hadoop-ha-hbase-storm-kafka集群部署
hadoop集群安装
系统整体规划
|
序号 |
Ip |
Host |
程序 |
|
1 |
10.64.39.140 |
NN |
Hadoop、hbase |
|
2 |
10.64.39.142 |
SNN |
Hadoop、hbase |
|
3 |
10.64.39.143 |
DN1 |
Hadoop、hbase、zookeeper、storm、kafka |
|
4 |
10.64.39.144 |
DN2 |
Hadoop、hbase 、zookeeper、storm、kafka |
|
5 |
10.64.39.145 |
DN3 |
Hadoop、hbase、zookeeper、storm、kafka |
1.3 系统初始化环境配置
1、所有服务器时间配置同步
|
# echo 'CST-8'>> /etc/localtime #echo '10.64.39.3'>>/etc/ntp.conf |
2、启动服务
|
service ntpd start |
3、设置自动启动
|
Chkconfig ntpd on |
1.4 Hadoop 2.2 集群划分
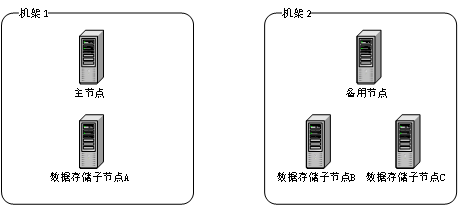
1.5 HDFS HA部署架构图
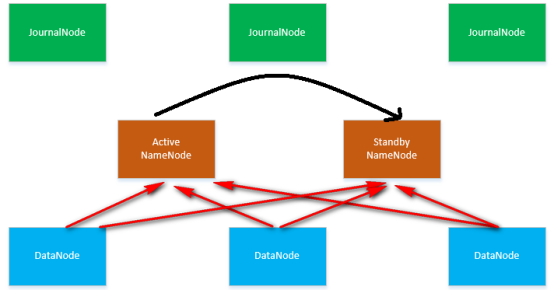
1.6 主机清单
本手册假设Hadoop集群由5台主机组成,主机配置如下:
|
序号 |
节点类型 |
主机名 |
IP地址 |
操作系统环境及硬件配置 |
|
1 |
主节点 |
NN |
10.64.39.140 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:60G 划分数据存储容量:100G+2T |
|
2 |
数据节点1 |
DN1 |
10.64.39.143 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
|
3 |
备用节点 |
SNN |
10.64.39.142 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:60G 划分数据存储容量:100G+2T |
|
4 |
数据节点2 |
DN2 |
10.64.39.144 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
|
5 |
数据节点3 |
DN3 |
10.64.39.145 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
1.7 修改主机名
对5台主机分别执行以下操作修改主机名,对应主机名见2.4节的表格。
(1) 以root身份执行,修改文件/etc/sysconfig/network:
指令:
|
# vi /etc/sysconfig/network |
修改以下内容:
|
NETWORKING=yes HOSTNAME=【主机名】 |
(2) 重新启动主机使配置生效。
【注意】:Redhat7.0修改主机名方式有所不同,指令如下:
查看主机名相关的设置:hostnamectl status
永久修改主机名:sudo hostnamectl --static set-hostname <new-host-name>
1.8 更改IP地址
检查网络IP配置:ifconfig
修改IP地址:vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
当前是DHCP,如果要使用静态IP,修改:
BOOTPROTO=static
ONBOOT=yes #开启自动启用网络连接
增加:
IPADDR0=192.168.1.101 #设置IP地址
PREFIXO0=255.255.255.0 #设置子网掩码
GATEWAY0=192.168.1.1 #设置网关
完成后,重新启动网络服务:service network restart
1.9 配置hosts列表
修改文件/etc/hosts,配置每个主机的IP地址,指令如下:
|
# vi /etc/hosts |
增加或修改以下内容:

1.10 关闭防火墙
5台服务器上的防火墙均需关闭。相关指令如下:
查看防火墙状态:
|
# service itables status |
关闭防火墙:
|
# service iptables stop |
永久关闭防火墙:
|
# chkconfig iptables off |
【注意】:Redhat7.0防火墙关闭方式有所不同,指令如下:
查看防火墙状态:systemctl status firewalld
查看防火墙是否处于活动状态:systemctl is-active firewalld
关闭防火墙:systemctl stop firewalld
永久关闭防火墙:systemctl disable firewalld
打开防火墙命令:systemctl enable firewalld
启动防火墙:systemctl start firewalld
1.11 创建用户账号和相关目录
5台服务器上均需创建以下目录,并设置目录的权属:
/opt
/modules -- 安装软件目录
/data -- 存放数据目录
1.11.1 创建 hadoop 用户及组
groupadd hadoop
useradd hadoop -g hadoop
passwd hadoop
1.11.2 创建相关目录并设置目录权限
mkdir -p /opt/modules/
mkdir -p /opt/data/
mkdir -p /opt/data1/
chown -R hadoop:hadoop /opt/modules/
chown -R hadoop:hadoop /opt/rkdata/
chown -R hadoop:hadoop /opt/rkdata1/
chmod -R 775 /opt/modules/
1.12 配置SSH免密码登陆
本操作是指从主节点(nameNode)和备用节点(standbyNameNode)可以免密码登录本机及其他所有节点,并不能从数据节点免密码登录主节点或备用节点。
1.12.1 配置主节点(nameNode)无密码登陆
(1) 检查hadoop用户主目录(/home/hadoop/)下是否有.ssh目录(该目录为隐藏文件夹可通过【ls –a】指令查看),如果有则直接进入第(2)步,否则执行以下执行:
|
$ ssh localhost |
提示是否继续时输入“no”退出,此时即可自动生成该目录。
然后通过以下指令检查:
|
$ cd /home/hadoop/ $ ls -al |
(2) 生成私钥和公钥,执行以下指令:
|
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa |
(3) 把公钥(id_dsa.pub)追加到授权的key中去,执行以下指令:
|
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys |
(4) 更改授权key的权限,执行以下指令:
|
$ chmod go-rwx ~/.ssh/authorized_keys |
1.12.2 将主节点(nameNode)授权key分发到备用节点
将主节点(nameNode)上的authorized_keys文件复制到备用节点(standbyNameNode)上,指令如下:
|
$ scp ~/.ssh/authorized_keys hadoop@standbyNameNode:/home/hadoop/.ssh/ |
复制过程中需要输入备用节点(standbyNameNode)上hadoop用户的密码。
复制成功后,在备用节点(standbyNameNode)的/home/hadoop/.ssh/目录中即会存在authorized_keys文件,请确认该文件已经正确复制。
1.12.3 配置备用节点(standbyNameNode)无密码登陆
(1) 与2.5.1节第(1)部分同样操作。
(2) 生成私钥和公钥,执行以下指令:
|
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa |
(3) 把公钥(id_dsa.pub)追加到授权的key中去,执行以下指令:
|
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys |
(4) 查看授权key文件内容,确认主节点和备用节点的授权信息均在文件中,执行指令:
|
$ more ~/.ssh/authorized_keys |
(5) 更改授权key的权限,执行以下指令:
|
$ chmod go-rwx ~/.ssh/authorized_keys |
1.12.4 将备用节点(standbyNameNode)授权key发回到主节点
