
ElasticSearch 拼音分词器(上)
拼音分词环境准备
找到和ElasticSearch版本相同的ik分词器和拼音分词器ElasticSearch的plugins目录下。
ElasticSearch 插件链接 http://dl.elasticsearch.cn/elasticsearch-plugins/
重启ElasticSearch。
拼音分词属性简介
| 属性 | 说明 |
|---|---|
| keep_first_letter | 启用此选项时,例如:刘德华> ldh,默认值:true |
| keep_separate_first_letter | 启用该选项时,将保留第一个字母分开,例如:刘德华> l,d,h,默认:false,注意:查询结果也许是太模糊,由于长期过频 |
| limit_first_letter_length | 设置first_letter结果的最大长度,默认值:16 |
| keep_full_pinyin | 当启用该选项,例如:刘德华> [ liu,de,hua],默认值:true |
| keep_joined_full_pinyin | 当启用此选项时,例如:刘德华> [ liudehua],默认值:false |
| keep_none_chinese | 在结果中保留非中文字母或数字,默认值:true |
| keep_none_chinese_together | 保持非中国信一起,默认值:true,如:DJ音乐家- > DJ,yin,yue,jia,当设置为false,例如:DJ音乐家- > D,J,yin,yue,jia,注意:keep_none_chinese必须先启动 |
| keep_none_chinese_in_first_letter | 第一个字母保持非中文字母,例如:刘德华AT2016- > ldhat2016,默认值:true |
| keep_none_chinese_in_joined_full_pinyin | 保留非中文字母加入完整拼音,例如:刘德华2016- > liudehua2016,默认:false |
| none_chinese_pinyin_tokenize | 打破非中国信成单独的拼音项,如果他们拼音,默认值:true,如:liudehuaalibaba13zhuanghan- > liu,de,hua,a,li,ba,ba,13,zhuang,han,注意:keep_none_chinese和keep_none_chinese_together应首先启用 |
| keep_original | 当启用此选项时,也会保留原始输入,默认值:false |
| lowercase | 小写非中文字母,默认值:true |
| trim_whitespace | 默认值:true |
| remove_duplicated_term | 当启用此选项时,将删除重复项以保存索引,例如:de的> de,默认值:false,注意:位置相关查询可能受影响 |
接下来,我们一个一个来尝试,看看每一个属性具体代表什么意思。
创建一个索引,使用三个分词器。
{ "index": { "number_of_shards": 5, "number_of_replicas": 0, "max_result_window": 100000000, "analysis": { "analyzer": {
"pinyin_analyzer_keyword": { "tokenizer": "keyword", "filter": "my_pinyin" }, "pinyin_analyzer_ik_smart": { "tokenizer": "ik_smart", "filter": "my_pinyin" }, "pinyin_analyzer_ik_max": { "tokenizer": "ik_max_word", "filter": "my_pinyin" } }, "filter": { "my_pinyin": { "type": "pinyin", "keep_first_letter": "false", "keep_separate_first_letter": "false", "keep_full_pinyin": "false", "keep_joined_full_pinyin": "false", "keep_none_chinese": "false", "keep_none_chinese_together": "false", "keep_none_chinese_in_first_letter": "false", "keep_none_chinese_in_joined_full_pinyin": "false", "none_chinese_pinyin_tokenize": "false", "keep_original": "false", "lowercase": "false", "trim_whitespace": "false", "remove_duplicated_term": "false" } } } } }
先看一下keyword、ik_smart、ik_max_word对“我们都是中国人。”的分词结果


{ "tokens": [ { "token": "我们都是中国人。", "start_offset": 0, "end_offset": 8, "type": "word", "position": 0 } ] }
{ "tokens": [ { "token": "我们", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "都是", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 1 } , { "token": "中国人", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 2 } ] }
{ "tokens": [ { "token": "我们", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "我", "start_offset": 0, "end_offset": 1, "type": "CN_WORD", "position": 1 } , { "token": "们", "start_offset": 1, "end_offset": 2, "type": "CN_WORD", "position": 2 } , { "token": "都是", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "都", "start_offset": 2, "end_offset": 3, "type": "CN_WORD", "position": 4 } , { "token": "是", "start_offset": 3, "end_offset": 4, "type": "CN_WORD", "position": 5 } , { "token": "中国人", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "中国", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 7 } , { "token": "中", "start_offset": 4, "end_offset": 5, "type": "CN_WORD", "position": 8 } , { "token": "国人", "start_offset": 5, "end_offset": 7, "type": "CN_WORD", "position": 9 } , { "token": "国", "start_offset": 5, "end_offset": 6, "type": "CN_WORD", "position": 10 } , { "token": "人", "start_offset": 6, "end_offset": 7, "type": "CN_WORD", "position": 11 } ] }
首先,全部都设置为false。
