思路:找到cluster id 和 分配的id -----启动单点的pd-------pd-recover修复pd-------恢复成pd集群-----强制删除多个pd-------启动tidb集群
1、pd的日志报错
[root@localhost log]# pwd /tidb-deploy/pd-2379/log
[root@localhost log]# tail -100f pd.log
["failed to recover v3 backend from snapshot"] [error="failed to find database snapshot file (snap: snapshot file doesn't exist)"]
2、一.获取 Cluster ID
从 PD 日志获取 Cluster ID
cd /tidb-deploy/pd-2379/log/
cat pd.log | grep "init cluster id"
[2022/04/20 12:23:07.079 +08:00] [INFO] [server.go:358] ["init cluster id"] [cluster-id=7195834538672150139]
二.获取已分配 ID 在指定已分配 ID 时,需指定一个比当前最大的已分配 ID 更大的值。可以从监控中获取已分配 ID,也可以直接在服务器上查看日志。
cat pd*.log | grep "idAllocator allocates a new id" | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r -n | head -n 1
3000
3、修改116的pd 改为单节点pd (最好找数据最齐全的pd节点,看到小等方式)
[root@localhost bin]# more /etc/systemd/system/pd-2379.service
[Unit]
Description=pd service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
LimitSTACK=10485760
User=tidb
ExecStart=/tidb-deploy/pd-2379/scripts/run_pd.sh
Restart=always
RestartSec=15s
[Install]
WantedBy=multi-user.target
[root@localhost bin]# cd /tidb-deploy/pd-2379/scripts/
[root@localhost scripts]# ls
run_pd.sh run_pd.sh.danjiedian
[root@localhost scripts]# more run_pd.sh.danjiedian
#!/bin/bash
set -e
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
DEPLOY_DIR=/tidb-deploy/pd-2379
cd "${DEPLOY_DIR}" || exit 1
exec bin/pd-server \
--name="pd-192.168.10.116-2379" \
--client-urls="http://0.0.0.0:2379" \