(1) 将备用节点(standbyNameNode)上带有两个节点授权信息的authorized_keys文件复制回主节点(nameNode)上,指令如下:
|
$ scp ~/.ssh/authorized_keys hadoop@nameNode:/home/hadoop/.ssh/ |
复制过程中需要输入主节点(nameNode)上hadoop用户的密码。
(2) 复制成功后,查看主节点(nameNode)的/home/hadoop/.ssh/目录中的authorized_keys文件内容,确认主节点和备用节点的授权信息均在文件中,指令如下:
|
$ more ~/.ssh/authorized_keys |
1.12.5 从主节点(nameNode)将授权key分发到各数据节点
将主节点(nameNode)上带有两个节点授权信息的authorized_keys文件复制到3个数据节点上,指令如下:
|
$ scp ~/.ssh/authorized_keys hadoop@dataNode1:/home/hadoop/.ssh/ $ scp ~/.ssh/authorized_keys hadoop@dataNode2:/home/hadoop/.ssh/ $ scp ~/.ssh/authorized_keys hadoop@dataNode3:/home/hadoop/.ssh/ |
复制过程中需要输入各数据节点上hadoop用户的密码。
复制成功后,在3个数据节点(dataNode1、dataNode2、dataNode3)的/home/hadoop/.ssh/目录中即会存在authorized_keys文件,请确认该文件已经正确复制。
1.12.6 检查主节点(nameNode)SSH免密钥登录是否正常
在主节点(nameNode)上以hadoop用户分别连接本机、备用节点和3个数据节点。
注意,第1次连接每个节点(包括本机)时均会出现是否连接的提示,请输入“yes”,但不需要输入密码,此后的每次连接均不会有提示、也不需要密码,可以自动连接。
连接成功后,请输入“exit”退出SSH连接。
(1) 连接本机(使用localhost):
|
$ ssh localhost |
(2) 连接本机(使用主机名nameNode):
|
$ ssh nameNode |
(3) 连接备用节点(standbyNameNode):
|
$ ssh standbyNameNode |
(4) 连接数据节点1(dataNode1):
|
$ ssh dataNode1 |
(5) 连接数据节点2(dataNode2):
|
$ ssh dataNode2 |
(6) 连接数据节点3(dataNode3):
|
$ ssh dataNode3 |
1.12.7检查备用节点(standbyNameNode)SSH免密钥登录是否正常
在备用节点(standbyNameNode)上以hadoop用户分别连接本机、主节点和3个数据节点。
注意,第1次连接每个节点(包括本机)时均会出现是否连接的提示,请输入“yes”,但不需要输入密码,此后的每次连接均不会有提示、也不需要密码,可以自动连接。
连接成功后,请输入“exit”退出SSH连接。
(1) 连接本机(使用localhost):
|
$ ssh localhost |
(2) 连接本机(使用主机名standbyNameNode):
|
$ ssh standbyNameNode |
(3) 连接主节点(nameNode):
|
$ ssh nameNode |
(4) 连接数据节点1(dataNode1):
|
$ ssh dataNode1 |
(5) 连接数据节点2(dataNode2):
|
$ ssh dataNode2 |
(6) 连接数据节点3(dataNode3):
|
$ ssh dataNode3 |
1.13 复制JDK及Hadoop安装文件
5台服务器上均需复制JDK安装文件,Hadoop安装文件只需要复制到主节点(nameNode)上即可。
配套Hadoop 2.7在Linux中安装的jdk版本为1.8.0_101版本,文件名为jdk-8u45-linux-x64.bin。
Hadoop官网下载(hadoop-2.7.3.tar.gz),
解压文件到系统/opt/modules/目录中。
指令如下(以hadoop用户执行):
|
$ jar -zxvf hadoop-2.7.3.tar.gz |
2 JDK安装及配置(所有电脑配置)
2.1 安装JDK
本操作以hadoop用户执行。
(1) 运行JDK安装包(先赋予执行权限)
|
$ cd /opt/modules $ chmod u+x jdk-8u45-linux-x64.bin $ ./jdk-8u45-linux-x64.bin |
此时系统会自动解压该文件完成安装。
2.2 配置环境变量
(1) 以root用户修改文件/etc/profile,指令如下:
|
$ su root # vi /etc/profile |
找到“export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL”,在该语句的上面添加以下语句(注意全部是英文字符,不要随意加空格):
|
export JAVA_HOME=/opt/modules/jdk1.8.0_101 export CLASSPATH=".:/opt/modules/jdk1.8.0_101/lib:/opt/modules/jdk1.8.0_101/jre/lib" pathmunge /opt/modules/jdk1.8.0_101/bin:/opt/modules/jdk1.8.0_101/jre/bin |
(2) 修改完成后保存退出,然后执行以下指令使配置生效(root用户执行):
|
# source /etc/profile |
(3) 执行以下指令查看安装是否成功(查看版本信息):
|
# java -version |
如安装成功,则显示以下内容:
|
java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b06) Java HotSpot(TM) 64-Bit Server VM (build 20.45-b01, mixed mode) |
3 Hadoop集群安装及配置
以下操作,如无特殊说明,均以hadoop用户执行。
3.1 解压缩安装包(主节点)
解压缩Hadoop安装包(先赋予执行权限):
|
$ cd /opt/modules $ chmod -R 755 hadoop-2.7.3.tar.gz $ tar -zxvf hadoop-2.7.3.tar.gz |
3.2 配置环境变量(主节点)
本环境变量配置的文件与JDK安装后配置的文件相同,操作如下:
(1) 以root用户修改文件/etc/profile,指令如下:
|
$ su root # vi /etc/profile |
找到配置JDK环境变量时增加的配置信息,在“pathmunge /opt/modules/ jdk1.8.0_101/bin:/opt/modules/jdk1.8.0_101/jre/bin”语句的上面添加一行语句(注意全部是英文字符,不要随意加空格):
|
export HADOOP_HOME=/opt/modules/hadoop-2.7.3/ |
加完后(包括JDK的配置)的内容如下:
|
export JAVA_HOME=/opt/modules/ jdk1.8.0_101 export CLASSPATH=".:/opt/modules/ jdk1.8.0_101/lib:/opt/modules/ jdk1.8.0_101/jre/lib" export HADOOP_HOME=/opt/modules/hadoop-2.7.3/ pathmunge /opt/modules/ jdk1.8.0_101/bin:/opt/modules/ jdk1.8.0_101/jre/bin |
(2) 修改完成后保存退出,然后执行以下指令使配置生效(root用户执行):
|
# source /etc/profile # exit |
3.3 修改Hadoop配置文件(主节点)
修改Hadoop配置文件的操作均以hadoop用户操作,所有配置文件都在目录【/opt/modules/hadoop-2.7.3/etc/hadoop/】中。
修改/opt/modules/hadoop-2.7.3/etc/hadoop/hadoop-env.sh:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/hadoop-env.sh |
找到“export JAVA_HOME=${JAVA_HOME}”所在行,修改为:
|
export JAVA_HOME=/opt/modules/jdk1.8.0_101 |
3.3.1 mapred-env.sh