使用3个分词器拆分一句话“我们都是中国人。”
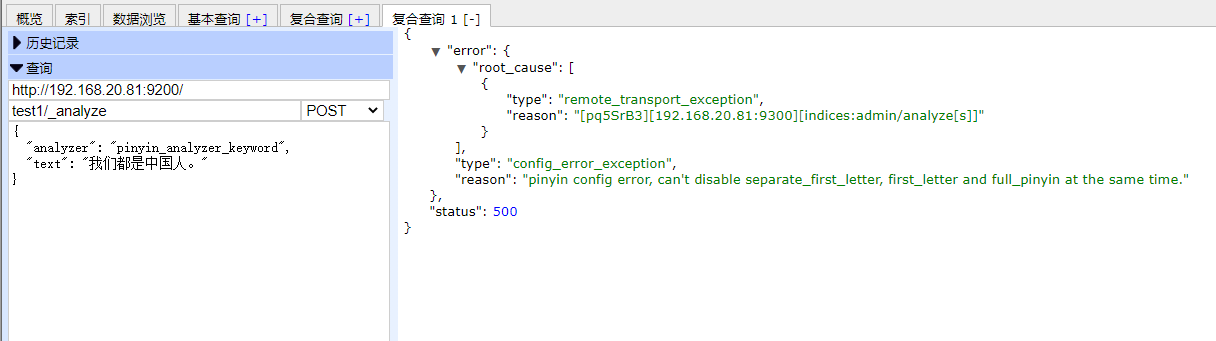
报错了,提示keep_separate_first_letter,keep_first_letter,keep_full_pinyin至少需要有一个为true。
好的,那就先分别把这三个改为true进行测试。
keep_separate_first_letter=true
三个分词结果如下
{ "tokens": [ { "token": "w", "start_offset": 0, "end_offset": 8, "type": "word", "position": 0 } , { "token": "m", "start_offset": 0, "end_offset": 8, "type": "word", "position": 1 } , { "token": "d", "start_offset": 0, "end_offset": 8, "type": "word", "position": 2 } , { "token": "s", "start_offset": 0, "end_offset": 8, "type": "word", "position": 3 } , { "token": "z", "start_offset": 0, "end_offset": 8, "type": "word", "position": 4 } , { "token": "g", "start_offset": 0, "end_offset": 8, "type": "word", "position": 5 } , { "token": "r", "start_offset": 0, "end_offset": 8, "type": "word", "position": 6 } ] }
{ "tokens": [ { "token": "w", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "m", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "d", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 2 } , { "token": "s", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "z", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 4 } , { "token": "g", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 5 } , { "token": "r", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } ] }
{ "tokens": [ { "token": "w", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "m", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "w", "start_offset": 0, "end_offset": 1, "type": "CN_WORD", "position": 2 } , { "token": "m", "start_offset": 1, "end_offset": 2, "type": "CN_WORD", "position": 3 } , { "token": "d", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 4 } , { "token": "s", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 5 } , { "token": "d", "start_offset": 2, "end_offset": 3, "type": "CN_WORD", "position": 6 } , { "token": "s", "start_offset": 3, "end_offset": 4, "type": "CN_WORD", "position": 7 } , { "token": "z", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 8 } , { "token": "g", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 9 } , { "token": "r", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 10 } , { "token": "z", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 11 } , { "token": "g", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 12 } , { "token": "z", "start_offset": 4, "end_offset": 5, "type": "CN_WORD", "position": 13 } , { "token": "g", "start_offset": 5, "end_offset": 7, "type": "CN_WORD", "position": 14 } , { "token": "r", "start_offset": 5, "end_offset": 7, "type": "CN_WORD", "position": 15 } , { "token": "g", "start_offset": 5, "end_offset": 6, "type": "CN_WORD", "position": 16 } , { "token": "r", "start_offset": 6, "end_offset": 7, "type": "CN_WORD", "position": 17 } ] }
可以看到,结果是先根据tokenizer进行分词,然后对分词结果再进行拼音处理。
我们使用分词结果里面的任意一个结果都可以匹配到“我们都是中国人。”这句话。查询结果相关度非常低,所以这个属性,个人建议使用默认值false。
keep_first_letter=true,其余值均为false
分词结果如下
{ "tokens": [ { "token": "wmdszgr", "start_offset": 0, "end_offset": 8, "type": "word", "position": 0 } ] }
{ "tokens": [ { "token": "wm", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "ds", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 1 } , { "token": "zgr", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 2 } ] }
