Elasticsearch7.x 常用索引、文档命令
以下命令均在Kibana中执行
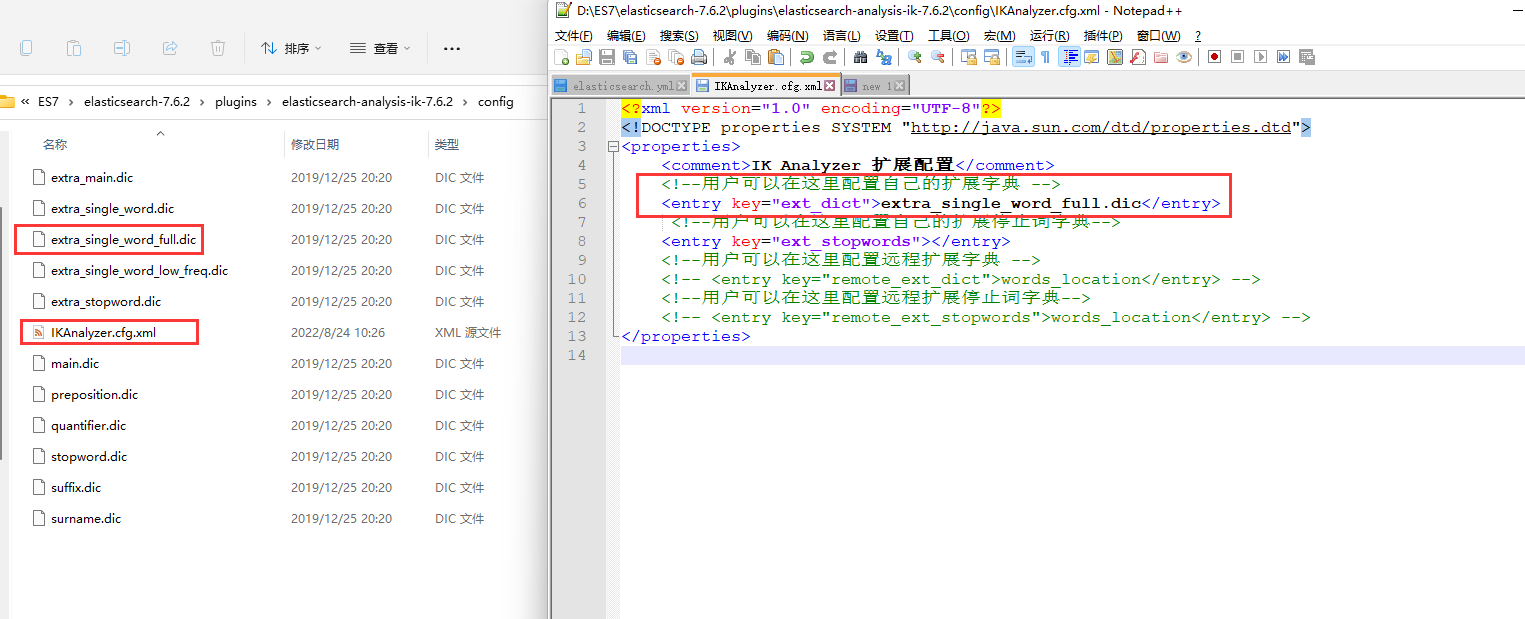
#创建默认索引 PUT test #创建自定义索引--自定义index分词器 PUT custom { "settings": { "index": { "analysis": { "analyzer": { "default": { "tokenizer": "ik_max_word" }, "pinyin_analyzer": { "tokenizer": "my_pinyin" } }, "tokenizer": { "my_pinyin": { "type": "pinyin", "keep_first_letter": true, "first_letter": "prefix", "keep_separate_first_letter": false, "keep_full_pinyin": true, "keep_original": true, "keep_none_chinese": true, "keep_none_chinese_in_first_letter": true, "limit_first_letter_length": 16, "lowercase": true, "trim_whitespace": true, "remove_duplicated_term": true } } } } } } #自定义mapping,如果不自定义的话,在创建文档的时候,会自动根据字段值的类型创建默认的mapping PUT custom/_mapping { "properties":{ "name":{ "type":"text", "index":true }, "nick":{ "type":"text", "index":false }, "tel":{ "type":"keyword", "index":true }, "age":{ "type":"integer" } } } #查看索引 GET test #查看所有索引 GET _cat/indices GET _cat/indices?v #删除索引 DELETE test #提交文档 POST custom/_doc { "name":"唐僧", "nick":"三藏,御弟,金蝉子", "tel":13453345678, "animial":"human" } #提交自定义ID文档 POST custom/_doc/1001 { "name":"唐僧2", "nick":"三藏,御弟,金蝉子", "tel":13453345678, "animial":"human" } #查看文档 GET custom/_search #查看指定文档 GET custom/_doc/1001 #修改文档--全字段覆盖,再次检索时发现此次未添加的tel字段已经没有了 POST custom/_doc/1001 { "name":"唐僧update", "nick":"三藏1,御弟1,金蝉子1", "animial":"human" } #修改文档-指定字段覆盖,可以新加字段 POST custom/_update/1001 { "doc":{ "name" : "唐僧update2", "from":"东土大唐" } } #删除文档 DELETE custom/_doc/1001 #创建一批数据,检索用,指定上面的删除custom索引,以及自定义创建custom索引 #age我都随便写了 POST custom/_doc/1001 { "name":"唐僧", "nick":"三藏,御弟,金蝉子", "tel":13453345678, "animial":"human", "age":18 } #此处没用孙悟空是因为ik分词器对孙悟空和猪悟能、沙悟净给出的分词结果不一样,效果不同,这个后面详看 POST custom/_doc/1002 { "name":"孙大圣", "nick":"孙行者,猴子,猴哥,斗战胜佛", "animial":"monkey", "tel":"123456789", "age":1500 } POST custom/_doc/1003 { "name":"猪悟能", "nick":"净坛使者,老猪,八戒", "animial":"pig", "tel":"123456789", "age":2000 } POST custom/_doc/1004 { "name":"沙悟净", "nick":"卷帘大将", "animial":"immortal", "tel":"123456789", "age":2800 } POST custom/_doc/1005 { "name":"敖广", "nick":"东海龙王", "animial":"dragon", "tel":"233567", "age":5000 } POST custom/_doc/1006 { "name":"敖烈", "nick":"八部天龙", "animial":"dragon", "tel":"233567", "age":1200 } POST custom/_doc/1007 { "name":"红孩儿", "nick":"小屁孩,善财童子", "animial":"cattle", "tel":"123456", "age":15 } POST custom/_doc/1008 { "name":"绿孩儿", "nick":"小屁孩,善财童子", "animial":"cattle", "tel":"123456", "age":18 } POST custom/_doc/1009 { "name":"白孩儿", "nick":"小屁孩,善财童子", "animial":"cattle", "tel":"123456", "age":18 } POST custom/_doc/1010 { "name":"黑孩儿", "nick":"小屁孩,善财童子", "animial":"cattle", "tel":"123456", "age":20 } #检索文档--匹配检索,将name字段分词后,分词结果与“悟”匹配的文档 GET custom/_search { "query" : { "match": { "name": "熬烈" } } } #检索文档,短语检索 GET custom/_search { "query" : { "match_phrase": { "name": "悟能" } } } #高亮 GET custom/_search { "query" : { "match": { "name": "悟能" } }, "highlight": { "fields": { "name": {} } } } #排序,排序的字段不能为TEXT类型 GET custom/_search { "query" : { "match": { "name": "悟能" } }, "sort": [ { "tel": { "order": "desc" } } ], "highlight": { "fields": { "name": {} } } } #回显指定字段 GET custom/_search { "query" : { "match": { "name": "悟能" } }, "sort": [ { "age": { "order": "desc" } } ], "highlight": { "fields": { "name": {} } }, "_source": "{name}" } #范围 GET custom/_search { "query" : { "match": { "name": "孩儿" } }, "sort": [ { "age": { "order": "desc" } } ], "highlight": { "fields": { "name": {} } }, "_source": "{name,age}" } #聚合--分组 #terms.size表示返回多少组bucket #最外层的size=0表示不返回原始数据 GET custom/_search { "query" : { "match": { "name": "孩儿" } }, "sort": [ { "age": { "order": "desc" } } ], "highlight": { "fields": { "name": {} } }, "_source": "{name}", "aggs": { "age_group": { "terms": { "field": "age", "size": 2 } } }, "size": 0 } #聚合--平均 #terms.size表示返回多少组bucket GET custom/_search { "query" : { "match": { "name": "孩儿" } }, "sort": [ { "age": { "order": "desc" } } ], "highlight": { "fields": { "name": {} } }, "_source": "{name}", "aggs": { "age_group": { "avg": { "field": "age" } } } } #组合查询, must 两项都要满足 GET custom/_search { "query": { "bool": { "must": [ { "match":{ "name": "孩儿" } }, { "match":{ "age":18 } } ] } } } #组合查询, should 至少满足其中之一 GET custom/_search { "query": { "bool": { "should": [ { "match":{ "name": "孩儿" } }, { "match":{ "age":18 } } ] } } } #组合查询, 范围查询 GET custom/_search { "query": { "bool": { "must": [ { "match":{ "name": "孩儿" } } ], "filter": [ { "range": { "age": { "gte": 18 } } } ] } } } #分词分析,由于分词器对两个词的分词结果不同,所以在查询“悟”的时候,没能匹配上孙悟空 GET test/_analyze { "text":"孙悟空", "analyzer": "ik_max_word" } GET test/_analyze { "text":"沙悟净", "analyzer": "ik_smart" } #解决方案,修改{esPath}\plugins\elasticsearch-analysis-ik-7.6.2\config\IKAnalyzer.cfg.xml #添加一行 <entry key="ext_dict">extra_single_word_full.dic</entry> #重启ES

 浙公网安备 33010602011771号
浙公网安备 33010602011771号