修改/opt/modules/hadoop-2.7.3/etc/mapred-env.sh:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/mapred-env.sh |
找到“# export JAVA_HOME=/home/y/libexec/jdk1.6.0/”所在行,修改为:
|
export JAVA_HOME=/opt/modules/jdk1.8.0_101 |
3.3.2 slaves
修改/opt/modules/hadoop-2.7.3/etc/slaves:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/slaves |
找到“localhost”所在行,修改为:
|
DN1 DN2 DN3 |
3.3.3 yarn-env.sh
修改/opt/modules/hadoop-2.7.3/etc/yarn-env.sh:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/yarn-env.sh |
找到“# export JAVA_HOME=/home/y/libexec/jdk1.6.0/”所在行,修改为:
|
export JAVA_HOME=/opt/modules/jdk1.8.0_101 |
3.3.4 core-site.xml
修改/opt/modules/hadoop-2.7.3/etc/core-site.xml:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/core-site.xml |
找到以下内容:
|
<configuration> </configuration> |
在两行中间插入配置信息后内容如下:
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-new</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/rkdata/hadoop/tmp</value> </property> <property> <name>ipc.maximum.data.length</name> <value>134217728</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property>
<property> <name>fs.trash.interval</name> <value>1440</value> </property>
<property> <name>ha.zookeeper.quorum</name> <value>10.64.39.143:2181,10.64.39.144:2181,10.64.39.145:2181</value> </property>
<property> <name>ha.zookeeper.session-timeout.ms</name> <value>5000</value> </property>
</configuration> |
3.3.5 hdfs-site.xml
修改/opt/modules/hadoop-2.7.3/etc/hdfs-site.xml:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/hdfs-site.xml |
找到以下内容:
|
<configuration> </configuration> |
在两行中间插入配置信息后内容如下:
|
<configuration> <property> <name>dfs.nameservices</name> <value>hadoop-new</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.ha.namenodes.hadoop-new</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-new.nn1</name> <value>NN:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-new.nn2</name> <value>SNN:8020</value> </property> <property> <name>dfs.namenode.http-address.hadoop-new.nn1</name> <value>NN:50070</value> </property> <property> <name>dfs.namenode.http-address.hadoop-new.nn2</name> <value>SNN:50070</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///opt/rkdata/hadoop/name</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://DN1:8485;DN2:8485;DN3:8485/hadoop-new</value> </property> <property> <name>dfs.client.failover.proxy.provider.hadoop-new</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProv ider</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///opt/rkdata/hadoop/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/rkdata/hadoop/journal/</value> </property> <property> <name>heartbeat.recheck.interval</name> <value>5000</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>5000</value> </property> </configuration> |
3.3.6 mapred-site.xml
默认没有mapred-site.xml文件,需要从摸板复制一个:
|
$ cp mapred-site.xml.template mapred-site.xml |
然后修改/opt/modules/hadoop-2.7.3/etc/mapred-site.xml:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/mapred-site.xml |
找到以下内容:
|
<configuration> </configuration> |
在两行中间插入配置信息后内容如下:
|
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>SNN:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>SNN:19888</value> </property> </configuration> |
3.3.7 yarn-site.xml
4 修改/opt/modules/hadoop-2.7.3/etc/yarn-site.xml:
|
$ vi /opt/modules/hadoop-2.7.3/etc/hadoop/yarn-site.xml |
5 找到以下内容:
|
<configuration> </configuration> |
6 在两行中间插入配置信息后内容如下:
|
<property> <name>yarn.resourcemanager.hostname</name> <value>SY-0217</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>${yarn.resourcemanager.hostname}:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>${yarn.resourcemanager.hostname}:8030</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>${yarn.resourcemanager.hostname}:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.https.address</name> <value>${yarn.resourcemanager.hostname}:8090</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>${yarn.resourcemanager.hostname}:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>${yarn.resourcemanager.hostname}:8033</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairSchedule r</value> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/opt/rkdata/hadoop/yarn/local</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/tmp/logs</value> </property> </configuration> |