{ "tokens": [ { "token": "wm", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "w", "start_offset": 0, "end_offset": 1, "type": "CN_WORD", "position": 1 } , { "token": "m", "start_offset": 1, "end_offset": 2, "type": "CN_WORD", "position": 2 } , { "token": "ds", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "d", "start_offset": 2, "end_offset": 3, "type": "CN_WORD", "position": 4 } , { "token": "s", "start_offset": 3, "end_offset": 4, "type": "CN_WORD", "position": 5 } , { "token": "zgr", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "zg", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 7 } , { "token": "z", "start_offset": 4, "end_offset": 5, "type": "CN_WORD", "position": 8 } , { "token": "gr", "start_offset": 5, "end_offset": 7, "type": "CN_WORD", "position": 9 } , { "token": "g", "start_offset": 5, "end_offset": 6, "type": "CN_WORD", "position": 10 } , { "token": "r", "start_offset": 6, "end_offset": 7, "type": "CN_WORD", "position": 11 } ] }
通过结果可以看出,keep_first_letter的功能是将分词结果的首字母提取出来,形成最终结果。
keep_full_pinyin=true,其余值均为false的情况。
{ "tokens": [ { "token": "wo", "start_offset": 0, "end_offset": 8, "type": "word", "position": 0 } , { "token": "men", "start_offset": 0, "end_offset": 8, "type": "word", "position": 1 } , { "token": "dou", "start_offset": 0, "end_offset": 8, "type": "word", "position": 2 } , { "token": "shi", "start_offset": 0, "end_offset": 8, "type": "word", "position": 3 } , { "token": "zhong", "start_offset": 0, "end_offset": 8, "type": "word", "position": 4 } , { "token": "guo", "start_offset": 0, "end_offset": 8, "type": "word", "position": 5 } , { "token": "ren", "start_offset": 0, "end_offset": 8, "type": "word", "position": 6 } ] }
{ "tokens": [ { "token": "wo", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "men", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "dou", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 2 } , { "token": "shi", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "zhong", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 4 } , { "token": "guo", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 5 } , { "token": "ren", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } ] }
{ "tokens": [ { "token": "wo", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "men", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "wo", "start_offset": 0, "end_offset": 1, "type": "CN_WORD", "position": 2 } , { "token": "men", "start_offset": 1, "end_offset": 2, "type": "CN_WORD", "position": 3 } , { "token": "dou", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 4 } , { "token": "shi", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 5 } , { "token": "dou", "start_offset": 2, "end_offset": 3, "type": "CN_WORD", "position": 6 } , { "token": "shi", "start_offset": 3, "end_offset": 4, "type": "CN_WORD", "position": 7 } , { "token": "zhong", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 8 } , { "token": "guo", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 9 } , { "token": "ren", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 10 } , { "token": "zhong", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 11 } , { "token": "guo", "start_offset": 4, "end_offset": 6, "type": "CN_WORD", "position": 12 } , { "token": "zhong", "start_offset": 4, "end_offset": 5, "type": "CN_WORD", "position": 13 } , { "token": "guo", "start_offset": 5, "end_offset": 7, "type": "CN_WORD", "position": 14 } , { "token": "ren", "start_offset": 5, "end_offset": 7, "type": "CN_WORD", "position": 15 } , { "token": "guo", "start_offset": 5, "end_offset": 6, "type": "CN_WORD", "position": 16 } , { "token": "ren", "start_offset": 6, "end_offset": 7, "type": "CN_WORD", "position": 17 } ] }
通过结果可以看出,kepp_full_pinyin是将分词结果的每一条数据都拆分成了单字的全拼。
根据这三个属性的说明,已经和分词器的匹配来看。
如果需要做首字母导航或简拼功能的话,可以使用keyword分词器,同时只需开启keep_first_letter属性。
以pinyin_analyzer_ik_smart的分词结果为例,开启keep_full_pinyin和keep_first_letter。
