Python之路:常用算法与设计模式
选择排序
时间复杂度
|
定义:如果一个问题的规模是n,解这一问题的某一算法所需要的时间为T(n),它是n的某一函数 T(n)称为这一算法的“时间复杂性”。
当输入量n逐渐加大时,时间复杂性的极限情形称为算法的“渐近时间复杂性”。 我们常用大O表示法表示时间复杂性,注意它是某一个算法的时间复杂性。大O表示只是说有上界,由定义如果f(n)=O(n),那显然成立f(n)=O(n^2),它给你一个上界,但并不是上确界,但人们在表示的时候一般都习惯表示前者。 此外,一个问题本身也有它的复杂性,如果某个算法的复杂性到达了这个问题复杂性的下界,那就称这样的算法是最佳算法。 “大O记法”:在这种描述中使用的基本参数是 n,即问题实例的规模,把复杂性或运行时间表达为n的函数。这里的“O”表示量级 (order),比如说“二分检索是 O(logn)的”,也就是说它需要“通过logn量级的步骤去检索一个规模为n的数组”记法 O ( f(n) )表示当 n增大时,运行时间至多将以正比于 f(n)的速度增长。 这种渐进估计对算法的理论分析和大致比较是非常有价值的,但在实践中细节也可能造成差异。例如,一个低附加代价的O(n2)算法在n较小的情况下可能比一个高附加代价的 O(nlogn)算法运行得更快。当然,随着n足够大以后,具有较慢上升函数的算法必然工作得更快。 O(1) Temp=i;i=j;j=temp; 以上三条单个语句的频度均为1,该程序段的执行时间是一个与问题规模n无关的常数。算法的时间复杂度为常数阶,记作T(n)=O(1)。如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)。 O(n^2) 2.1. 交换i和j的内容 sum=0; (一次) for(i=1;i<=n;i++) (n次 ) for(j=1;j<=n;j++) (n^2次 ) sum++; (n^2次 ) 解:T(n)=2n^2+n+1 =O(n^2) 2.2. for (i=1;i<n;i++) { y=y+1; ① for (j=0;j<=(2*n);j++) x++; ② } 解: 语句1的频度是n-1 语句2的频度是(n-1)*(2n+1)=2n^2-n-1 f(n)=2n^2-n-1+(n-1)=2n^2-2 该程序的时间复杂度T(n)=O(n^2). O(n) 2.3. a=0; b=1; ① for (i=1;i<=n;i++) ② { s=a+b; ③ b=a; ④ a=s; ⑤ } 解:语句1的频度:2, 语句2的频度: n, 语句3的频度: n-1, 语句4的频度:n-1, 语句5的频度:n-1, T(n)=2+n+3(n-1)=4n-1=O(n). O(log2n ) 2.4. i=1; ① while (i<=n) i=i*2; ② 解: 语句1的频度是1, 设语句2的频度是f(n), 则:2^f(n)<=n;f(n)<=log2n 取最大值f(n)= log2n, T(n)=O(log2n ) O(n^3) 2.5. for(i=0;i<n;i++) { for(j=0;j<i;j++) { for(k=0;k<j;k++) x=x+2; } } 解:当i=m, j=k的时候,内层循环的次数为k当i=m时, j 可以取 0,1,...,m-1 , 所以这里最内循环共进行了0+1+...+m-1=(m-1)m/2次所以,i从0取到n, 则循环共进行了: 0+(1-1)*1/2+...+(n-1)n/2=n(n+1)(n-1)/6所以时间复杂度为O(n^3). 我们还应该区分算法的最坏情况的行为和期望行为。如快速排序的最 坏情况运行时间是 O(n^2),但期望时间是 O(nlogn)。通过每次都仔细 地选择基准值,我们有可能把平方情况 (即O(n^2)情况)的概率减小到几乎等于 0。在实际中,精心实现的快速排序一般都能以 (O(nlogn)时间运行。 下面是一些常用的记法: 访问数组中的元素是常数时间操作,或说O(1)操作。一个算法如 果能在每个步骤去掉一半数据元素,如二分检索,通常它就取 O(logn)时间。用strcmp比较两个具有n个字符的串需要O(n)时间。常规的矩阵乘算法是O(n^3),因为算出每个元素都需要将n对 元素相乘并加到一起,所有元素的个数是n^2。 指数时间算法通常来源于需要求出所有可能结果。例如,n个元 素的集合共有2n个子集,所以要求出所有子集的算法将是O(2n)的。指数算法一般说来是太复杂了,除非n的值非常小,因为,在 这个问题中增加一个元素就导致运行时间加倍。不幸的是,确实有许多问题 (如著名的“巡回售货员问题” ),到目前为止找到的算法都是指数的。如果我们真的遇到这种情况,通常应该用寻找近似最佳结果的算法替代之。 |
常用排序
|
名称 |
复杂度 |
说明 |
备注 |
|
冒泡排序 |
O(N*N) |
将待排序的元素看作是竖着排列的“气泡”,较小的元素比较轻,从而要往上浮 |
|
|
插入排序 Insertion sort |
O(N*N) |
逐一取出元素,在已经排序的元素序列中从后向前扫描,放到适当的位置 |
起初,已经排序的元素序列为空 |
|
选择排序 |
O(N*N) |
首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。以此递归。 |
|
|
快速排序 Quick Sort |
O(n *log2(n)) |
先选择中间值,然后把比它小的放在左边,大的放在右边(具体的实现是从两边找,找到一对后交换)。然后对两边分别使用这个过程(递归)。 |
|
|
堆排序HeapSort |
O(n *log2(n)) |
利用堆(heaps)这种数据结构来构造的一种排序算法。堆是一个近似完全二叉树结构,并同时满足堆属性:即子节点的键值或索引总是小于(或者大于)它的父节点。 |
近似完全二叉树 |
|
希尔排序 SHELL |
O(n1+£) 0<£<1 |
选择一个步长(Step) ,然后按间隔为步长的单元进行排序.递归,步长逐渐变小,直至为1. |
|
|
箱排序 |
O(n) |
设置若干个箱子,把关键字等于 k 的记录全都装入到第k 个箱子里 ( 分配 ) ,然后按序号依次将各非空的箱子首尾连接起来 ( 收集 ) 。 |
分配排序的一种:通过" 分配 " 和 " 收集 " 过程来实现排序。 |
选择排序
The algorithm works by selecting the smallest unsorted item and then swapping it with the item in the next position to be filled.
The selection sort works as follows: you look through the entire array for the smallest element, once you find it you swap it (the smallest element) with the first element of the array. Then you look for the smallest element in the remaining array (an array without the first element) and swap it with the second element. Then you look for the smallest element in the remaining array (an array without first and second elements) and swap it with the third element, and so on. Here is an example,
<code class="python plain">source </code><code class="python keyword">=</code> <code class="python plain">[</code><code class="python value">29</code><code class="python plain">,</code><code class="python value">64</code><code class="python plain">,</code><code class="python value">73</code><code class="python plain">,</code><code class="python value">34</code><code class="python plain">,</code><code class="python value">20</code><code class="python plain">]</code>
count = 0
for i in range(len(source)):
for j in range(i,len(source)):
source_ele = source[i] #要被拿来对比且替换的原始值
if source[j] < source_ele : #只要这个列表后面的值比最前面的值大,那就把它俩个做个对调
source[i] = source[j]
source[j] = source_ele
count +=1
print(source)
print("运行次数:",count)
Example.
29, 64, 73, 34, 20,
20, 64, 73, 34, 29,
20, 29, 73, 34, 64
20, 29, 34, 73, 64
20, 29, 34, 64, 73
The worst-case runtime complexity is O(n2).