5复制文件到其他节点(主节点)
将hadoop目录复制到其他各节点:
|
scp -r /opt/modules/hadoop-2.7.3 hadoop@SNN:/opt/modules/ scp -r /opt/modules/hadoop-2.7.3 hadoop@NN1:/opt/modules/ scp -r /opt/modules/hadoop-2.7.3 hadoop@NN2:/opt/modules/ scp -r /opt/modules/hadoop-2.7.3 hadoop@NN3:/opt/modules/ |
zookeeper集群安装
1、zookeeper集群部署环境配置 (root用户)
|
序号 |
节点类型 |
主机名 |
IP地址 |
操作系统环境及硬件配置 |
|
1 |
zookeeper |
NN1 |
10.64.39.143 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
|
1 |
zookeeper |
NN2 |
10.64.39.144 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
|
2 |
zookeeper |
NN3 |
10.64.39.145 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
2、官网下载安装包,并解压。
|
wget http://apache.fayea.com/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gztar -zxvf zookeeper-3.4.10.tar.gz |
3、生成配置文件(软件部署在/usr/local)
|
Cp –r zookeeper-3.4.10 /usr/local/zookeeper-3.4.10 cd /usr/local/zookeeper-3.4.10 cp conf/zoo_sample.cfg conf/zoo.cfg vim conf/zoo.cfg |
|
# 心跳间隔 毫秒 tickTime=2000 # 初始化时,允许的超时心跳间隔次数 initLimit=10 # Leader 与 Follower 同步数据允许的超时心跳间隔次数 syncLimit=5 # 监听端口 clientPort=2181 # 数据目录 dataDir=/data/zookeeper/data # 日志目录 dataLogDir=/data/zookeeper/logs # ZooKeeper Server 地址,通信端口、选举端口 server.1=10.64.39.143:2888:3888 server.2=10.64.39.144:2888:3888 server.3=10.64.39.145:2888:3888 |
4、同步程序到其他节点
|
Scp –r /usr/local/zookeeper-3.4.10 root@10.64.39.144: /usr/local/ Scp –r /usr/local/zookeeper-3.4.10 root@10.64.39.145: /usr/local/ |
5、创建目录、生成节点标识文件(所有节点)
|
mkdir -p /data/zookeeper/{data,logs} 生成节点标识文件 shell > echo 1 > /data/zookeeper/data/myid
shell > echo 2 > /data/zookeeper/data/myid
shell > echo 3 > /data/zookeeper/data/myid # 分别在三台服务器上执行,需要跟配置文件中的 server.1\2\3 对应 |
6、启动zookeeper集群并检测
|
启动 ZooKeeper(各个节点去启动)
shell > /usr/local/zookeeper-3.4.10/bin/zkServer.sh start Starting zookeeper ... STARTEDZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg
# 全部成功启动
shell > /usr/local/zookeeper-3.4.10/bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: leader # 查看状态,nn1 为 leader ,其余两台为 follower 5、验证选举 shell > sh bin/zkServer.sh stop # 关闭 datanode03.hadoop 服务器上的 ZooKeeper,原 leader
shell > /usr/local/zookeeper-3.4.10/bin/zkServer.sh status datanode03.hadoop | FAILED | rc=1 >> Error contacting service. It is probably not running.ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg datanode02.hadoop | SUCCESS | rc=0 >> ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: leader datanode01.hadoop | SUCCESS | rc=0 >> ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower
# 再次查看状态,datanode02.hadoop 升级为 leader,datanode01.hadoop 仍为 follower # 注意:三台 ZooKeeper Server 组成的集群,当两台故障时,整个集群失败 ( 剩余的一台无法继续提供服务 ) 6、客户端连接 shell > sh bin/zkCli.sh -server 10.64.39.143:2181, 10.64.39.144:2181, 10.64.39.145:2181 # 注意: # 客户端连接集群,只写一个地址时,当这台 Server 宕机,则客户端连接失败 # 同时写多个地址( 全写 )时,除集群失败外,不影响客户端连接 # 写多个地址时,以 , 分割,, 两边不能有空格 shell > sh bin/zkCli.sh -server 192.168.1.27:2181 [zk: 192.168.1.27:2181(CONNECTED) 0] ls / [zookeeper] # 客户端只连接 1.27,显示只有一个默认的 znode
shell > sh bin/zkCli.sh -server 192.168.1.28:2181 [zk: 192.168.1.28:2181(CONNECTED) 0] ls / [zookeeper] [zk: 192.168.1.28:2181(CONNECTED) 1] create /zk 'mydata' Created /zk [zk: 192.168.1.28:2181(CONNECTED) 2] ls / [zk, zookeeper] [zk: 192.168.1.28:2181(CONNECTED) 3] get /zk mydata cZxid = 0x400000005 ctime = Thu May 04 18:50:06 CST 2017 mZxid = 0x400000005 mtime = Thu May 04 18:50:06 CST 2017 pZxid = 0x400000005 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 6 numChildren = 0