--advertise-client-urls="http://192.168.10.116:2379" \
--peer-urls="http://0.0.0.0:2380" \
--advertise-peer-urls="http://192.168.10.116:2380" \
--data-dir="/tidb-data/pd-2379" \
# --initial-cluster="pd-192.168.10.116-2379=http://192.168.10.116:2380,pd-192.168.10.117-2379=http://192.168.10.117:2380,pd-192.168.10.118-2379=http://192.168.10.118:2380" \
--config=conf/pd.toml \
--log-file="/tidb-deploy/pd-2379/log/pd.log" 2>> "/tidb-deploy/pd-2379/log/pd_stderr.log"
删除pd的数据
[root@localhost tidb-data]# pwd
/tidb-data
[root@localhost tidb-data]# mv pd-2379 pd-2379bak/
[tidb@localhost tidb-data]# mkdir pd-2379
启动pd
systemctl start pd-2379
4、下载pd-recover 进行pd修复(集群相同版本工具)
工具包下载地址:https://download.pingcap.org/tidb-community-toolkit-v5.4.1-linux-amd64.tar.gz
2.使用 pd-recover
cd /tidb-deploy/pd-2379/bin
./pd-recover -endpoints http://192.168.10.166:2379 -cluster-id 7195834538672150139 -alloc-id 3000
5、停止pd,还原成集群,查看tidb集群中pd是否启动
systemctl stop pd-2379
mv run_pd.sh.bak run_pd.sh
systemctl start pd-2379
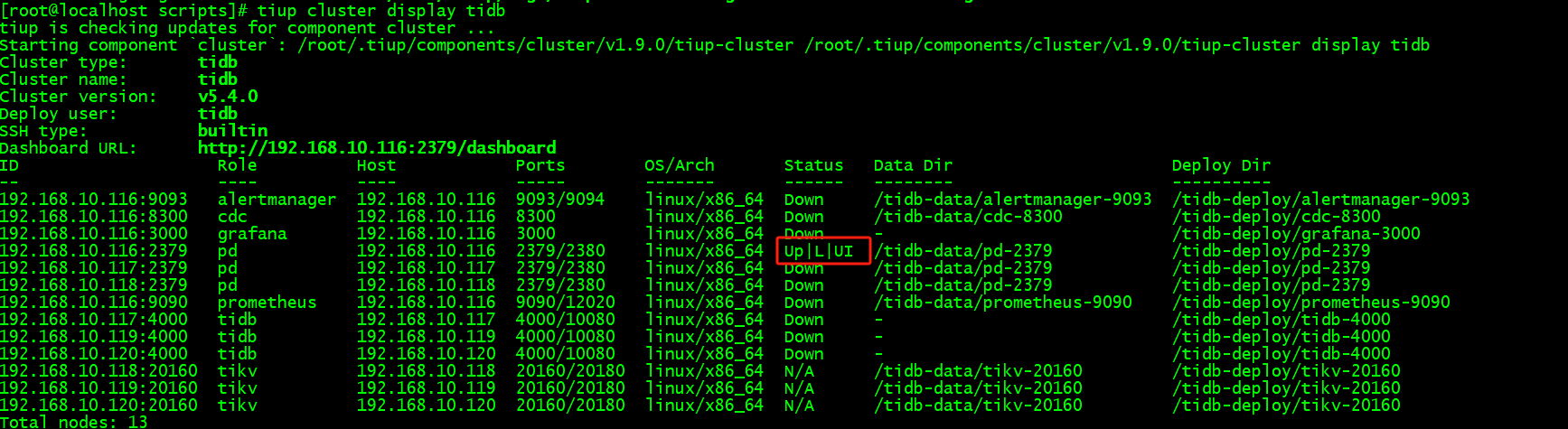
#查看集群pd是否启动
tiup cluster display tidb
5、强制剔除其他的pd,形成单接单pd运行
[root@localhost scripts]# tiup cluster scale-in tidb --node 192.168.10.117:2379 --force
#注意输入:
Are you sure to continue?
(Type "Yes, I know my data might be lost." to continue)
: Yes, I know my data might be lost.
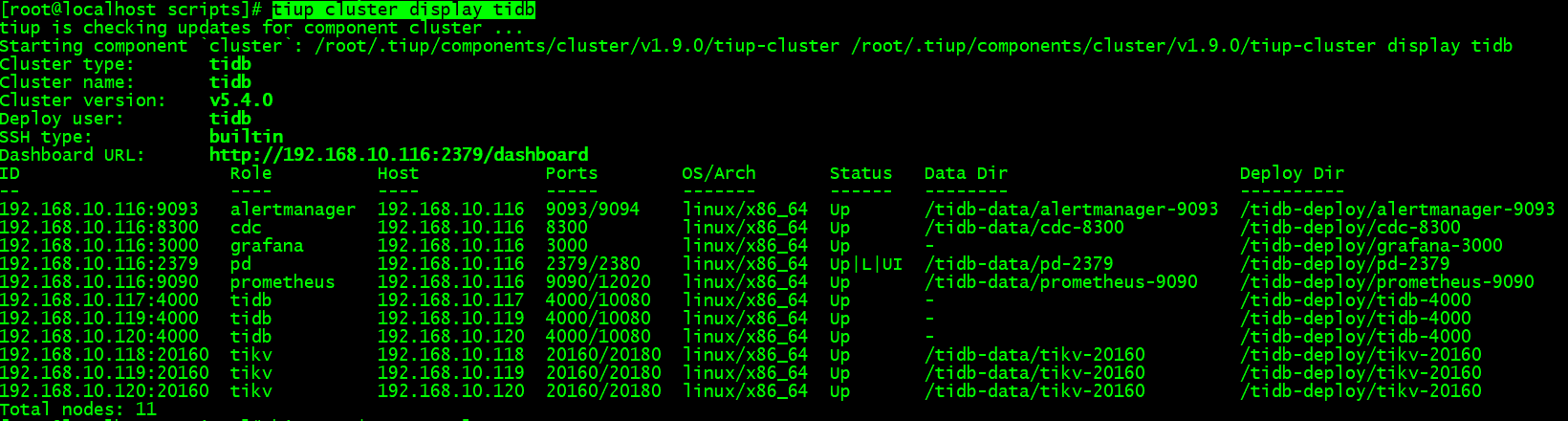
6、启动验证集群,连接数据库查看数据
[root@localhost scripts]# tiup cluster start tidb
[root@localhost scripts]# tiup cluster display tidb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号