插入排序(Insertion Sort)
插入排序(Insertion Sort)的基本思想是:将列表分为2部分,左边为排序好的部分,右边为未排序的部分,循环整个列表,每次将一个待排序的记录,按其关键字大小插入到前面已经排好序的子序列中的适当位置,直到全部记录插入完成为止。
source = [92, 77, 67, 8, 6, 84, 55, 85, 43, 67]
for index in range(1,len(source)):
current_val = source[index] #先记下来每次大循环走到的第几个元素的值
position = index
while position > 0 and source[position-1] > current_val: #当前元素的左边的紧靠的元素比它大,要把左边的元素一个一个的往右移一位,给当前这个值插入到左边挪一个位置出来
source[position] = source[position-1] #把左边的一个元素往右移一位
position -= 1 #只一次左移只能把当前元素一个位置 ,还得继续左移只到此元素放到排序好的列表的适当位置 为止
source[position] = current_val #已经找到了左边排序好的列表里不小于current_val的元素的位置,把current_val放在这里
print(source)
结果:
[77, 92, 67, 8, 6, 84, 55, 85, 43, 67]
[67, 77, 92, 8, 6, 84, 55, 85, 43, 67]
[8, 67, 77, 92, 6, 84, 55, 85, 43, 67]
[6, 8, 67, 77, 92, 84, 55, 85, 43, 67]
[6, 8, 67, 77, 84, 92, 55, 85, 43, 67]
[6, 8, 55, 67, 77, 84, 92, 85, 43, 67]
[6, 8, 55, 67, 77, 84, 85, 92, 43, 67]
[6, 8, 43, 55, 67, 77, 84, 85, 92, 67]
[6, 8, 43, 55, 67, 67, 77, 84, 85, 92]
快速排序(quick sort)
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动
注:在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的;若具有相同关键字的记录之间的相对次序发生改变,则称这种排序方法是不稳定的。
要注意的是,排序算法的稳定性是针对所有输入实例而言的。即在所有可能的输入实例中,只要有一个实例使得算法不满足稳定性要求,则该排序算法就是不稳定的。
排序演示
示例
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
|
数据
|
6
|
2
|
7
|
3
|
8
|
9
|
|
下标
|
0
|
1
|
2
|
3 |
4
|
5
|
|
数据
|
3
|
2
|
7
|
6
|
8
|
9
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
|
数据
|
3
|
2
|
6
|
7
|
8
|
9
|
|
下标
|
0
|
1
|
2
|
3
|
4
|
5
|
|
数据
|
3
|
2
|
6
|
7
|
8
|
9
|


1 #_*_coding:utf-8_*_ 2 3 4 def quick_sort(array,left,right): 5 ''' 6 7 :param array: 8 :param left: 列表的第一个索引 9 :param right: 列表最后一个元素的索引 10 :return: 11 ''' 12 if left >=right: 13 return 14 low = left 15 high = right 16 key = array[low] #第一个值 17 18 while low < high:#只要左右未遇见 19 while low < high and array[high] > key: #找到列表右边比key大的值 为止 20 high -= 1 21 #此时直接 把key(array[low]) 跟 比它大的array[high]进行交换 22 array[low] = array[high] 23 array[high] = key 24 25 26 while low < high and array[low] <= key : #找到key左边比key大的值 27 low += 1 28 #array[low] = 29 #找到了左边比k大的值 ,把array[high](此时应该刚存成了key) 跟这个比key大的array[low]进行调换 30 array[high] = array[low] 31 array[low] = key 32 33 quick_sort(array,left,low-1) #最后用同样的方式对分出来的左边的小组进行同上的做法 34 quick_sort(array,low+1, right)#用同样的方式对分出来的右边的小组进行同上的做法 35 36 37 38 if __name__ == '__main__': 39 40 array = [96,14,10,9,6,99,16,5,1,3,2,4,1,13,26,18,2,45,34,23,1,7,3,22,19,2] 41 #array = [8,4,1, 14, 6, 2, 3, 9,5, 13, 7,1, 8,10, 12] 42 print("before sort:", array) 43 quick_sort(array,0,len(array)-1) 44 45 print("-------final -------") 46 print(array)
二叉树
树的特征和定义
树(Tree)是元素的集合。我们先以比较直观的方式介绍树。下面的数据结构是一个树:
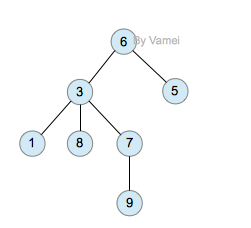
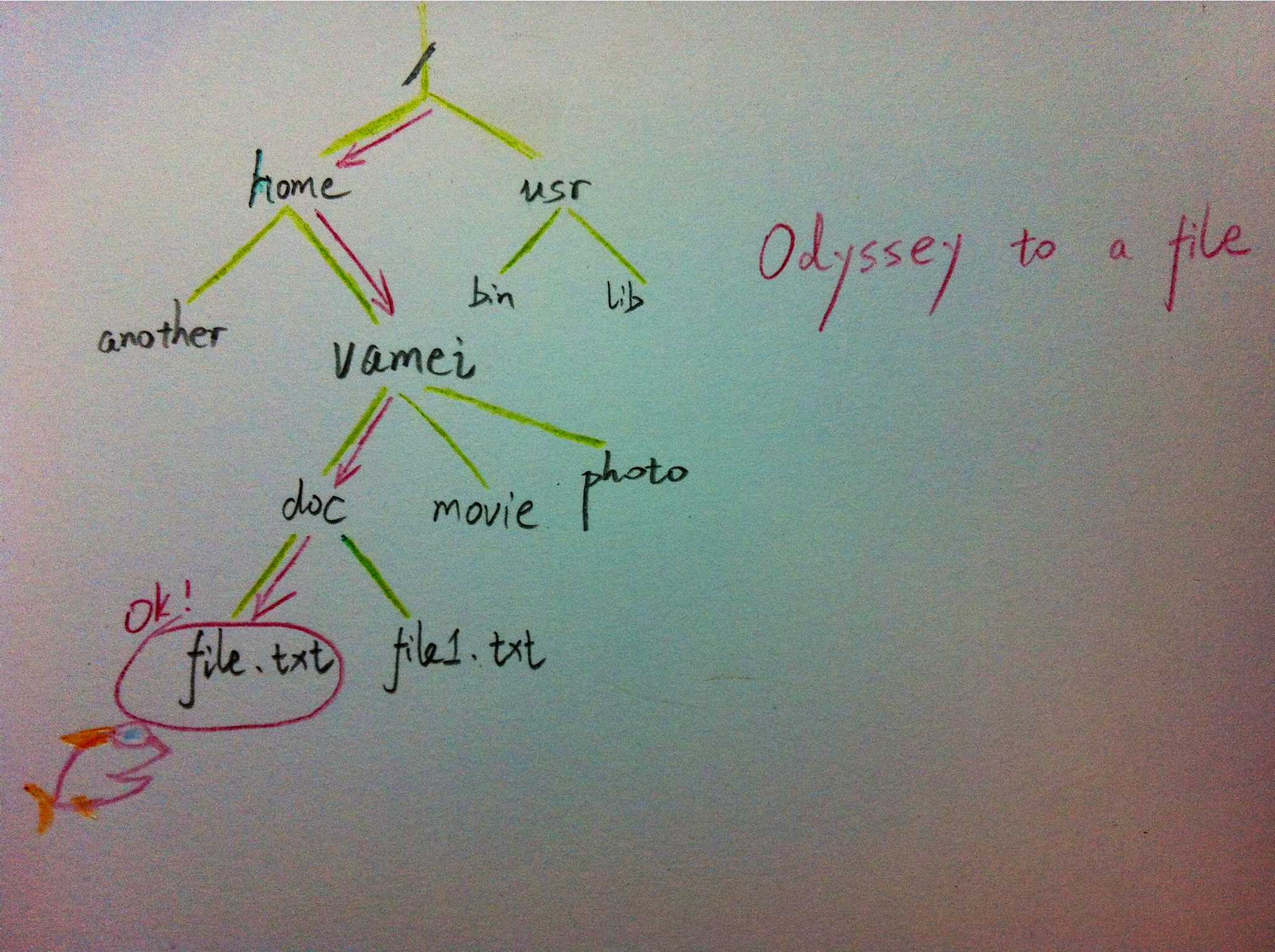
树有多个节点(node),用以储存元素。某些节点之间存在一定的关系,用连线表示,连线称为边(edge)。边的上端节点称为父节点,下端称为子节点。树像是一个不断分叉的树根。
每个节点可以有多个子节点(children),而该节点是相应子节点的父节点(parent)。比如说,3,5是6的子节点,6是3,5的父节点;1,8,7是3的子节点, 3是1,8,7的父节点。树有一个没有父节点的节点,称为根节点(root),如图中的6。没有子节点的节点称为叶节点(leaf),比如图中的1,8,9,5节点。从图中还可以看到,上面的树总共有4个层次,6位于第一层,9位于第四层。树中节点的最大层次被称为深度。也就是说,该树的深度(depth)为4。
如果我们从节点3开始向下看,而忽略其它部分。那么我们看到的是一个以节点3为根节点的树:
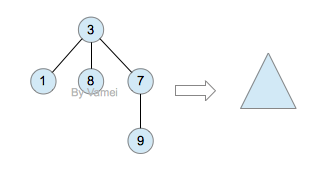
三角形代表一棵树
再进一步,如果我们定义孤立的一个节点也是一棵树的话,原来的树就可以表示为根节点和子树(subtree)的关系:
上述观察实际上给了我们一种严格的定义树的方法:
1. 树是元素的集合。
2. 该集合可以为空。这时树中没有元素,我们称树为空树 (empty tree)。
3. 如果该集合不为空,那么该集合有一个根节点,以及0个或者多个子树。根节点与它的子树的根节点用一个边(edge)相连。
上面的第三点是以递归的方式来定义树,也就是在定义树的过程中使用了树自身(子树)。由于树的递归特征,许多树相关的操作也可以方便的使用递归实现。我们将在后面看到。
树的实现
树的示意图已经给出了树的一种内存实现方式: 每个节点储存元素和多个指向子节点的指针。然而,子节点数目是不确定的。一个父节点可能有大量的子节点,而另一个父节点可能只有一个子节点,而树的增删节点操作会让子节点的数目发生进一步的变化。这种不确定性就可能带来大量的内存相关操作,并且容易造成内存的浪费。
一种经典的实现方式如下:
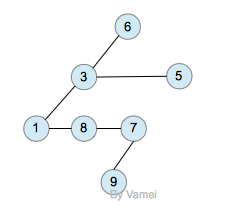
树的内存实现
拥有同一父节点的两个节点互为兄弟节点(sibling)。上图的实现方式中,每个节点包含有一个指针指向第一个子节点,并有另一个指针指向它的下一个兄弟节点。这样,我们就可以用统一的、确定的结构来表示每个节点。
计算机的文件系统是树的结构,比如Linux文件管理背景知识中所介绍的。在UNIX的文件系统中,每个文件(文件夹同样是一种文件),都可以看做是一个节点。非文件夹的文件被储存在叶节点。文件夹中有指向父节点和子节点的指针(在UNIX中,文件夹还包含一个指向自身的指针,这与我们上面见到的树有所区别)。在git中,也有类似的树状结构,用以表达整个文件系统的版本变化 (参考版本管理三国志)。
二叉树:
二叉树是由n(n≥0)个结点组成的有限集合、每个结点最多有两个子树的有序树。它或者是空集,或者是由一个根和称为左、右子树的两个不相交的二叉树组成。
特点:
(1)二叉树是有序树,即使只有一个子树,也必须区分左、右子树;
(2)二叉树的每个结点的度不能大于2,只能取0、1、2三者之一;
(3)二叉树中所有结点的形态有5种:空结点、无左右子树的结点、只有左子树的结点、只有右子树的结点和具有左右子树的结点。

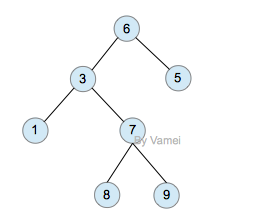
二叉树(binary)是一种特殊的树。二叉树的每个节点最多只能有2个子节点:
二叉树
由于二叉树的子节点数目确定,所以可以直接采用上图方式在内存中实现。每个节点有一个左子节点(left children)和右子节点(right children)。左子节点是左子树的根节点,右子节点是右子树的根节点。
如果我们给二叉树加一个额外的条件,就可以得到一种被称作二叉搜索树(binary search tree)的特殊二叉树。二叉搜索树要求:每个节点都不比它左子树的任意元素小,而且不比它的右子树的任意元素大。
(如果我们假设树中没有重复的元素,那么上述要求可以写成:每个节点比它左子树的任意节点大,而且比它右子树的任意节点小)
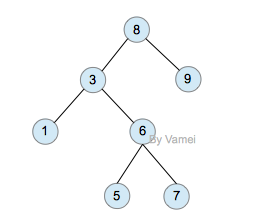
二叉搜索树,注意树中元素的大小
二叉搜索树可以方便的实现搜索算法。在搜索元素x的时候,我们可以将x和根节点比较:
1. 如果x等于根节点,那么找到x,停止搜索 (终止条件)
2. 如果x小于根节点,那么搜索左子树
3. 如果x大于根节点,那么搜索右子树
二叉搜索树所需要进行的操作次数最多与树的深度相等。n个节点的二叉搜索树的深度最多为n,最少为log(n)。
二叉树的遍历
遍历即将树的所有结点访问且仅访问一次。按照根节点位置的不同分为前序遍历,中序遍历,后序遍历。
前序遍历:根节点->左子树->右子树
中序遍历:左子树->根节点->右子树
后序遍历:左子树->右子树->根节点
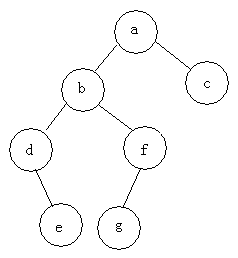
例如:求下面树的三种遍历
前序遍历:abdefgc
中序遍历:debgfac
后序遍历:edgfbca
二叉树的类型
如何判断一棵树是完全二叉树?按照定义,
教材上的说法:一个深度为k,节点个数为 2^k - 1 的二叉树为满二叉树。这个概念很好理解,
就是一棵树,深度为k,并且没有空位。
首先对满二叉树按照广度优先遍历(从左到右)的顺序进行编号。
一颗深度为k二叉树,有n个节点,然后,也对这棵树进行编号,如果所有的编号都和满二叉树对应,那么这棵树是完全二叉树。

如何判断平衡二叉树?