# 新客户端连接 1.28,创建一个 znode
shell > [zk: 192.168.1.27:2181(CONNECTED) 1] ls / [zk, zookeeper] [zk: 192.168.1.27:2181(CONNECTED) 2] get /zk mydata cZxid = 0x400000005 ctime = Thu May 04 18:50:06 CST 2017 mZxid = 0x400000005 mtime = Thu May 04 18:50:06 CST 2017 pZxid = 0x400000005 cversion = 0 dataVersion = 0 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 6 numChildren = 0
# 刚才连接的 1.27,可以显示、获取这个新建的 znode
shell > [zk: 192.168.1.27:2181(CONNECTED) 3] set /zk 'share' cZxid = 0x400000005 ctime = Thu May 04 18:50:06 CST 2017 mZxid = 0x400000006 mtime = Thu May 04 18:57:48 CST 2017 pZxid = 0x400000005 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 5 numChildren = 0
# 给这个 znode 重新设置一个值
shell > [zk: 192.168.1.28:2181(CONNECTED) 4] get /zk share cZxid = 0x400000005 ctime = Thu May 04 18:50:06 CST 2017 mZxid = 0x400000006 mtime = Thu May 04 18:57:48 CST 2017 pZxid = 0x400000005 cversion = 0 dataVersion = 1 aclVersion = 0 ephemeralOwner = 0x0 dataLength = 5 numChildren = 0
# 连接 1.28 的客户端,也获取到了更新后的值 shell > [zk: 192.168.1.28:2181(CONNECTED) 4] delete /zk [zk: 192.168.1.28:2181(CONNECTED) 5] ls / # 删除创建的 znode |
Hadoop集群与zookeeper配置关联并启动(hadoop用户)
1、修改 core-site.xml
|
More /opt/modules/hadoop-2.7.3/etc/hadoop/core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-new</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/rkdata/hadoop/tmp</value> </property> <property> <name>ipc.maximum.data.length</name> <value>134217728</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property>
<property> <name>fs.trash.interval</name> <value>1440</value> </property>
<property> <name>ha.zookeeper.quorum</name> <value>10.64.39.143:2181,10.64.39.144:2181,10.64.39.145:2181</value> </property>
<property> <name>ha.zookeeper.session-timeout.ms</name> <value>5000</value> </property>
</configuration>
# fs.defaultFS 指定的不再是某台 NameNode 的地址,是一个逻辑名称 ( hdfs-site.xml 文件中定义 ) # ha.zookeeper.quorum 指定 ZooKeeper Server 地址 # ha.zookeeper.session-timeout NameNode 与 ZooKeeper Server 超时时间,超时会发生主备切换 |
2、修改hdfs-site.xml
|
More /opt/modules/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.nameservices</name> <value>hadoop-new</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.ha.namenodes.hadoop-new</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-new.nn1</name> <value>NN:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-new.nn2</name> <value>SNN:8020</value> </property> <property> <name>dfs.namenode.http-address.hadoop-new.nn1</name> <value>NN:50070</value> </property> <property> <name>dfs.namenode.http-address.hadoop-new.nn2</name> <value>SNN:50070</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///opt/rkdata/hadoop/name</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://DN1:8485;DN2:8485;DN3:8485/hadoop-new</value> </property> <property> <name>dfs.client.failover.proxy.provider.hadoop-new</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProv ider</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///opt/rkdata/hadoop/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/rkdata/hadoop/journal/</value> </property> <property> <name>heartbeat.recheck.interval</name> <value>5000</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>5000</value> </property> </configuration>
|
3、初始化、启动 NameNode HA
|
1、NN初始化 zkfc shell > su - hadoop
hadoop shell > /opt/modules/hadoop-2.7.3/bin/hdfs zkfc -formatZK
INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/myhdfs in ZK. 2、DN1、DN2、DN3启动 journalnode hadoop shell > /opt/modules/hadoop-2.7.3/sbin/hadoop-daemon.sh start journalnode 3、初始化 namenode,启动 NameNode(hadoop-new集群名称配置文件里面) hadoop shell > /opt/modules/hadoop-2.7.3/bin/hadoop namenode -format hadoop-new
hadoop shell > /opt/modules/hadoop-2.7.3/sbin/hadoop-daemon.sh start namenode 4、backup.hadoop 拷贝元数据、启动 NameNode hadoop shell > /opt/modules/hadoop-2.7.3/bin/hdfs namenode -bootstrapStandby # 从 master.hadoop 拷贝 NameNode 元数据
