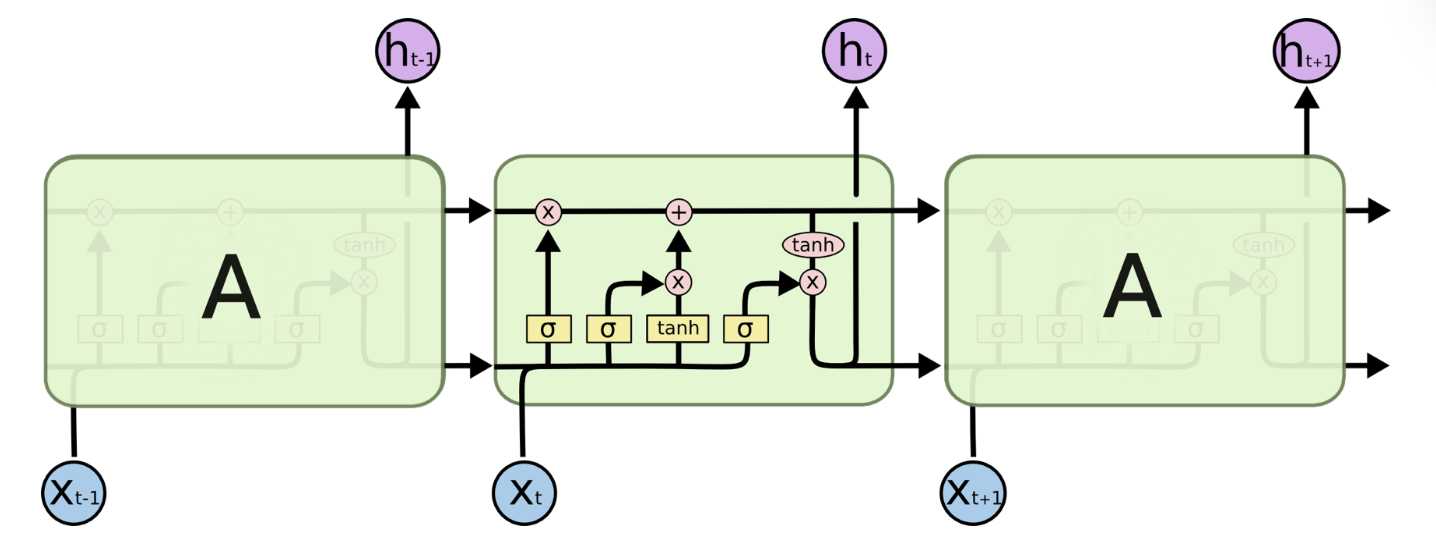
图 8:LSTM
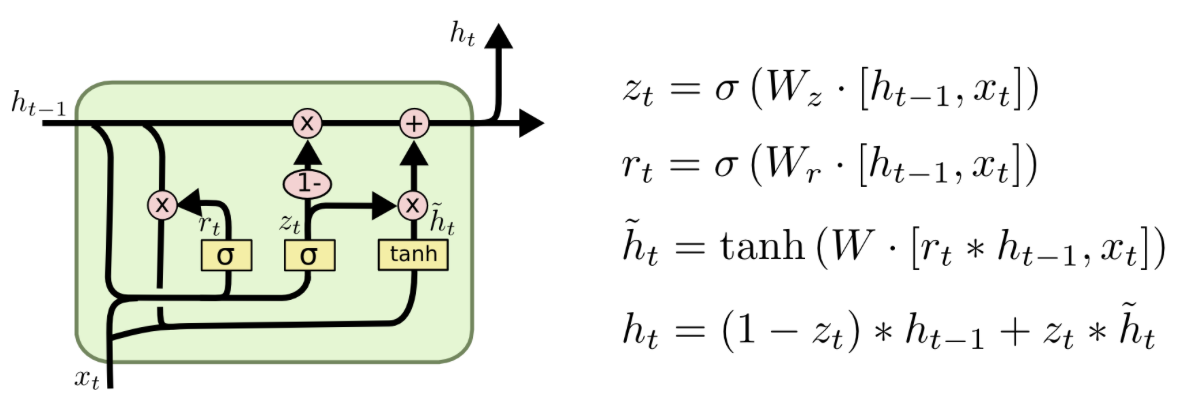
图 9:GRU
GRU 和 LSTM 靠一些“门”的结构让信息有选择地影响循环神经网络中每个时刻的状态。所谓“门”结构,就是一个使用 sigmoid 的全连接层和一个按位做乘法的操作,这两个操作合起来就是一个“门”结构,如图 9所示。
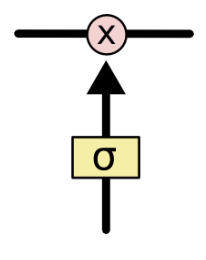
图 9:“门”结构
之所以叫“门”结构,是因为使用 sigmoid 作为激活函数的全连接神经网络层会输出一个 0 到 1 之间的数值,描述当前输入有多少信息量可以通过这个结构。于是这个结构的功能就类似于一扇门,当门打开时(sigmoid 全连接层输出为 1 时),全部信息可以通过;当门关上时(sigmoid 神经网络层输出为 0 时),任何信息都无法通过。
LSTM 有三个门,分别是“遗忘门”(forget gate)、“输入门”(input gate)和“输出门”(output gate)。“遗忘门”的作用是让循环神经网络“忘记”之前没有用的信息。“输入门”决定哪些信息进入当前时刻的状态。通过“遗忘门”和“输入门”,LSTM 结构可以很有效地决定哪些信息应该被遗忘,哪些信息应该得到保留。LSTM 在得到当前时刻状态 $C_t$ 之后,需要产生当前时刻的输出,该过程通过“输出门”完成。
GRU 的两个门:一个是“更新门”(update gate),它将 LSTM 的“遗忘门”和“输入门”融合成了一个“门”结构;另一个是“重置门”(reset gate)。“从直观上来说,‘重置门’决定了如何将新的输入信息与前面的记忆相结合,‘更新门’定义了前面记忆保存到当前时刻的量。” “那些学习捕捉短期依赖关系的单元将趋向于激活‘重置门’,而那些捕获长期依赖关系的单元将常常激活‘更新门’。”
LSTM 和 GRU 更多内容,请参考 Understanding LSTM Networks 和 机器之心GitHub项目:从循环到卷积,探索序列建模的奥秘。
(注:文中出现的字母 $h$ 表示 hidden state, $C$ 表示 cell state。)
References
The Unreasonable Effectiveness of Recurrent Neural Networks
Course 5 Sequence Models by Andrew Ng
《TensorFLow实战Google深度学习框架》