(b)左边的图 左子数的高度为3,右子树的高度为1,相差超过1
(b)右边的图 -2的左子树高度为0 右子树的高度为2,相差超过1
二叉树遍历实现
1 class TreeNode(object): 2 def __init__(self,data=0,left=0,right=0): 3 self.data = data 4 self.left = left 5 self.right = right 6 7 class BTree(object): 8 def __init__(self,root=0): 9 self.root = root 10 11 12 def preOrder(self,treenode): 13 if treenode is 0: 14 return 15 print(treenode.data) 16 self.preOrder(treenode.left) 17 self.preOrder(treenode.right) 18 def inOrder(self,treenode): 19 if treenode is 0: 20 return 21 self.inOrder(treenode.left) 22 print(treenode.data) 23 self.inOrder(treenode.right) 24 25 def postOrder(self,treenode): 26 if treenode is 0: 27 return 28 self.postOrder(treenode.left) 29 self.postOrder(treenode.right) 30 print(treenode.data) 31 if __name__ == '__main__': 32 n1 = TreeNode(data=1) 33 n2 = TreeNode(2,n1,0) 34 n3 = TreeNode(3) 35 n4 = TreeNode(4) 36 n5 = TreeNode(5,n3,n4) 37 n6 = TreeNode(6,n2,n5) 38 n7 = TreeNode(7,n6,0) 39 n8 = TreeNode(8) 40 root = TreeNode('root',n7,n8) 41 42 bt = BTree(root) 43 print("preOrder".center(50,'-')) 44 print(bt.preOrder(bt.root)) 45 46 print("inOrder".center(50,'-')) 47 print (bt.inOrder(bt.root)) 48 49 print("postOrder".center(50,'-')) 50 print (bt.postOrder(bt.root))
堆排序
堆排序,顾名思义,就是基于堆。因此先来介绍一下堆的概念。
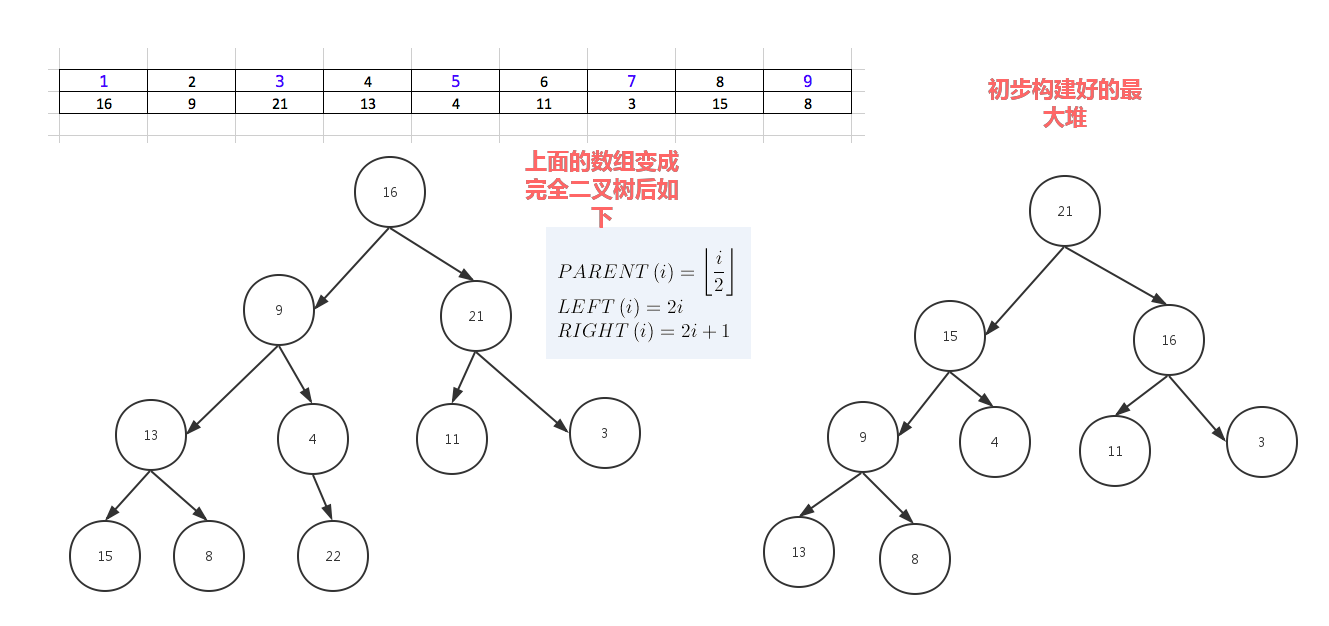
堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要大于其孩子,最小堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求,其实很好理解。有了上面的定义,我们可以得知,处于最大堆的根节点的元素一定是这个堆中的最大值。其实我们的堆排序算法就是抓住了堆的这一特点,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