hadoop shell >/opt/modules/hadoop-2.7.3/sbin/hadoop-daemon.sh start namenode 5、master.hadoop、backup.hadoop 启动 zkfc hadoop shell > /opt/modules/hadoop-2.7.3/sbin/hadoop-daemon.sh start zkfc 6、NN启动 YARN hadoop shell > /opt/modules/hadoop-2.7.3/sbin/start-yarn.sh 6、DN1、DN2、DN3启动 DataNode hadoop shell > /opt/modules/hadoop-2.7.3/sbin/hadoop-daemon.sh start datanode
启动完成后 使用jps 可以看到以下进程 # master.hadoop 8067 NameNode 8230 DFSZKFailoverController # backup.hadoop 8255 NameNode 8541 DFSZKFailoverController # datanode.hadoop 13227 DataNode 13000 NodeManager 12889 JournalNode 七、验证 NameNode HA # 访问 http://10.64.39.140:50070 显示 active # 访问 http://10.64.39.142:50070 显示 standby hadoop shell > kill 8067 # 杀掉 master.hadoop 上的 NameNode
hadoop shell > tail -f /usr/local/hadoop-2.8.0/logs/hadoop-hadoop-zkfc-backup.hadoop.log # backup.hadoop 监控 zkfc 日志
2017-05-22 14:08:50,035 INFO org.apache.hadoop.ha.ZKFailoverController: Trying to make NameNode at backup.hadoop/10.64.39.142:8020 active... 2017-05-22 14:08:50,846 INFO org.apache.hadoop.ha.ZKFailoverController: Successfully transitioned NameNode at backup.hadoop/10.64.39.142:8020 to active state |
4、验证及平常停止启动hadoop

Hadoop用户停止140上执行/opt/modules/hadoop-2.7.3/sbin/stop-all.sh
Hadoop用户启动140上执行/opt/modules/hadoop-2.7.3/sbin/start-all.sh
在143、144、145上执行
Root 停止zookeerper :/usr/local/zookeeper-3.4.10/bin/zkServer.sh stop
Root 启动zookeerper :/usr/local/zookeeper-3.4.10/bin/zkServer.sh start
Hbase集群安装
|
序号 |
节点类型 |
主机名 |
IP地址 |
操作系统环境及硬件配置 |
|
1 |
Masert |
NN |
10.64.39.140 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:60G 划分数据存储容量:100G+2T |
|
2 |
backup |
SNN |
10.64.39.142 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
|
3 |
servers |
DN1 |
10.64.39.143 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:60G 划分数据存储容量:100G+2T |
|
4 |
servers |
DN2 |
10.64.39.144 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
|
5 |
servers |
DN3 |
10.64.39.145 |
OS:REDHAT 6.4 64位 CPU:8CPU 内存:12G 划分数据存储容量:100G+2T+5T |
1、新建用户
|
所有节点 Useradd hbase Echo hbase|passwd –stdin hbase |
2、配置文件hbase-env.sh
|
Vim /opt/hbase-2.0.4/conf/ hbase-env.sh 修改下面两项 export JAVA_HOME=/opt/modules/jdk1.8.0_101/ export HBASE_MANAGES_ZK=false |
3、配置hbase-site.xml
|
Vim /opt/hbase-2.0.4/conf/hbase-site.xml 在configuration标签之间加入如下配置:
<!-- 指定HBase在HDFS上面创建的目录名hbase --> <property> <name>hbase.rootdir</name> <value>hdfs:// hadoop-new/hbase</value> <!-- hadoop-new 是HDFS的集群名称 --> <!-- 开启集群运行方式 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.tmp.dir</name> <value>/opt/hbase-2.0.4/tmp</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>DN1,DN2,DN3</value> </property> |
3、copy hadoop的两个配置到hbase里面
|
Cp /opt/modules/hadoop-2.7.3/etc/hadoop/core-site.xml /opt/hbase-2.0.4/conf/ Cp /opt/modules/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /opt/hbase-2.0.4/conf/ 修改者两个文件的所有者 chown hbase:hbase core-site.xml hdfs-site.xml |
4、修改regionservers 和backup-masters
|
More /opt/hbase-2.0.4/conf/regionservers DN1 DN2 DN3 #相当于hadoop slaves中的dataNode节点
Echo ‘NN’>>/opt/hbase-2.0.4/conf/backup-masters
#相当于hadoop back-maser中的dataNode节点
|
5、配置hbase用户的ssh免密登录
|
140用户hbase ssh-keygen ssh-copy-id hbase@10.64.39.142 ssh-copy-id hbase@10.64.39.143 ssh-copy-id hbase@10.64.39.144 ssh-copy-id hbase@10.64.39.145 ssh hbase@NN ssh hbase@SNN ssh hbase@DN1 ssh hbase@DN2 ssh hbase@DN3 142用户hbase ssh-keygen ssh-copy-id hbase@10.64.39.140 ssh-copy-id hbase@10.64.39.143 ssh-copy-id hbase@10.64.39.144 ssh-copy-id hbase@10.64.39.145 ssh hbase@NN ssh hbase@SNN ssh hbase@DN1 ssh hbase@DN2 ssh hbase@DN3
143用户hbase ssh-keygen ssh-copy-id hbase@10.64.39.140 ssh-copy-id hbase@10.64.39.142 ssh-copy-id hbase@10.64.39.144 ssh-copy-id hbase@10.64.39.145 ssh hbase@NN ssh hbase@SNN ssh hbase@DN1 ssh hbase@DN2 ssh hbase@DN3
|
6、将程序分发到其他节点 root用户
|
scp -r /opt/hbase-2.0.4 root@DN3:/opt/ scp -r /opt/hbase-2.0.4 root@DN2:/opt/ scp -r /opt/hbase-2.0.4 root@DN1:/opt/ scp -r /opt/hbase-2.0.4 root@SNN:/opt/ 其他节点修改所属用户组 chown -R hbase:hbase /opt/hbase-2.0.4 |
