Hadoop数据本地化策略
参考 https://blog.csdn.net/shenshengsu1990/article/details/94625194
结合下图来讲解 ......
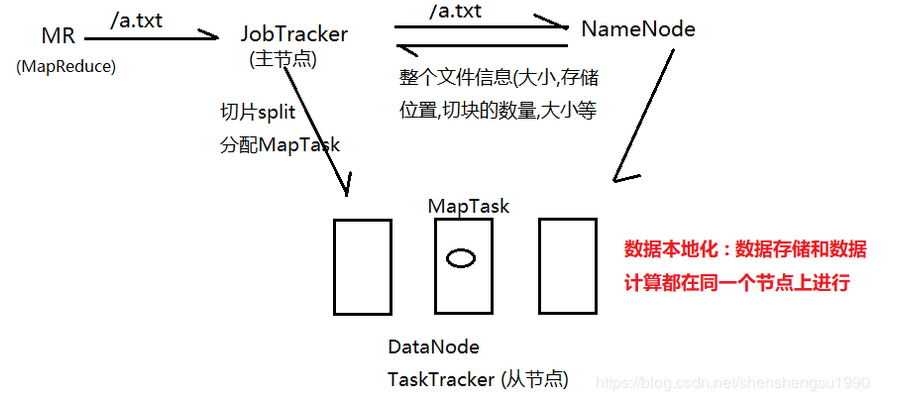
JobTracker接收到任务之后,会去访问NameNode获取要处理的文件信息
NameNode将文件块的一些信息返回给JobTracker
JobTracker会根据文件信息,进行切片(逻辑切片)
每一个切片对应一个MapTask,然后分发给TaskTracker来执行
在分发的时候,哪一个DataNode上有对应的Block,那么就把TaskTracker分发到这个节点上,这样数据存储和数据计算都在同一个节点上了
这就是hadoop的数据本地化策略 ---- 为了减少拷贝文件或数据传递带来网络损耗

 浙公网安备 33010602011771号
浙公网安备 33010602011771号