1 #_*_coding:utf-8_*_ 2 __author__ = 'Alex Li' 3 import time,random 4 def sift_down(arr, node, end): 5 root = node 6 #print(root,2*root+1,end) 7 while True: 8 # 从root开始对最大堆调整 9 10 child = 2 * root +1 #left child 11 if child > end: 12 #print('break',) 13 break 14 print("v:",root,arr[root],child,arr[child]) 15 print(arr) 16 # 找出两个child中交大的一个 17 if child + 1 <= end and arr[child] < arr[child + 1]: #如果左边小于右边 18 child += 1 #设置右边为大 19 20 if arr[root] < arr[child]: 21 # 最大堆小于较大的child, 交换顺序 22 tmp = arr[root] 23 arr[root] = arr[child] 24 arr[child]= tmp 25 26 # 正在调整的节点设置为root 27 #print("less1:", arr[root],arr[child],root,child) 28 29 root = child # 30 #[3, 4, 7, 8, 9, 11, 13, 15, 16, 21, 22, 29] 31 #print("less2:", arr[root],arr[child],root,child) 32 else: 33 # 无需调整的时候, 退出 34 break 35 #print(arr) 36 print('-------------') 37 38 def heap_sort(arr): 39 # 从最后一个有子节点的孩子还是调整最大堆 40 first = len(arr) // 2 -1 41 for i in range(first, -1, -1): 42 sift_down(arr, i, len(arr) - 1) 43 #[29, 22, 16, 9, 15, 21, 3, 13, 8, 7, 4, 11] 44 print('--------end---',arr) 45 # 将最大的放到堆的最后一个, 堆-1, 继续调整排序 46 for end in range(len(arr) -1, 0, -1): 47 arr[0], arr[end] = arr[end], arr[0] 48 sift_down(arr, 0, end - 1) 49 #print(arr) 50 def main(): 51 # [7, 95, 73, 65, 60, 77, 28, 62, 43] 52 # [3, 1, 4, 9, 6, 7, 5, 8, 2, 10] 53 #l = [3, 1, 4, 9, 6, 7, 5, 8, 2, 10] 54 #l = [16,9,21,13,4,11,3,22,8,7,15,27,0] 55 array = [16,9,21,13,4,11,3,22,8,7,15,29] 56 #array = [] 57 #for i in range(2,5000): 58 # #print(i) 59 # array.append(random.randrange(1,i)) 60 61 print(array) 62 start_t = time.time() 63 heap_sort(array) 64 end_t = time.time() 65 print("cost:",end_t -start_t) 66 print(array) 67 #print(l) 68 #heap_sort(l) 69 #print(l) 70 71 72 if __name__ == "__main__": 73 main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号