7、NN,SNN启动hbase maseter
|
Hbase用户 /opt/hbase-2.0.4/bin/hbase-daemon.sh start master |
8、DN1,DN2,DN3启动regionserver
|
Hbase用户:/opt/hbase-2.0.4/bin/hbase-daemon.sh start regionserver |
9、查看hbase是否在hdfs文件系统创建成功
|
Hadoop用户:/opt/modules/hadoop-2.7.3/bin/hdfs dfs -ls /
|
10、停止hbase服务
|
DN1,DN2,DN3停止regionserver Hbase用户:/opt/hbase-2.0.4/bin/hbase-daemon.sh stop regionserver ps -ef|grep regionserver|grep -v grep|awk '{print $2}'|xargs kill -9 NN,SNN停止hbase maseter Hbase用户 /opt/hbase-2.0.4/bin/hbase-daemon.sh stop master ps -ef|grep hbase-2.0.4|grep -v grep |awk '{print $2}'|xargs kill -9 清空日志 rm -rf /opt/hbase-2.0.4/logs/* |
11、登录NN的hbase进行验证
|
/opt/hbase-2.0.4/bin/hbase shell hbase(main):001:0> status
或者页面登录
|

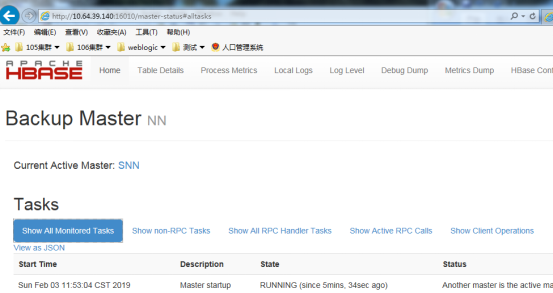
12、平常启动 停止 hbase用户主节点上
|
/opt/hbase-2.0.4/bin/start-hbase.sh /opt/hbase-2.0.4/bin/stop-hbase.sh |
Storm安装
DN1、DN2、DN3部署storm集群,DN1作为Nimubs节点DN2、DN3作为surpervisor节点
1、下载软件
|
wget http://apache.fayea.com/storm/apache-storm-1.2.2/apache-storm-1.2.2.tar.gz |
2、解压软件到指定目录
|
tar –xvf apache-storm-1.2.2.tar.gz –O /usr/local/ |
3、配置storm
More /usr/local/apache-storm-1.2.2/conf/storm.yaml
|
storm.zookeeper.servers: - "DN1" - "DN2" - "DN3" storm.local.dir: "/usr/local/apache-storm-1.2.2/status"
nimbus.seeds: ["DN1"]
supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 注意:以上配置,凡是有冒号的地方,冒号后都要有个空格。 |
4、拷贝storm到集群其他节点。
|
scp -r /usr/local/apache-storm-1.2.2 root@DN3:/usr/local/ |
5、对于两台supervisor node,我们额外开启JMX支持,在配置文件中加入如下配置
Vim /usr/local/apache-storm-1.2.2/conf/storm.yaml 新添加下面一行
|
supervisor.childopts: -verbose:gc -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.port=9998
9998就是用于通过JMX收集supervisior JVM指标的端口。 |
6、所有节点配置环境变量
|
Vim /etc/profile 添加两行 export STORM_HOME=/usr/local/apache-storm-1.2.2 export PATH=$STORM_HOME/bin:$PATH 重载一下环境变量 source /etc/profile |
7、启动storm ui、Nimbus和Supervisor
|
DN1节点启动nimbus和storm ui: nohup storm ui >/dev/null 2>&1 & nohup storm nimbus >/dev/null 2>&1 & |
DN2和DN3主机启动Supervisor节点:
|
nohup storm supervisor >/dev/null 2>&1 & |
8、验证storm
|
http://10.64.39.143:8080/index.html
界面简单介绍: Used slots:使用的worker数。 Free slots:空闲的worker数。 Executors:每个worker的物理线程数。 |
9、停止storm
|
DN1 ps -ef|grep daemon.name=ui|grep -v grep|awk '{print $2}'|xargs kill -9 ps -ef|grep name=nimbus|grep -v grep|awk '{print $2}'|xargs kill -9 DN2和DN3 ps -ef|grep supervisor|grep -v grep|awk '{print $2}'|xargs kill -9 |
Kafka集群安装
DN1、DN2、DN3上面安装kafka
1、下载kafka
|
Apache官网去下载 |
2、解压软件到指定目录
|
tar -zxvf kafka_2.12-2.1.0.tgz -O /opt/kafka/kafka_2.12-2.1.0 |
3、修改配置
|
Mkdir /opt/kafka/kafkalogs/
[root@DN1 config]# more server.properties |grep -v "^#"|grep -v "^$" broker.id=0 port=9092 host.name=DN1 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/opt/kafka/kafkalogs/ num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 message.max.byte=5242880 default.replication.factor=2 replica.fetch.max.bytes=5242880 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=DN1:2181,DN2:2181,DN3:2181 zookeeper.connection.timeout.ms=6000 group.initial.rebalance.delay.ms=0
#broker.id=0 每台服务器的broker.id都不能相同 #host_name 修改 |
4、启动Kafka集群并测试
|
启动:/opt/kafka/kafka_2.12-2.1.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.12-2.1.0/config/server.properties
|
5、测试kafka集群
|
测试:/opt/kafka/kafka_2.12-2.1.0/bin/kafka-topics.sh --create --zookeeper 10.64.39.143:2181 --replication-factor 2 --partitions 1 --topic shuaige #解释 --replication-factor 2 #复制两份 --partitions 1 #创建1个分区 --topic #主题为shuaige '''在一台服务器上创建一个发布者''' #创建一个broker,发布者 /opt/kafka/kafka_2.12-2.1.0/bin/kafka-console-producer.sh --broker-list 10.64.39.143:9092 --topic shuaige
'''在一台服务器上创建一个订阅者''' /opt/kafka/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server 10.64.39.143:9092 --topic shuaige --from-beginning
查看topic /opt/kafka/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper 10.64.39.143:2181
查看topic状态 /opt/kafka/kafka_2.12-2.1.0/bin/kafka-topics.sh --describe --zookeeper 10.64.39.143:2181 --topic shuaige
#下面是显示信息 Topic:ssports PartitionCount:1 ReplicationFactor:2 Configs: Topic: shuaige Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1 #分区为为1 复制因子为2 他的 shuaige的分区为0 #Replicas: 0,1 复制的为0,1 |
整个集群配置启动
Hadoop和zookerper的启动停止
停止zookerper 143\144\145
Root用户:/usr/local/zookeeper-3.4.10/bin/zkServer.sh stop
启动
Root用户:/usr/local/zookeeper-3.4.10/bin/zkServer.sh start
Hadoop
停止140上
Hadoop用户/opt/modules/hadoop-2.7.3/sbin/stop-all.sh
启动140上
Hadoop用户/opt/modules/hadoop-2.7.3/sbin/start-all.sh
单节点命令启动 hadoop用户
/opt/modules/hadoop-2.7.3/sbin/hadoop-daemon.sh start journalnode
/opt/modules/hadoop-2.7.3/sbin/hadoop-daemon.sh start datanode
初始化hadoop
rm /opt/modules/hadoop-2.7.3/logs/* -rf
rm /opt/rkdata/hadoop/data/* -rf
rm /opt/rkdata1/hadoop/data/* -rf
rm /opt/rkdata/hadoop/name/* -rf

Hbase
停止140上
hbase用户:/opt/hbase-2.0.4/bin/stop-hbase.sh
启动140上
hbase用户:/opt/hbase-2.0.4/bin/start-hbase.sh

storm管理
root用户启动storm ui、Nimbus和Supervisor
|
DN1节点启动nimbus和storm ui: nohup storm ui >/dev/null 2>&1 & nohup storm nimbus >/dev/null 2>&1 & |
DN2和DN3主机启动Supervisor节点:
|
nohup storm supervisor >/dev/null 2>&1 & |
验证storm
|
http://10.64.39.143:8080/index.html |
停止storm
|
DN1 ps -ef|grep daemon.name=ui|grep -v grep|awk '{print $2}'|xargs kill -9 ps -ef|grep name=nimbus|grep -v grep|awk '{print $2}'|xargs kill -9 DN2和DN3 ps -ef|grep supervisor|grep -v grep|awk '{print $2}'|xargs kill -9 |
启动Kafka集群
|
DN1、DN2、DN3 用Root用户启动:/opt/kafka/kafka_2.12-2.1.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.12-2.1.0/config/server.properties
|
页面测试
Hadoop
http://10.64.39.140:8088/
hbase
storm
hadoop namenode自动挂掉问题处理记录
more yarn-site.xml 修改
<property>
<name>yarn.resourcemanager.hostname</name>
<value>NN</value> --修改名称
</property>
Hdfs-site.xml中增加配置:
<property>
<name>dfs.qjournal.start-segment.timeout.ms</name>
<value>9000</value>
</property>
<property>
<name>dfs.qjournal.select-input-streams.timout.ms</name>
<value>9000</value>
</property>
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>9000</value>
</property>
Core-site.xml中新增配置
<property>
<name>ipc.client.connect.timeout</name>
<value>9000</value>
</property>
hadoop namenode自动挂掉问题第二次处理记录
资源管理器配置ResourceManager
修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>NN</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<!--
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value>
</property>
-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/rkdata/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.maximum-allocation-mb</name>
<value>8182</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resoruce.memory-mb</name>
<value>8182</value>
</property>
</configuration>
------------------------------------------------------------------------------------
Habse建表报错
/opt/hbase-2.0.4/bin/hbase shell
create 'test','col1' 报错误 master exiting
处理方法:
1、 拷贝jar包到hbase
cp /opt/modules/hadoop-2.7.3/share/hadoop/tools/lib/aws-java-sdk-1.7.4.jar /opt/hbase-2.0.4/lib/
2、 删除zookep上hbase目录
sh /usr/local/zookeeper-3.4.10/bin/zkServer.sh status
/usr/local/zookeeper-3.4.10/bin/zkCli.sh -server DN1:2181(zookeper的主节点)
rmr /hbase
3、 重启hbase
SN1\SN2\SN3 ps -ef|grep regionserver|grep -v grep|awk '{print $2}'|xargs kill -9
SNN\NN ps -ef|grep hbase-2.0.4|grep -v grep |awk '{print $2}'|xargs kill -9
NN /opt/hbase-2.0.4/bin/start-hbase.sh
NN /opt/hbase-2.0.4/bin/stop-hbase.sh
-----------------------------------
kafa --针对大容量消息优化
cat >>/opt/kafka/kafka_2.12-2.1.0/config/producer.properties <<EOF
max.request.size=20971520
buffer.memory=80971520
EOF
/opt/kafka/kafka_2.12-2.1.0/config/server.properties
cat /opt/kafka/kafka_2.12-2.1.0/config/server.properties|grep message.max
sed -i "s/message.max.byte=5242880/message.max.byte=20971520/g" /opt/kafka/kafka_2.12-2.1.0/config/server.properties

 浙公网安备 33010602011771号
浙公网安备 33010602011771号