

Kubernetes之Service
一、Service 的概念与定义
1. Service 的概念
Service 是 Kubernetes 实现微服务架构的核心概念,主要用于提供网络服务。
通过 Service 的定义,可以对客户端应用屏蔽后端 Pod 实例数量及 Pod IP 地址的变化,通过负载均衡策略实现请求到后端 Pod 实例的转发,为客户端应用提供一个稳定的服务访问入口地址。
Service 实现的就是微服务架构中的几个核心功能:全自动的服务注册、服务发现、服务负载均衡等。
2. service 的 YAML 完整定义


二、service 的原理——全自动的服务注册、服务发现、负载均衡
先实践再理论,创建一个 Service 来进行原理讲解。
首先,创建一个三 Pod 实例的 deployment,如下 wjt-deployment:

然后,为该 deployment 创建一个 Service:
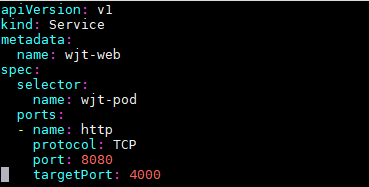
Service 命名为 wjt-web,.spec.selector 指定 Service 对应的后端 Pod 的标签,Service 的 8080 端口对应后端 Pod 的 4000 端口,并命名为 http。

可以看到,创建 Service 的时候,系统会为其分配一个虚拟 IP 地址,同时自动为其创建 Endpoints 对象,指向后端 Pod 服务访问地址。
最后,可以通过系统为 Service 分配的虚拟 IP 地址(ClusterIP)10.107.249.43,以及 YAML 定义的端口号 8080 访问该 Service(后端 Pod 应用对请求路径 /hostname 返回当前 Pod 主机名):

实际上访问的即是 Service 对应的后端 Pod 的应用,且是通过负载均衡的方式进行访问。
1. 服务注册——Service、Endpoints 与 Pod 的关系

创建 Service 的时候,Kubernetes 会自动创建与 Service 关联的 Endpoints 资源对象,用于存储 Service 对应的后端容器应用访问地址列表,即后端 Pod 的“IP:Port”列表。
这是由 Endpoints Controller 完成的,它负责生成和维护所有 Endpoints 对象。Endpoints Controller 会持续监听 Service 和对应的 Pod 副本列表的变化,在 Pod 列表发生变化时,实时更新对应的 Service 的 Endpoints 对象。
在客户端访问 Service 的地址时,Kubernetes 自动完成了将客户端请求转发到后端多个 Endpoint 的负载分发工作。
2. 服务发现
Kubernetes 提供了两种机制供客户端应用以固定的方式获取后端服务的访问地址:环境变量方式和 DNS 方式。(集群内部访问)
(1)环境变量方式
在一个 Pod 运行起来的时候,系统会自动为其容器运行环境注入集群中所有有效 Service 的信息,环境变量命名格式为:{SVCNAME}_SERVICE_...。以 Service wjt-web 为例,在该 Service 创建之后新创建的 Pod (客户端应用)中,可以看到的系统自动设置的环境变量如下:

从而客户端应用就能够根据 Service 相关环境变量的命名规则,从环境变量中获取需要访问的目标服务的地址:

注意:
只有在客户端 Pod 创建之前创建的 Service,其相关信息才会存在于客户端 Pod 的环境变量中。所以,使用环境变量方式进行服务发现时,必须要先创建服务端 Service,再创建客户端 Pod。
(2)DNS 方式
能够感知集群的 DNS 服务器(例如 CoreDNS)会监视 Kubernetes API 中的新 Service, 并为每个 Service 创建一组 DNS 记录。如果在整个集群中都启用了 DNS,则所有 Pod 都应该能够通过 DNS 名称自动解析 Service。
Service 的 DNS 域名格式为:{servicename}.{namespace}.svc.{clusterdomain},其中 clusterdomain 为 Kubernetes 集群设置的域名后缀,默认为 cluster.local,以 Service wjt-web 为例,在客户端应用 Pod 中通过域名进行访问:

若 Service 定义中的端口号设置了名称,则该端口号也会有一个 DNS 域名,在 DNS 服务器中以 SRV 记录的格式保存:_{portname}._{protocol}.{servicename}.{namespace}.svc.{clusterdomain},其值为端口号的值。
对于客户端应用来说,DNS 域名格式的 Service 名称提供的是稳定、不变的访问地址,可以大大简化客户端应用的配置,是 Kubernetes 集群中推荐的使用方式。
3. 负载均衡——流量路由机制
从 Service 虚拟 IP 到后端 Pod 的负载均衡机制,是由每个 Node 上的 kube-proxy 负责实现的。
(1)kube-proxy 的代理模式
<1>userspace 模式
用户空间模式,由 kube-proxy 完成代理的实现,效率最低,不再推荐使用。
<2>iptables 模式
原理:
kube-proxy 监视 Kubernetes 控制平面,获知对 Service 和 EndpointSlice 对象的添加和删除操作。 对于每个 Service,kube-proxy 会添加 Linux Kernel 的 iptables 规则,这些规则捕获流向 Service 的 clusterIP 和 port 的流量, 并将这些流量重定向到 Service 后端集合的其中之一。 对于每个端点,它会添加指向一个特定后端 Pod 的 iptables 规则。
默认情况下,iptables 模式下的 kube-proxy 会随机选择一个后端。
优点:
使用 iptables 处理流量的系统开销较低,因为流量由 Linux netfilter 处理, 无需在用户空间和内核空间之间切换。这种方案也更为可靠。
缺点:
如果 kube-proxy 以 iptables 模式运行,并且它选择的第一个 Pod 没有响应, 那么连接会失败。这与用户空间模式不同: 在后者这种情况下,kube-proxy 会检测到与第一个 Pod 的连接失败, 并会自动用不同的后端 Pod 重试。
此时应该通过为 Pod 设置 readinessprobe(服务可用性健康检查)来保证只有达到 ready 状态的 Endpoint 才会被设置为 Service 的后端 Endpoint。
<3>ipvs 模式
原理:
kube-proxy 监视 Kubernetes Service 和 EndpointSlice, 然后调用 Linux Kernel 的 netlink 接口创建 IPVS 规则, 并定期与 Kubernetes Service 和 EndpointSlice 同步 IPVS 规则。 该控制回路确保 IPVS 状态与期望的状态保持一致。 访问 Service 时,IPVS 会将流量导向到某一个后端 Pod。
优点:
IPVS 代理模式基于 netfilter 回调函数,类似于 iptables 模式, 但它使用哈希表作为底层数据结构,在内核空间中生效。 这意味着 IPVS 模式下的 kube-proxy 比 iptables 模式下的 kube-proxy 重定向流量的延迟更低,同步代理规则时性能也更好。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS 模式支持更多的负载均衡策略:

注意:
要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前确保节点上的 IPVS 可用。
当 kube-proxy 以 IPVS 代理模式启动时,它会验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 会退回到 iptables 代理模式运行。
<4>kernelspace 模式
Windows Server 上的代理模式。
<5>查看当前 kube-proxy 使用的代理模式

(2)会话保持机制
Service 支持通过设置 sessionAffinity 实现基于客户端 IP 的会话保持机制,即首次将某个客户端来源 IP 发起的请求转发到后端的某个 Pod 上,之后从相同的客户端 IP 发起的请求都将被转发到相同的后端 Pod 上,同时还可以设置会话保持的最长时间,示例如下:


可以看到,虽然 Service 对应的后端 Pod 有三个副本,但客户端请求了好几次,响应的都是同一个 Pod,按照配置,这个会话将保持 3600s,也就是 1 小时以后才会重置客户端 IP 的保持规则,按照负载均衡策略将请求路由给下一个 Pod,然后会话再次保持 3600s,以此类推。
(3)基于拓扑感知的服务路由机制(EndpointSlices)
随着 Kubernetes 集群规模的扩大及 Service 数量的增加,特别是 Service 后端 Endpoint 数量的增加,每个 kube-proxy 需要维护的负载分发规则(例如 iptables 规则或 ipvs 规则)的数量也会急剧增加,导致后续对 Service 后端 Endpoint 的添加、删除等更新操作的成本急剧上升,尤其是在 Deployment 不断进行滚动升级操作的情况下,网络带宽浪费巨大,而且对 Master 的冲击非常大,会影响 Kubernetes 集群的整体性能。
Kubernetes 从 1.16 版本开始引入端点分片(Endpoint Slices)机制,包括一个新的 EndpointSlice 资源对象和一个新的 EndpointSlice 控制器。EndpointSlice 通过对 Endpoint 进行分片管理来实现降低 Master 和各 Node 之间的网络传输数据量及提高整体性能的目标(例如,对于 Deployment 的滚动升级,可以实现仅更新部分 Node 上的 Endpoint 信息)。
EndpointSlice 根据 Endpoint 所在 Node 的拓扑信息进行分片管理:

另外,端点分片机制还能与服务拓扑(Service Topology)机制共同实现基于 Node 拓扑的流量路由。
<1>端点分片(Endpoint Slices)
Kubernetes 从 1.19 版本开始默认开启该特性,创建 Service 时,除了 Endpoints,系统还会自动创建一个 EndpointSlice:

默认情况下,在由 EndpointSlice 控制器创建的 EndpointSlice 中最多包含 100 个 Endpoint,如需修改,可通过 kube-controller-manager 服务的启动参数 --max-endpoints-per-slice 设置,但上限不能超过 1000。
EndpointSlice 通过标签 kubernetes.io/service-name 与 Service 进行关联,通过标签 endpointslice.kubernetes.io/managed-by 设置管理其控制器的名称(多个实体可以管理 EndpointSlice,但一个 EndpointSlice 只能被一个实体管理)。
Kubernetes 控制平面会自动完成将 Endpoints 资源复制为 EndpointSlice 资源的操作。
一个 Endpoints 可能存在于多个 EndpointSlice 中(例如,当一个 Endpoints 资源同时存在多种地址类型时,会被复制为多个 EndpointSlice)。
当需要更新多个 EndpointSlice 的时候,Kubernetes 会优先考虑创建一个新的 EndpointSlice(从 Master 发送到每个 kube-proxy 的数据量更少)。
<2>服务拓扑(Service Topology)
Kubernetes 从 1.17 版本开始引入了服务拓扑机制,目标是实现基于 Node 拓扑的流量路由,例如,将发送到某个 Service 的流量优先路由到与客户端相同 Node 的 Endpoints 上。
启用服务拓扑机制时首先需要开启端点切片机制,由端点切片机制中每个 Endpoints 的“Topology”拓扑信息提供数据支持,然后就可以在 Service 资源对象上通过定义 topologyKeys 字段来控制到 Service 的流量路由了。
topologyKeys 字段设置的是一组 Node 标签列表,按顺序匹配 Node 完成流量的路由转发,流量会被转发到标签匹配成功的 Node 上。
三、service 的类型、作用与实践
1. Service 的类型
Service 有四种类型,可通过 .spec.type 字段进行设置,分别为:ClusterIP、NodePort、LoadBalancer、ExternalName。
(1)ClusterIP:只能在集群内部通过 clusterIP:port 访问
.spec.type 不设置时默认就是“ClusterIP”,clusterIP 不设置时系统会自动为其分配一个虚拟 IP,手动设置时需要确保该 IP 在 Kubernetes 集群设置的 ClusterIP 地址范围内。
Service 创建完成以后可以在集群内通过 clusterIP:port 进行访问,但集群外部无法访问到该 Service。


(2)NodePort:可在集群外部通过 NodeIP:nodePort 访问
NodePort 类型将 Service 的端口号映射到每个 Node 的一个端口号上,这样集群中的任意 Node 都可以作为 Service 的访问入口。


默认情况下,系统还是为 Service 分配了一个虚拟 IP,可在集群内通过 clusterIP:port 访问服务,也可以在集群外通过任意 Node 进行访问:NodeIP:nodePort。
(3)LoadBalancer:可在集群外通过负载均衡器的 IP 和 Service 的端口号访问
LoadBalancer 类型的 Service 通常在公有云环境中使用,可以将 Service 映射到某个负载均衡器的 IP 地址上,集群外的客户端可通过负载均衡器的 IP 和 Service 的端口号访问 Service,负载均衡器可以直接将流量转发到后端 Pod 上,而无须再通过 kube-proxy 进行转发,负载均衡机制也是依赖于公有云服务商的具体实现。

(4)ExternalName:可将集群外服务定义为集群内服务,然后在集群内通过 Service 域名进行访问
ExternalName 类型用于将集群外的服务定义为 Kubernetes 集群内的 Service,并且通过 externalName 字段指定外部服务的地址,可以使用域名或 IP。集群内的客户端应用访问 Service 的域名时,系统将自动指向 externalName 字段设置的集群外部的服务地址。


没有后端 Pod,所以没有设置 .spec.selector,所以也就不会生成 endpoints。
这里创建的 Service wjt-service-externalname,其 external name 指向另一个 Service wjt-service-clusterip 的域名,所以访问前者域名的时候相当于访问后者的服务:

也可将 external name 指向集群外服务域名。
注意:
ExternalName 的服务接受 IPv4 地址字符串,但将该字符串视为由数字组成的 DNS 名称, 而不是 IP 地址(然而,互联网不允许在 DNS 中使用此类名称)。 类似于 IPv4 地址的外部名称无法被 DNS 服务器解析。
2. 将外部服务定义为 Service
除了创建 ExternalName 类型的 Service,还可以通过直接创建 endpoints 并将其指向集群外部服务地址来将外部服务定义为 Service。


这里不设置 .spec.selector,而是手动创建 endpoints,并指定外部服务的地址。
接下来可通过 Service ClusterIP 访问到外部服务:

与直接访问外部服务是一样的效果!
参考:
《Kubernetes 权威指南第 5 版》
分类:
Kubernetes


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!