{ "tokens": [ { "token": "wo", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "wm", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "men", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "dou", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 2 } , { "token": "shi", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "ds", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "zhong", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 4 } , { "token": "guo", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 5 } , { "token": "ren", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "zgr", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } ] }
观察之后可以发现,分词结果里都是拼音,那在输入中文进行检索的时候,岂不是无法与分词结果匹配?
回顾一下上面的拼音属性,发现里面有一个 keep_original属性,他的说明是保留原始输入,那么开启他是不是就能保留中文的分词结果呢?话不多说,尝试一下。
设置keep_full_pinyin、keep_first_letter、keep_original为true,其余均为false。
{ "tokens": [ { "token": "wo", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "men", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "我们", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "wm", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "dou", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 2 } , { "token": "shi", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "都是", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "ds", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "zhong", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 4 } , { "token": "guo", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 5 } , { "token": "ren", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "中国人", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "zgr", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } ] }
果不其然,中文被保留了。
观察以上的分词结果,我们发现,这里面少了类似"women""womendoushzhongguoren"这样的的全拼。
那要如何把这个分词结果保留下来呢?
可以开启keep_joined_full_pinyin。
设置keep_full_pinyin、keep_first_letter、keep_original、keep_joined_full_pinyin为true,其余均为false。
{ "tokens": [ { "token": "wo", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "我们", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "women", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "wm", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 } , { "token": "men", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 1 } , { "token": "dou", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 2 } , { "token": "shi", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "都是", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "doushi", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "ds", "start_offset": 2, "end_offset": 4, "type": "CN_WORD", "position": 3 } , { "token": "zhong", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 4 } , { "token": "guo", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 5 } , { "token": "ren", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "中国人", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "zhongguoren", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } , { "token": "zgr", "start_offset": 4, "end_offset": 7, "type": "CN_WORD", "position": 6 } ] }
如此,
如果我们要实现全拼+简拼+中文检索的功能,可以使用合适的分词器,同时开启keep_first_letter,keep_full_pinyin,keep_original,keep_joined_full_pinyin属性。
如果我们要实现搜索提示(建议检索)的功能,可以使用keyword分词器,同时开启keep_first_letter,keep_original,keep_joined_full_pinyin属性。
{ "tokens": [ { "token": "我们都是中国人。", "start_offset": 0, "end_offset": 8, "type": "word", "position": 0 } , { "token": "womendoushizhongguoren", "start_offset": 0, "end_offset": 8, "type": "word", "position": 0 } , { "token": "wmdszgr", "start_offset": 0, "end_offset": 8, "type": "word", "position": 0 } ] }
