python爬取网站内容保存到文件
1、保存网站内容到文件
知识点:
1、BeautifulSoup 的html5lib 以网页方式展示内容
2、网页打开设置字符集 response_new.encoding = 'UTF-8'
2、文件打开设置字符集 encoding="UTF-8"
3、python对字符串进行处理 ,取list最后一个值soup_new.h1.string.split(":")[-1]
4、获取异常 try ;except
![0]()
import requests #数据请求模块 第三方模块 pip install requests
from bs4 import BeautifulSoup
heads = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
def get_response(html_url):
response = requests.get(url=html_url, headers=heads)
return response
def wy_content(url):
response_new = get_response(html_url=url)
response_new.encoding = 'UTF-8'
soup = BeautifulSoup(response_new.text, 'html5lib')
return soup
for name in range(4,9):
url='https://www.python100.com/html/139'+str(name)+'.html'
soup_new = wy_content(url)
file_name = soup_new.h1.string.split(":")[-1] #获取h1标题,对它进行字符串处理
try:
#以utf-8字符打开文件
with open('file/' + file_name + '.txt', mode='a+', encoding="UTF-8") as f:
f.write(soup_new.text)
except Exception as e:
print(e)
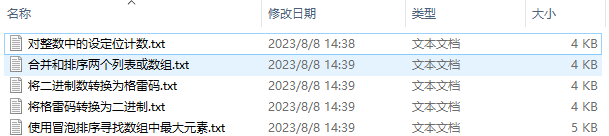
2、结果展示
做一个决定,并不难,难的是付诸行动,并且坚持到底。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号