K-Means算法及代码实现
1.K-Means算法
K-Means算法,也被称为K-平均或K-均值算法,是一种广泛使用的聚类算法。K-Means算法是聚焦于相似的无监督的算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。之所以被称为K-Means是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
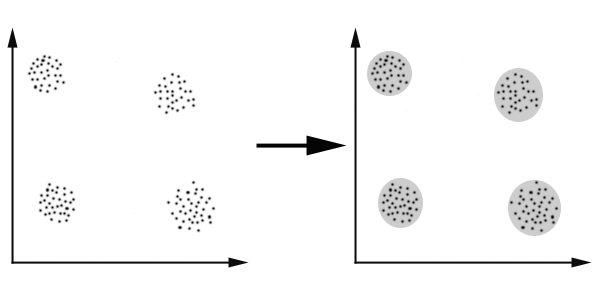
2.聚类的概念
聚类,则是给定的样本没有事先确定类别,根据自己需要,确定类别数量,再把样本归到不同的类别里面。也就是说,同样是垃圾分类的例子,你给一堆垃圾,我可以根据可回收、不可回收分为聚类为两堆;也可以根据可回收、不可回收、厨余垃圾聚类为三堆。而其中聚类为同一堆的条件,我们可以理解为垃圾间的相似程度。
3.k-means算法思想
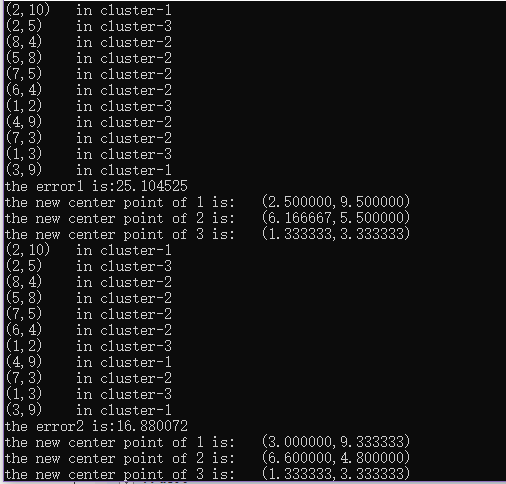
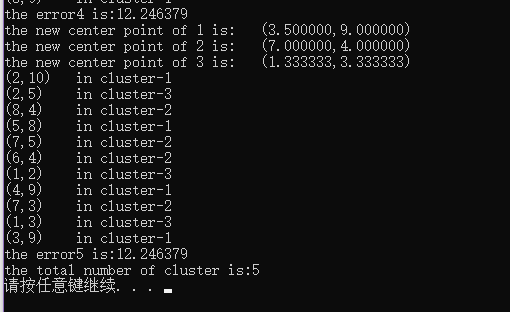
1.从数据集中随机选取k个数据对象作为k个簇的初始聚类中心点,且每个数据对象对应于一个簇;
2.将剩余的数据对象根据其与各个簇中心点的距离,分别指派到离其距离最近的簇中;
3.更新每个簇的聚类中心(即重新计算各个簇内所有对象的平均值,重新分配各个数据对象);
4.直到准则函数收敛或者聚类中心不再变化,否则转到step3。
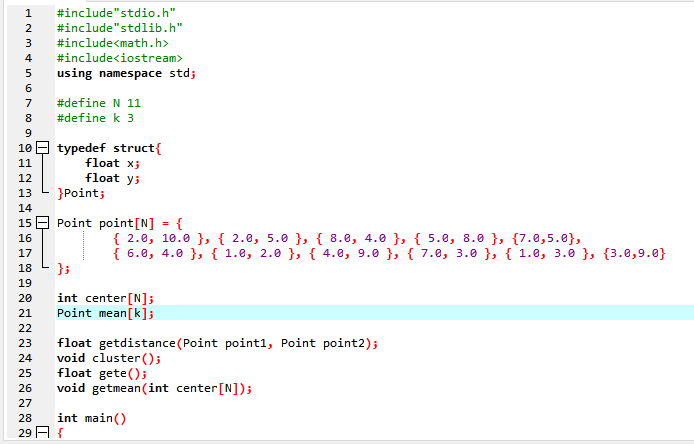
4. 代码实现

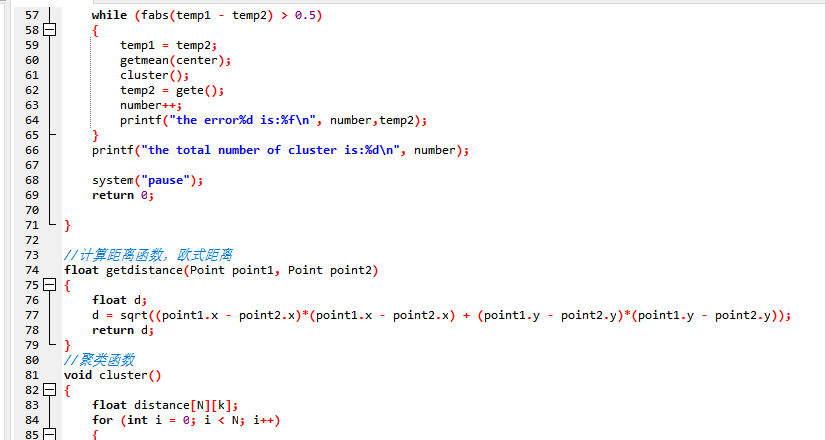

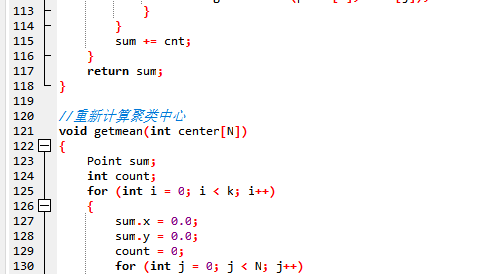

运行结果: